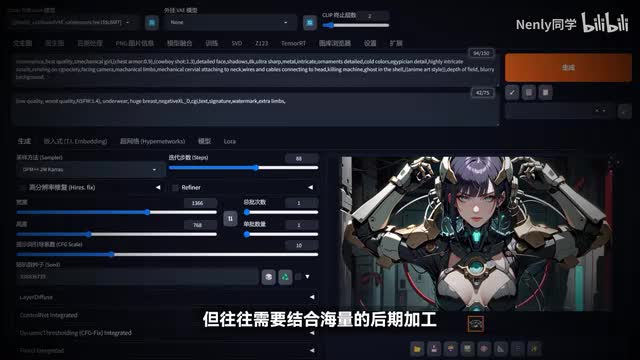
如果要用一张图片来代表二零二四年a i图像生成的最新突破,我会选它。一个普通的玻璃瓶,但如果我告诉你它是透明的呢?一直以来,ai绘图在一些传统创意行业工作者的眼里可能会有点鸡肋,原因在于它的生成产物是一张单一的图片,但在平面设计、动画制作、特效后期等领域投入生产使用的图像素材一般都是分图层的,从最基本的主要元素和背景,再到人物的服饰、四肢乃至毛发等细节,都需要分层作为设计加工乃至动效制作的基础。所以,即便stable division生成的图片非常精致细腻,但往往需要结合海量的后期加工、抠图、补全、重绘,把它拆解成一个个拥有透明通道的零件才能投入使用。但像这样的人工智能在以后或许都不需要了。因为在今年的三月份,一个叫做lair division的技术横空出世,再次引爆了ai绘画的圈子,它的作者是斯坦福的张博士,举世闻名的control net项目开发者。一句话概括这个layer division的作用,它可以在stable division里生成,拥有透明背景且质量极高的编辑图片。和一些借助主体识别实现智能抠图的工具不同,它在生成阶段就直接将透明通道的信息加入了运算。

因此你可以生成像这样清晰的轮廓边缘根根分明的毛发细节,乃至像这样半透明的材质和光效,免去繁琐的构图和加工过程。还可以根据前景内容补充背景,背景内容生成前景,一次性生成像这样多层的a i绘图作品。这种带有透明通道的a i分层素材可以被广泛应用到诸多平面设计、游戏制作等各种场景里。你想知道这个工具怎么用吗?在接下来的十分钟里,你将通过这个视频开启lady fusion从安装到使用的全流程教程。内容很充实,我猜你肯定不止要看一遍,所以建议先点个收藏再开始接下来的学习。准备好了吗?我们开始今天的lady fusion探索之旅吧。目前你可以通过张博士开发的stable division forge u i里的扩展插件,轻松快捷的用上later diffusion。
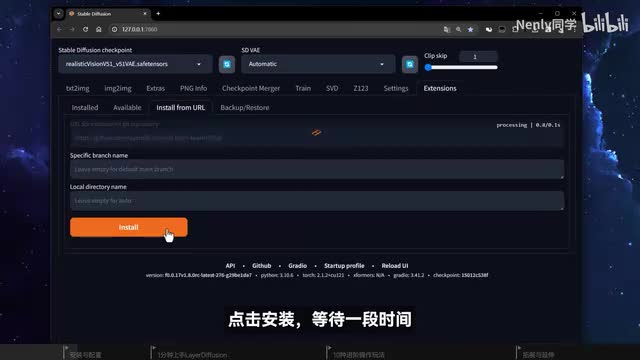
以下是一个完整的安装方式,如果你倾向于自己完成所有安装环节,可以在官方项目页的release板块下载,由作者提供这个最新程序包,将它解压到电脑上一个空文件夹里。第一次运行前,需要先点击update进行更新,然后点击run即可启动程序。在forge u i的扩展板块里选择通过网址安装,输入later division扩展的存储库地址,点击安装,等待一段时间看到安装成功的提示以后,重启u i即可。如果安装顺利完成,在文生图板块下方你就会看到一个layer defuse的可折叠标签了。需要说明的一点是,现阶段later diffusion还不兼容s b web u i。所以如果你在自己的web u i上尝试,应该会碰到一些障碍。如果你在之前从来没有使用过四ui和stable division,又或者觉得自己安装太麻烦。
我也帮你打包整理了一份forge ui加了defuse的全套整合包,并配置好了所有模型文件下载方式在三联按钮下方的这个视频简介区里,有需要可以自行查收。要是能帮忙点亮这几个小按钮就更好了。在开始前还有一个必须讨论的问题。layer diffusion有配置上的需求吗?其实lair division的模型是以一种类似laura的形式注入主模型中使用的,并不会带来额外的使用负担,所以利用layer的diffusion产出透明编辑图片的配置需求和常规绘图大致是看齐的。最早的division放出的模型只有基于s d excel模型训练的excel版,使用它搭配excel的微调模型,绘制一百零二四分辨率图片需要约十二gb左右显存,开启的decision以后会稍微增加一点点。在较高的分辨率下要获得流畅的生成体验,可能对显卡的核心性能也有一定的要求。正巧华硕最近就给我寄来了一块新上市的pro arch创意过多r t x四零八零super显卡。

它拥有高达十六g b的显存空间,可以支持我们满血全速驱动excel模型生成作画专用的cancel核心可以提供高达八百三十六t o p s的强大ai算力,可以帮助你轻松完成各型的ai绘画应用。如果你的配置低于这条推荐线,那也并非完全无法使用,只是需要承担一定的报显存降速的风险。但得益于forge u i的优化使用,低显存设备绘制是相较web u i应该是更快的。另外你也可以考虑转用基于s d一点五的大模型,配合一点五版本的各种。就是模型使用。但相较于excel版本的模型,一点五版本在精度与对语义的理解能力上都略逊一筹。如果你的配置充足,我会建议你优先使用excel模型来进行生成。
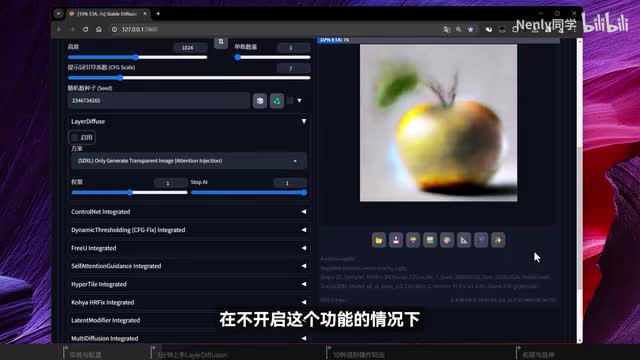
那这个layer division到底要怎么用呢?它的使用方法相当简单,我敢保证你一分钟就能学会将这个lady feel标签展开。里面的参数特别简洁,我们可以通过启用控制功能的开关,先画点简单的东西吧。比如一个苹果在上方的提示字框里用英语描述你想要生成的内容,随后在下面将生成的尺寸设置为幺零二四乘幺零二四,然后点击右侧的生成按钮,在不开启这个功能的情况下,我们画出来的是一张有背景的图片。此时勾选开启later defuse的功能,并确保方案选中的是这个只生成透明背景图片。点击生成出来的还是一个苹果,但背景变成了像这样的灰白格子。有过一些图像处理软件经验的朋友会很亲切,因为它代表的就是透明的背景。但这张有灰白格子的只是预览图,它一共会生成两张图片。
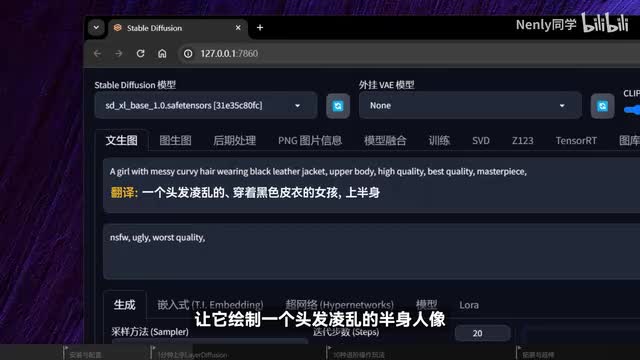
第二张才是真正的透明背景p n g。我们打开它,点一下右上角的下载按钮,就可以把它保存到本地了。它是不是真的透明呢?把它导入到photoshop里看,确实如此,叶片的边缘都被抠的清清楚楚,这就是一个现成可用的p n g素材了。你可能会觉得这个苹果太简单了,自己拿p s抠不也就是分分钟的事情吗?那我们来给lady fusion上点强度,通过提示词让它绘制一个头发凌乱的半身人像,并适当调大尺寸看,生成出来的人像也是透明背景的,不光身体的轮廓清晰,连每一根头发丝的间隙都被抠得清清楚楚。不仅如此,我们还可以换一个二次元风格的大模型,生成出来的动漫风格人像也是透明背景的,同样非常干净细腻。即便如此,这样生成的产物好像和直接扣也没什么两样。换句话说,它再复杂也是花点时间可以抠出来的。

但我们一开始就说了,later division和这些传统的抠图工具有着本质的不同。所以它不光可以实现像这样轮廓清晰的透明背景图片,还能生成半透明的素材,修改提示词,让它生成一个透明的玻璃瓶。看它不仅仅在边缘上和背景是区分开的,连内部都能准确的呈现出玻璃的半透明质感。把它保存下来叠放在另一张图片上,你能更清晰的感受到这种半透明的存在。在诸如p s一类的传统编辑软件里,我们需要通过通道混合模式等高级手段才能实现这种程度的抠取。但现在只需要一键就可以生成了,质量还相当之高。而玻璃仅仅是其中的冰山一角,它能处理的东西还有很多。
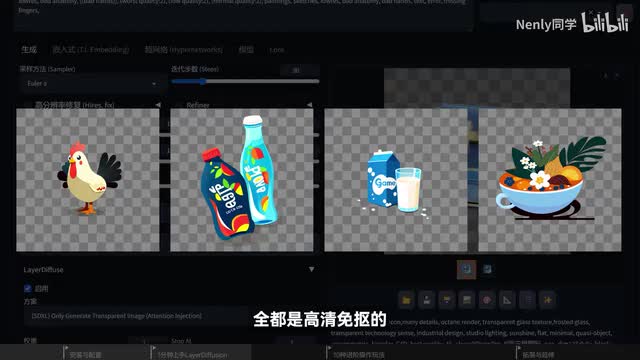
例如我们可以让它生成一本老旧的火焰魔法书,并加上一些诸如发光的光晕、粒子特效一类的提示词,它也可以把这些部分全部栩栩如生地还原出来。现在你知道标题里的抠图已成过去式,并不是在吹牛了吧?和开始分析的一样,因为它是以一种类似laura的形式注入到主模型里参与生成的,所以它可以和任意一个大模型搭配使用,你可以用它生成各种风格的设计素材。从这样的三弟科技风格icon再到扁平风格的插画,全都是高清免抠的,一步到位完成生成。从另一个角度切入,你还可以利用它批量生成游戏角色的原画设计。虽然在later division出来之前就已经有很多专业的工作者们在这样做,但现在一定更加轻松了。而且在这种纯透明背景的产物上,做各种编辑或者是动态化操作都会更加方便。结合我们接下来会讲到的分层绘制的技巧,还可以赋予人物背景之间更灵活的生成关系,还挺像那么回事的对吧?这些新技术使用起来一点也不困难,唯一的门槛或许就是设备配置了。

传统的平面设计、动画、视效等领域对显卡的要求不算很高,但随着a i g c技术的普及,gpu正逐渐成为创意工作者们的生产力新来源。比如支持了本期教程制作的华硕显卡,他们的pro二创意国度产品线最新上市的r t x四零super系列gpu就可以为诸如layer division一类的最新ai图像制作项目提供源源不断的动力。根据实际测试。这张pro二四零八零super运行excel模型,生成单张类似的高清透明背景素材只需要不到五秒,在tsr t的加速下,产出常规图片的速度更是可以达到每分钟将近一百张的水平。不同于一般的电竞游戏显卡,pro二产品线面向的是专业的艺术家与创作者。外观简约但高级,没有抢眼的r g b灯光,但每个细节里都藏着精致的设计感。升级的轴流风扇比上一代多出了百分之二十一的进风量,保证了更低的温度和更高的性能。

配合华硕自研的g p u二x三智能控制系统,可以实现零分贝的超安静运行,更有利于我们在工作过程中的专注。更小的体积也可以让它适配更多的机箱设计,如果有条件,你还可以考虑拿它搭配pro二级同系列的主板机箱显示器。拿这样一套设备进行创作,两个字优雅。当然虽然说是面向专业创作者的显卡,但它在游戏等方面的性能也是完全不落后的。诸如大力水手r t x视频超分辨率等a i增强技术,早就被引入了游戏和直播领域。在pro二级显卡上同样可以帮助你获得更好的游戏娱乐体验。如果只是能生成透明图片,那的fusion并没有啥特别的。
不过展开这个方案菜单,你可以看到作者为你提供的高达十种不同的玩法。很多朋友在第一次看到这个列表时是比较迷茫的,让我来帮你梳理一下他们到底是一个什么样的关系吧。这十种玩法对应了不同版本底模下的一些不同处理方式,区别主要在于运行的learning fusion模型。在你第一次运行其中一个方案时,后台会自动开始为你下载对应的模型文件,所以等一会儿是正常的,如果你下载失败了,可以在简介里的网盘内找到对应的模型文件,手动放置进对应位置以后再来运行,就可以正常运转了。我们先从这些标有s d excel的excel版方案开始讲起。第一个玩法是根据前景补全背景。首先有几个基本概念是需要讲明白的。
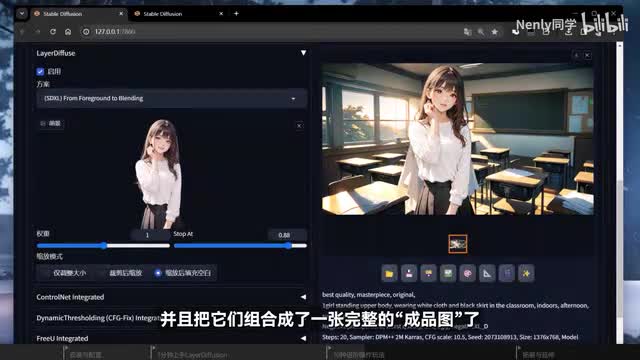
在这些玩法里我们会将一张图片定义为前景和背景的部分,以正常有背景的人物伴生绘画为例,那前景就是人物,背景就是后面的风景,而它们合在一起则是被称之为blending及融合的成品。在这个玩法里,下面会多出一个输入前景图片的小窗口,这个时候你可以导入一张透明底的png图片,随后和刚才一样,在上面的提示词框里,根据图片形象和预想的完整画面内容撰写提示词。点击生成看图片,就根据这个人物生成了一张与之匹配的背景,并且把它们组合成了一张完整的成品图了。但我猜你应该更想要的是一张不融合的单独的背景,对吧?如果是这样,那你可以再通过这种方式生成了一张融合图以后,切换到这个前景加融合图生成背景的模式。此时下面会再多出一个输入框来,左边输入前景,右边输入融合图,我们就可以将刚刚生成的这张融合图直接拖到右边框里。因为我们要生成的是背景,所以你需要在提示词里去掉关于人的描述,或者加入no humans等限定词。在你生成看,我们就把这张融合图里的背景给提取出来了。
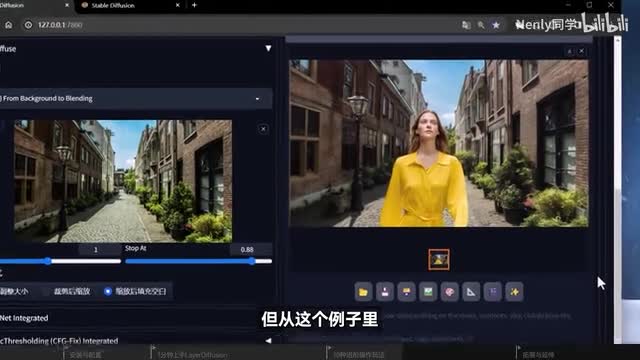
我会建议你在每一步操作后都保存一个成品,这样就可以同时得到这张图片的前景层和背景图,从而能够把它们导入到其他地方,做你想做的任何事情了。这是根据前景来补充背景。那倒过来根据背景补充前景可不可以呢?也可以,这就是我们要讲的第二种玩法。同样你可以向它输入一张背景图片,然后用提示词控制了refusing往这张图片上加东西看一个走在街上的人就生成出来了。但从这个例子里你应该能看出这个功能的短板所在,它对空间关系比例大小的理解在现阶段可能还不太够,在作者提供的一些示例里也提到,它会部分影响画面的色彩和细节,所以这个玩法我并不是很常用。要实现类似的效果,不如直接按最开始的方法生成透明底内容,再把它合成进画面里。而它同样也有一种辨识,就是在已知背景和融合结果的情况下,智能的帮助我们扣出前景,和用刚刚完全相同的例子做示范。

只不过这下导入的就是背景图和融合图片。看生成完毕,它就会把前景的部分智能识别并抠取出来了。标有仅透明的选项,对应的就是我们一开始示范的那个直接生成透明的p n g的玩法。你可能会留意到它也有两个版本,它们的区别在于训练模型的时候,一个是针对常规注意力层,而另一个是针对卷积层的。根据作者的说明,卷积版本理论上可以更好的理解提示词语义,但会对原模型的风格造成较大影响。而实践中注意力层的版本表现的会更好,所以多数时候用这个就可以了。以上所有模型的玩法都是基于s d excel训练出来的,而上方几个标有s d一点五的方案则是基于s d一点五的模型训练出来的。
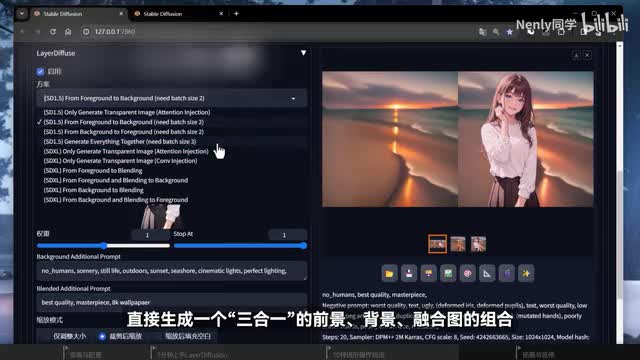
如果启用这几种方案,记得在左上角的模型选择菜单这里切换一个sd一点五版本的大模型。最基本的景透明模式和x l下一样,直接出透明底图片。而里面的从前景到背景从背景到前景玩法也和后半段我们讲的这两种大同小异。但这里多出了一个everything together全部一起生成的模式,它对应的就是later division的终极形态,直接生成一个三合一的前景背景融合图的组合。在切换到这个模式以后,有两个需要注意的地方,一是你必须在生成参数这里将单批数量开到三,或者是设置为三的倍数,因为它一次就会输出三张图。二是在下面的菜单这里会进一步出现三个额外的prom输入框,分别对应前景、背景和整体的画面描述。前面我们也说了,一点五模型相较excel在语义理解上是偏弱的。
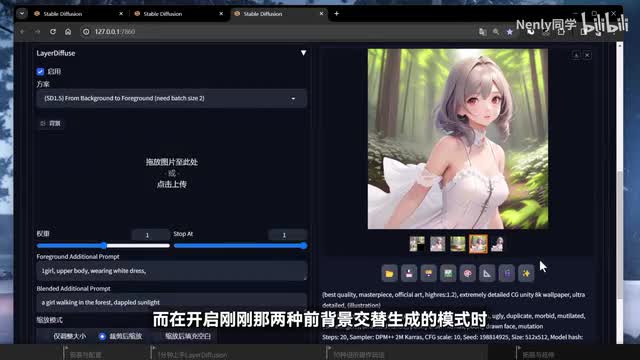
所以我们需要这些提示词来帮助我们更好的引导前景和背景的分别生成。你可以在上方提示词框内只保留最基本的质量提示词,然后把描述人场景的内容都放在这里,并且最下方整体的描述生成的情境,这样就可以一步到位的分层输出完整的前景背景和融合图了。一般而言,这种模式应该可以覆盖你在一点五版本模型下使用lady fusion的所有需求。而在开启刚刚那两种前背景交替生成的模式时,也会有额外的提示词框给你使用。利用的方式基本是一致的。那excel版为什么没有这种三合一的完整模型呢?根据作者的说明,其实也在研制了,但因为资源占用太多,可能还需要一些优化的空间。如果你感觉这个项目对你确实有所帮助,也可以到github上去给他点个star,来支持作者开发更多使用的功能吧。
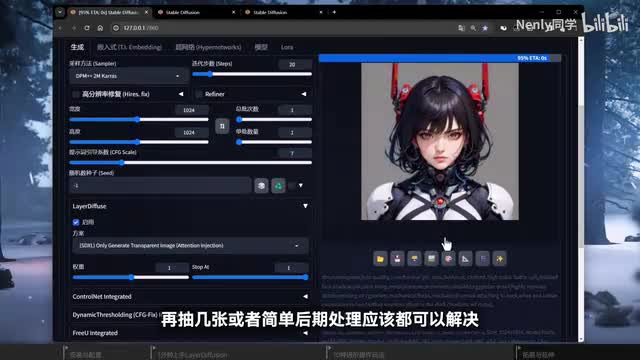
little diffusion其实并不是模型,根据我的一些实践,它几乎可以和任何风格的一点五excel模型搭配使用,产出的效果都非常不错。但偶尔对于透明区域的识别会有小瑕疵,有时它也会出现对提示词理解不准确,以及生成对象位置比例不合理的情况。也就是说a i的抽改性也是存在的。碰到这些情况再抽几张或者简单后期处理应该都可以解决。另外希望提高生成素材质量的话,还可以配合开启高清修复,用法和常规绘图时是完全一样的,它和大部分laura理论上也是可以混合使用的。我做了一些测试,无论是一点五还是excel的lara表现都不错。一部分朋友最关心的大概是control和它的兼容性。
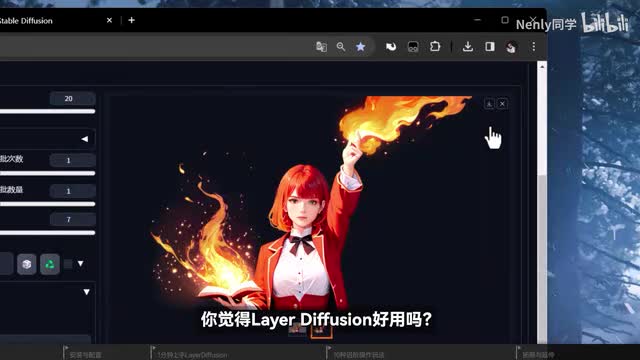
这次是好消息,可以用watch u i已经自带了contact插件,只需要下载对应的更穿戴模型和预处理器就可以使用了。我在整合的版本里已经附上了open pose的模型,你可以体验一下利用它控制生成角色的具体姿势动作的感觉。它进一步提高了layd fusion的可控性,很多你的想法在control net的加持下,应该都可以和这fusion产生不错的化学反应。不过嘛,有一个值得注意的点,现阶段输出的透明底png似乎不会直接被保存到输出文件夹里,所以如果你生成出了不错的作品,记得手动点击下载按钮保存下来,不然就只剩下这个灰白格子版的预览图了。看完这期教程,你觉得lady fusion好用吗?有的人可能会说了,他能做到的事情,我们靠猛男重汇,靠三m一类的智能抠图手段不也能做到吗?我们暂且不了手段的麻烦程度和精度的高下之分,雷奥迪分享给我的最大惊喜其实不在于它现阶段可以做到什么,而是它的未来。我们用现在的模型已经可以做到主体和背景分离了,那以后能不能更加细致,具体到每一个肢体关节细分元素都分出层来。还有现在已经可以画半透明了,那以后能不能把生成产物和更多环节打通一步,生成可以驱动的三弟或者live二d模型,或者和n v d等视频生成的模型结合,去生成生动连贯同时又有透明背景的动态素材。
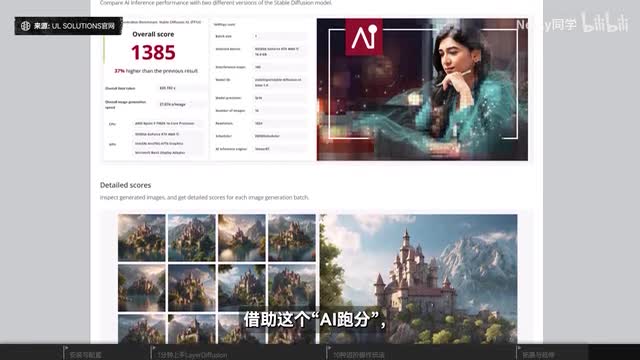
分层是一些可操作性的基础,而这条道路上的第一步已经有later d fusion迈出去了。我知道像未来可期这样的话可能显得有些飘渺了,但随着时代发展和技术的进步,ai已经深入了每一位创意工作者的日常作业流程中,并逐渐被社会所认可,成为一种生产力视频的权威硬件评测开发商三d mark的研发公司ul solutions,目前也在他们的u l proceum基准测试套件中加入了a i图像生成的预测基准,将g p u的a i性能量化成。一项指标。借助这个a i跑分,我们就可以客观的去对比不同设备在a i g c方面的性能差异了。值得一提的是,因为有tensor r t引擎的加速,四零系的g p u在这个跑分的排名里占据了非常大的优势。这套由英伟达官方开发的技术方案,可以让你的显卡生成图片的速度提高至多百分之二百。经过了许多次改进迭代,目前它已经能够支持像control一类的精确控制生成以及s v d这样的本地视频生成模型,还能够加速诸如达芬奇top as photo a i等在本地运行的热门创意应用。

u l公司的观点是,a i有可能成为这十年来进入主流的最重要的新技术之一。像lad fusion ai绘图这样在平面领域的应用很可能只是一个小小的开端,诸如大语言模型、ai生成、声音、视频匹配、嘴型动态的技术都在不断迭代完善,到那时候,ladies sion的应用空间也必将更为广阔。以上就是本期教程的所有内容了,如果这期的讲解对你有所帮助,请别忘了给这个视频一键三连,这对我创作接下来的视频内容有很大的帮助。这里是哪里?感谢看到最后,那我们下期见,拜拜。




