
从去年开始,国内外就已经涌现出了一批积极尝鲜的a i视频艺术家。他们使用各种a i g c工具创作出了许多引人瞩目的作品。而且最近我也看到了很多用ai做出来的非常有趣的视频,让我这个每天都接触a i的人都会觉得眼前一亮。偶尔我也会翻翻评论,发现有时候大家就会问,这是a i做出来的吗?求网站,求软件,我花钱谁帮我做一下?为了帮大家少走弯路,我想在这期视频里做一个小盘点,截止到目前,有哪些a i视频的创作方法,他们实现的效果是什么样的?结合我自己的a i g c领域的探索经验,我从各种不同方向里面整理出了三十个最热门的ai视频制作工具,涵盖视频的生成、转会以及照片、跳舞、数字人等热门的应用,来方便你进一步探索并运用它们。顺便附上了所有工具的在线平台、官网或者下载地址,不用评论私信,直接在视频下面你就可以找到。你可以先给这个视频点个收藏,如果看完了以后觉得真的有用,再回来一键三连支持一下。

ok我们一起开启今天这条ai视频入门之路吧。在今天a i视频生存有很多种不同的技术路线,能实现的效果也各不相。但是,如果我们从输入信息的模态出发来定义,目前ai视频生成包含了standard,最主要的实现路径分别是文章视频、图像视频以及视频上视频。输入一段文字,ai就能根据你的文字描述为你生成一个符合要求的视频,这就是人生视频ai视频制作最基础的一种形态,它可以生成几乎任何一种视频,比如像这样的静物、风景,或是包含具体人和物的,现实存在的、不存在的、真实世界风格的,还有各种动画艺术风格的。你可以把ai视频生成模型看作一个库存无限大的视频素材库,在各类视频的生产环节里均可以得到广泛的应用。比如旁白需要配画面,过度需要填空镜。

以往可能需要费时费力的在互联网上搜索很久,但现在只需要用文字和a i把需求交代清楚,让他生一个就ok了。不过纹身视频有一个非常致命的问题,它的生成是几乎完全随机的。因此现阶段的纹身视频只能用于生产一些不包含具体形象,要求也不那么高的空镜片段,这显然是没办法用于真正的影视作品创作的。怎么办呢?为了进一步增强视频生成的可塑性,图像视频就应运而生了。输入一张初始图片a i就会把它当成视频的第一帧,推倒这张图片里的内容。接下来一段时间内会发生的变化,从而让这张图片动起来生成一个视频。
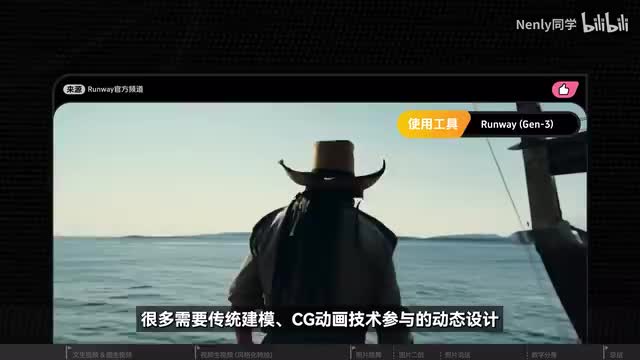
这样做的好处是视频里所有的人物镜都会和上传这张图片保持一定程度上的相似。我们就可以通过图片更好地把握视频的内容走向。它的出现将做视频的门槛和做图片一定程度上拉到了同一水平线。因此它也成为了目前被应用的最为广泛的。ai视频生成技术之一,很多需要传统建模c g动画技术参与的动态设计,如今就可以从一张静态的图片生成类似的效果,大大降低了工作量。此外你还可以先绘制若干个静态的分镜,在里面定义视频的构图和包含的元素,再通过图片视频让它动起来,最后再把所有片段集集到一起,组成一个成片。

这就是目前大部分a i短片都在采纳的一种创作方式。只要你有创意,你就能导演出任何你能想象到的视频、文声视频和图生视频的模型产品化程度的相对较高,所以你可以非常轻松的体验到a i视频生成的乐趣。在大家能用到的视频生成模型里,目前位于第一梯队的包括人为的js num ai的dream machine,快手团队推出的可怜a i字节旗下的dream a等等。每一家的产品都有一些自己的特色。例如runway推出了可以用于精确控制运动形态的运动笔刷,相机控制等工具。再比如dream machine和dreaming呢都推出了首尾帧的图片控制方式。

这个领域也有一些模型的权重是开源的,比如路程科技的open sora,智浦科技的质朴、轻盈和stability,ai的table video decision,有编程开发能力的个人或团队可以利用它们做更多工作。因为这个领域特别卷,所以可预期的今年一定还会有更优秀的模型和应用推出,并进入公共视野。如果你感兴趣,也可以顺带给我点个关注,蹲一蹲后续的更新。然而必须提到一点是,即便是图像视频,在可控性方面仍然是不足的。我们虽然给出了开头的一个图片,但后续的运动效果是几乎无法去定义的,只能用ai自己来决定,同时可以推导运动的程度也是有限的,主体运动和场景变化的幅度越大,画面就越容易变形。所以目前大多数视频生成模型只能生成时长非常有限且运动幅度不大的视频片段,如果我们想要借助ai创作更长、更灵活且更受控制的视频,往往就会转向接下来要提到的这一种创作方式了。

如果我们能为ai提供一整段视频作为参考,那它可以根据这个视频生成一个构图、形象都相近,但风格完全不同的新视频来,这就是所谓的视频声视频了。它还有另一个称呼叫做视频的转会,因为它使用到的核心技术其实是ai绘画,在做转会的时候,视频会被拆成一个个单独的身,输入到诸如stability fusion一类的ai绘图模型里,逐帧重绘,借助多种多样的ai绘图模型,你可以把这个视频重塑成几乎任何一种风格。所以我们也把这种操作叫做视频的风格迁移。从效果上看,它就像是给原视频加了一个风格滤镜,但比起传统的视频效果和调色滤镜,它的调整幅度更大,效果也更加丰富多样。在实践中,我们可以通过简单的真人实拍或低精度的建模动画,快速得到一个用于控制画面的原始视频。只要引入a i转会,无需逐帧绘制画面内容或是进行复杂的动画设计,就能取得生动流畅的动态效果。
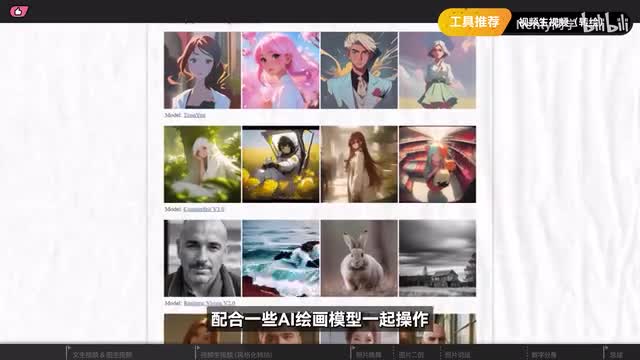
这种处理方法目前也在被许多a i影像,尤其是动画和艺术短片的创作所广泛采用。目前可以用来制作a i视频转换的工具也非常多。在开源技术社区里,最主流的方案是使用一个叫做enemy deep的工具,配合一些ai绘画模型一起操作。你可以使用s d web u i里的扩展插件或是conf u i的成体系的工作流。一些其他的开源项目也可以实现类似的风格迁移效果。包括difc studio以及first co等这些开源项目都可以在本地运行,并且可以灵活运用各种a i绘图模型来实现不同的效果。

但需要你有一个性能足够强大的显卡。如果你是小白,我会更推荐你使用一些将相关技术产品化的在线工具,包括domo a i go。a i与lens go a i等一些定位视频编辑赛道的产品,也将这种风格化转会作为功能内置进了自己的产品里。例如美图的wink,在转会这个赛道里也有一些比较独特的选手,例如deform在单独转会的基础上加入了空间运镜和提示词演化的设计,可以用来实现像这样无限穿越的迷幻效果。我们之前有一期专题视频讲过,如果你感兴趣也可以去了解一下。这三种主流的实现路径涵盖了今天你能在互联网上看到的大多数a i视频的制作方法。

然而随着a i视频领域的探索进入深水区,研究者们也发现可以同时向ai提供多种不同模态的信息,驱动许多其他领域的技术来为视频的生存提供帮助。这些技术的碰撞催生了许多我们以前可能从未设想过的创作新形式。就比如最近你在网上冲浪的时候,一定也曾经刷到过像这样的视频。这种整活含量拉满的a i视频玩法,一般被称为photo dance照片跳舞,除了一张人物照片,再提供一段舞蹈动作视频,a i就可以让照片里的人跳个舞做出对应的动作来。他用到了一些a i姿势识别的技术,本质上是将图片里的人物骨。格和视频里呢去做重新匹配。

你可以在无数搞笑整活人乃至鬼畜视频里见到使用了这种技术做出来的素材。它实现的效果往往十分出人意料,所以经常会带来大量的播放与病毒式的传播。当它足够成熟的时候,或许可以解决很多影视动画乃至游戏行业里的角色动效制作需求。那么在哪里能做这样的视频呢?我会推荐你尝试使用一些专注于这种效果的在线工具。例如国外的bigger a i阿里的通义武王,这个赛道里有一些开源的应用,比如字节推出的magic animal,以及摩尔线上的more inmates anyone。刚才我们也介绍了文生视频和图像视频的技术其实是同源的。

也因此目前绝大多数图像视频模型都能支持输入文字信息,共同引导视频生成。受制于模型的素质,在以前其实这种方式没有受到很多的关注。因为即便你用文字描述了,你想要的效果d i也不一定做得到。但到了今年,由sara领导的新一代视频生成模型普遍采用了一种叫做d i t的新架构,结合新的时空编码模式,改善了生成视频的一致性、连续性和合理性,同时也大大强化了这些模型的语。易理解能力。因此,我们就能够挖掘出更多基于图文生成视频的可能性。

最典型的应用莫过于一些图像作品的二次创作。比如最近你肯定能刷到一些这样魔改大家耳熟能详的影视作品、照片乃至表情包的视频,同一个镜头能衍生出不同的版本来,依靠的就是同一张初始图片和不同的文字指令之间的组合。还有这种让世界名画复活,让老照片动起来变成视频的操作,其实都依托于类似的技术,所需要使用到的工具还是我们刚刚介绍过的那些。在展示前面的一系列样片时,我也标注了他们是使用哪个模型生成的。如果你想做出类似操作,也可以去尝试一下。然后视频还有另外一个非常重要的构成部分,也可以用来驱动视频的生成。

没错,就是说话的语音。在a i视频制作方面加入语音作为输入信息,又催生了一系列非常有趣的新闻吧。我们先从比较简单的一种聊起,就是talking head。说话头只需要向a i输入一张包含人脸的照片,并给它配上一条说话的音频。你他娘还真是个人才,a i就能生成一段人物嘴部在运动的视频,看上去就好像是人物开口说话一样。这里面的核心技术其实是在根据输入的音频对照片做唇形同步,同时还会为人物加上身体轮廓和头部的微动,让它更加生动自然。
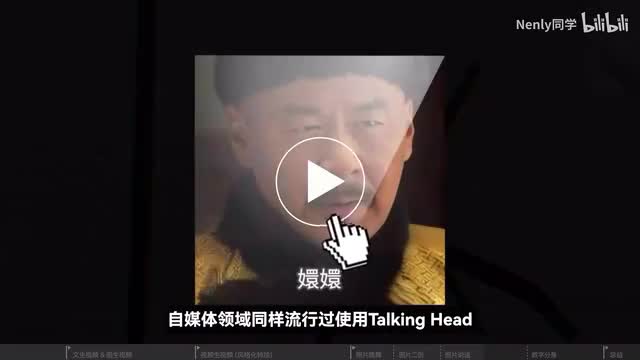
目前最先进的模型甚至可以做到给人物添加上各种各样的微表情,抑扬顿挫的小动作,几乎难以辨别是ai生成还是真正的实拍视频。一些因为各种原因不愿意真人出镜的视频内容,创作者就会利用talking head让一些虚拟的形象动起来,担任视频的讲述者,来给观众留下一个不错的印象。只需要一张图片加一段音频,就可以在视频里建立一个虚拟的v i p。另外自媒体领域同样流行过使用talking head对一些敏感进行二创的玩法,让意想不到的人说出意想不到的话来,同样挺有节目效果的。让这一方面的技术进一步成熟以后,还可以被广泛应用到各类人机交互的场景里,比如游戏里的npc、电商的虚拟客服等等,让这些地方的虚拟人物形象变得更加鲜活。在这个方面也有一些非常不错的应用,比如阿里的全民畅演,万幸的verbal talking head等等。

当然还有一些开源的工具,比如腾讯推出的any portraits,快手的live portrait set talker等等,是可以支持你在本地进行更大自由度的形象定制的。同时唇形同步的技术不仅仅可以用于图片,还可以用在视频上一些a i短片里。为了让出镜的人物念台词,创作者往往就会利用相关技术给人物旁白和视频画面做匹配。诸如软尾皮卡等图像视频的应用也都集成了这个功能。只要你在使用时开启相关选项,再上传音频,就可以一步到位生成在说话的人物视频了。一些专门做视频唇形同步的工具,包括risk a i think ink labs,开源的way to leap video recorking等等,也可以支持你对已有的视频做类似操作。

在一些讨论里,talking head的技术会被归类到数字人的板块里,但它能够生成的区域一般仅限于人物的头像周围,所以严格来说它不能算作一个真正的数字人。那真正的ai数字人又是什么样的呢?and what can i say? 你可能也曾经看到过像这样可以展现大半身甚至是全身形象,不光可以说话,还可以做一些动作的,更加活灵活现的数字人还有一个更为贴切的称呼,叫做数字分身。和talking head的原理有相似之处,但制作起来还要更复杂一些。需要拍摄或提供一系列讲话时做出动作的人物片段,a i会通过一定的方式分析处理,把这些片段切分成一个个小的动作段落,然后让他们在人物讲话时循环播放。此时再根据数字人说话的内容,对脸部进行唇形同步,就可以生成这种质量极高且无限接近于真人的数字人了。只要有需要人的地方,就有数字分身的用武之地。

目前,生成式ai驱动的数字人已经被大范围地运用到了一些低成本的真人出镜自媒体内容里,比如信息流广告、资讯播报等。一些知名的公众人物也热衷于制作自己的数字分身,并把它作为一种和大众拉近距离的互动方式。如今有非常多的工具可以为你打造一个符合需要的数字分身形象,比较受欢迎的包括d i d黑镇等。只要打字输入文本内容,再选择一个符合你需要的模。就能让他为你出镜广播视频,他们也都有上传照片驱动面部运动的talking head功能,但效果不如数字分身那么生动。不过在这些应用里,你只能使用他们已经录好素材的数字人预设。
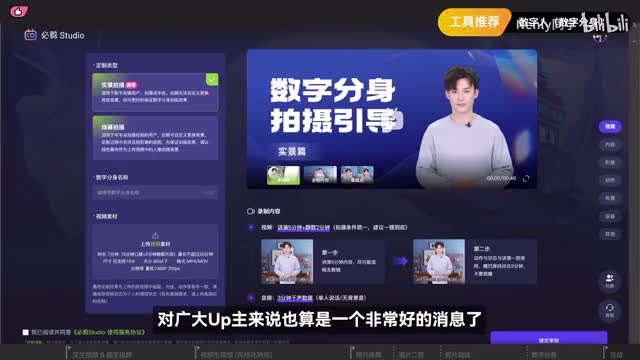
如果你想深度定制一个数字人,以前往往需要求助一些企业级的商业产品,他们的成本费用也会更高。但在上半年,b站为站内up主提供了一个a i数字分身创作工具必剪studio。只需要上传一定量的实景或绿幕拍摄片段和音频素材,就可以做出一个高质量的数字分身来了。对广大up主来说也算是一个非常好的消息了。以上就是这期视频里分享的所有内容了,看完以后你对a i视频这个领域有没有更熟悉一点呢?归功于在这个领域不断耕耘的a i科技公司和积极探索的爱好者们,a i视频的创作生态正在百花齐放。我们今天提及的也并不是ai视频制作的全部,还有很多有创意有深度的a i视频玩法,可能需要一点点额外的小操作。

未来的某个时间点,我非常愿意和你分享更多。ai的发展日新月异,我们介绍的所有技术和产品在一段时间后说不定就会被革新一轮。到那个时候我们就一定有更多的新东西可以去讨论了。同时我们这期视频提到的各种工具,主要聚焦在视频素材或者是分镜片段的生成上。但a i g c技术给影视行业带来的冲击远不止于此,就是前期的脚本策划,后期的剪辑、特效、配音、配乐等环节,其实也都有ai的用武之地。你有没有感兴趣的话题,欢迎在评论或弹幕留言。

这里是哪里?感谢你看到最后,我们下期再见了,拜拜。




