
在ai生成视频领域,一直存在着一个难题,就是多个生成视频中的人物主角难以保持一致,就比如这两个视频中分别让ai生成一个女孩伤心的、流泪和开心的笑的视频,生成的表情是没问题的,但是这显然是两个人无论如何调整提示词,抽多少次卡都无法让两个女孩变成同一个人。这就是人物角色无法保持一致性的问题,上一个生成视频的主角是张三,但下一个生成视频的主角就变成李四了,这样就很难用ai生成一个同一人物角色有故事情节的短片a i生成视频的实际应用场景也很难得到退。那么国内的最强ai视频生成软件可以a i就完美的解决了这个难题,具体怎么做呢?接下来看我操作,大家如果需要ai工具或者了解其他,可以三连关注,在视频下方评论。
我想学我会一分享的。那么首先呢我们可以在左侧找到这个a i定制模型。然后呢嗯点击它。
我们会需要就是黄金或者是钻石会员。在你同意了这个协议以后呢,就可以上传视频了。首先呢我们需要生成一些符合这时段视频的素材。
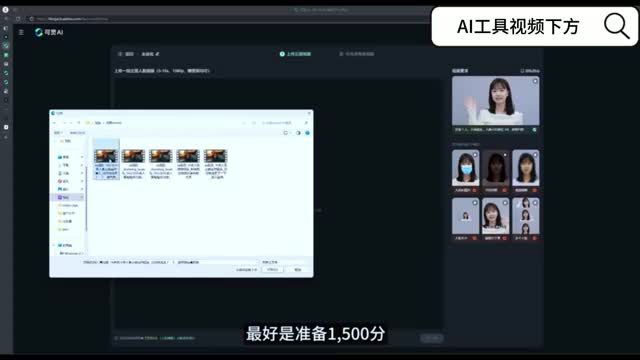
那我们最好呢是先创建一个文件夹,方便我们一次性的让我们把这些素材上传上去。那积分呢最好是准备一千五百份,然后两个小时左右就可以收到这个通知了啊。第一个视频的要求呢需要正面的人练五到十五秒,那其实五秒就可以了,因为十秒呢它容易出bug。
然后一千零八十p的话是建议大家直接外壳零生成,因为如果说你用海螺的话,嗯,它是不满足这个一千零八十p的要求的,就会上传失败。好,那么上传第一个视频以后呢,需要补充十个同一人物的多角度视频。就是比如说。
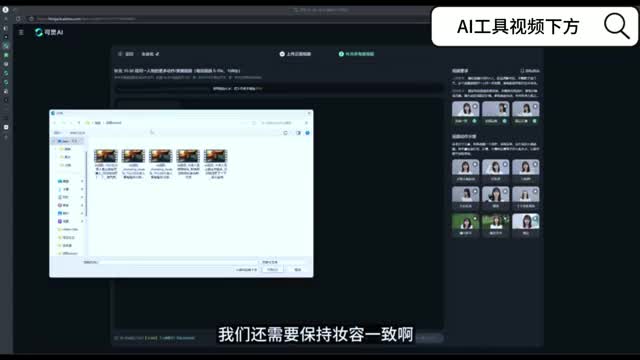
嗯,手臂的一些运动啊,打招呼呀,左右转头啊,低头抬头之类的。还有就是表情上的变化,哭泣、微笑这些我们还需要保持妆容一致啊。你不能说前面是个大浓妆,后面就变成了白开学,但是我没有办法识别是一个人吗?还有就是你上传同步的视频的话,系统会拒绝你上传。

所以在这里呢,为了保证它能够识别是一个人,我们用的同一张密卷的图片,大家可能用不同的提示词啊生成这十多个视频。因为我试过,就是虽然对我们来说长得差不多,但是如果你用不同的图片的话,对于a i来说这个模特就各是同一个人。即使是你在生成minger图片的时候,启用了caat ref这个参数,但是呢它实际上生成的还是有着细微的差别。
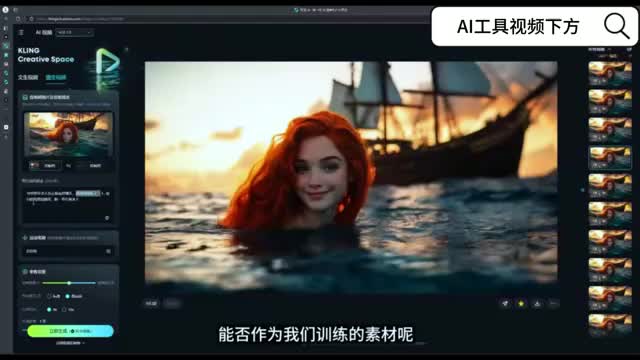
那么可伶呢最多是可以上传九十九个素材,但其实我们不需要那么多,十个就够了。该如何判定这个能否作为我们训练的素材呢?有三点,第一,他的表情要自然。第二,他的面部不能有遮挡,第三,他的年龄要符合我们的人设。

接下来我们看几个失败的案例。那首先这个两步是被遮挡,还有这种伸手的也是手掌挡住了脸,你是不可以的那像海浪起伏呢,他的嘴也被遮住。像这种呢没有遮挡,但是表情不自然,像眉毛太挑牙龈,免得太开了,就感觉不像一个美人鱼,尤其不像童话故事里面的主角。
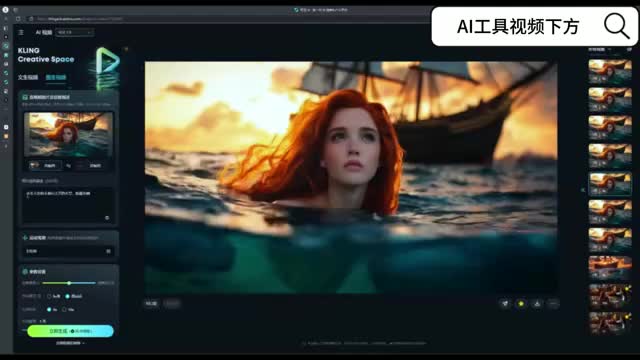
而根据你这个人物的人设呢,你可以加一些,比如说十六岁三零beauty。因为真诚的时候,就会做一些。这样他的整个颜值呢就保持代谢。

然后有的时候如果没写的话呢,他可能就是脸就会变。当然写了也不保证就是会完美。但如果人物的脸在转头、鼻头、抬头这些镜头下,他的长相和岁数有一定差距的话,你可能就需要加一个年龄的背景在那个t四纸里面。

然后像这种视频尽量都通通pass掉,就不要把有瑕疵或者是违背人设的一些表情管理失败的视频作为你的素材,来训练你的模型。接下来快速给大家展示一下英文版的界面。和中文版差不多,他们的人物势力就换成了一个欧美人的形象。

我当时其实是用了这个海外的可林来训练这个烧美人鱼的人类魔性,为什么呢?因为当时考虑到国内的克林,它会有一些限制,就比如说其实这个小美人鱼她是穿了一个小贝壳的,但是可伶呢就是识别觉得旧图片不符合一些要求。热论的话现在只支持可零一点五。那我们点击纹身视频,在这里选择你的人物。
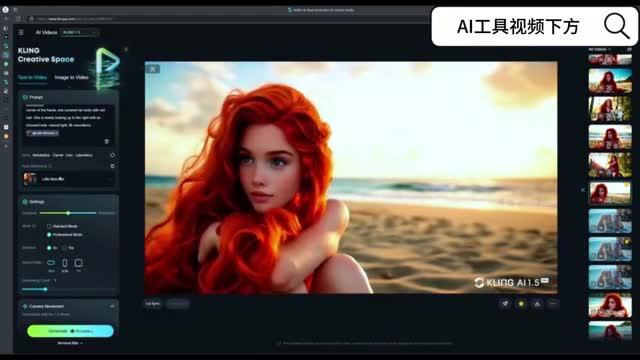
这三个呢是系统自带的那中文版和海外版界面和操作是一样的。我们简单看一下提示词的注意事项,这里面光线非常重要,我们先看几个画面,它是在一个沙滩上,那我的提示词就会说它是一个fantasy film。你如果需要它生成比较美的镜头,最好告诉a i支持一个film,这是一个电影级别的镜头。

然后fantasy只是让他明白这是一个什么类型。比如说你是一些日常场景,你可以加到mental。然后非常重要的就是natural light。

不写的话可能会给你生成一些较暗或者是过度曝光,光线一直在变的视频。而这些后期调色都没有办法解决,或者间距在非常的不统一。那这个视频呢就是一个成功的案例。

这个镜头呢是blow me fag,营造出一种梦幻浪漫的效果。那反之呢dramatic lighting呢就营造出一种神秘不安的情绪。你可以通过不同的打光感受到这两个仙女角色阵营不同。

而月光呢在这里面就传达着荆棘变成玫瑰的神秘魔法,需要的话可以一键三连加上关注名词p p t。接下来的画面里呢小美人鱼拿着一把刀,因为我们不可以投身视频,所以它对场景的一些想象就是比较有限。情绪的表达也不太好。
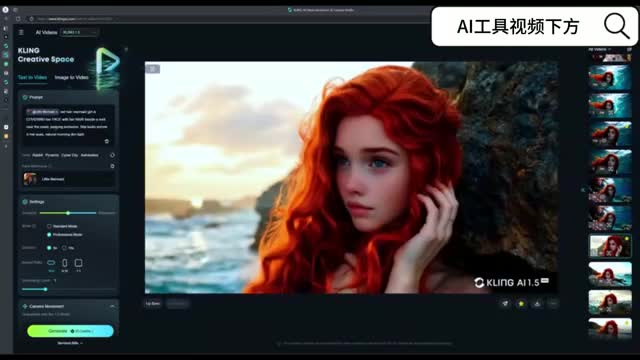
所以他没有展现出那种伤心和真假,也没有哭出来。那后续呢我觉得可能是需要对这个人类进行一些细致的描述。这个人物的还原度是非常的超出我的预期,和我训练的图片的相似度啊高达百分之百。

如果说你一边生成三个视频效果都不好,你就要考虑一下休闲提示词的问题。当然有可能是模型的问题,那也许就要放弃这个场景。有时候呢我会在提示词里面放全大写的单词,侧重点呢就在于动作或者是特征。

但应对如果a i实在听不懂的情况,而这又是重要场景无法跳过,我们就给他教俏重点。还有一个问题就是可伶的这个人鱼的尾巴,鱼鳞和鱼尾这种画面跟我们间里生成的这个人鱼尾巴相差的太远。但啊我觉得这个也是可以理解的,毕竟我们的这个是一个纹身视频的模型。

那可伶训练的素材肯定就没有收集幻想生物的数据,还有就是海洋里面的素材可能要少一些,所以海洋的那些奇珍异草,嗯,荷花里面的海神宫殿,它是想象不出来的那接下来呢我再测试几个不同的业务场景。然后最后我来说一说这个多角色的场景。那在这个画面里呢,我其实是写了呃金色头发的帅气王子,但是它呈现的是小美人鱼的脸。

目前它不支持同时调用两个人的模型,所以如果你是有双人的画面,最好呢还是用m jenny生成,自然会损失角色一致性。




