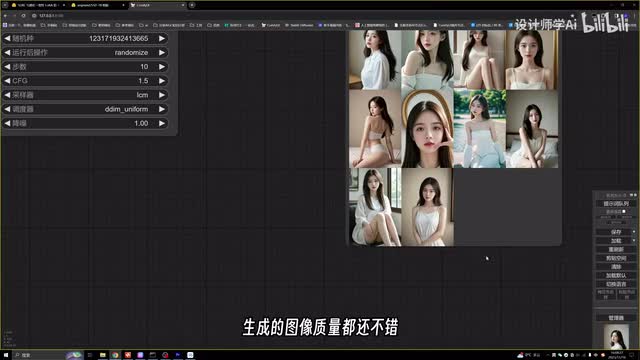
这期主要讲一下新出来的l c m模型。我使用的是s d一点五的麦菊显示模型,大概用了三秒钟的时间就生成了十张图,生成的的图像质量都还不错,也没有出现图像崩坏的效果。终端中显示整个生成的时间就是三秒。这在之前是不可能想象的事情。
那么l c m是什么?它提升图像生成速度的原理是什么?我们又应该怎么样使用呢?l c m的全称是models,翻译过来是潜在一致性模型,是由清华大学交叉信息研究院的研究者们构建。他们通过创新性的方法使用l c m,只需要四到八步的推理就能生成高分辨率的图像。而不像之前需要二十五到五十步,所以大约只需要一秒钟就可以运行s d s l模型。而在mac电脑上生成的速度相比之前快了十倍。
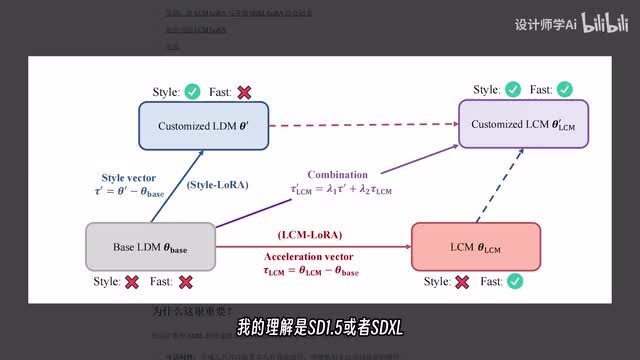
这个数据在后面官方还有专门列出来的一个表格。那么刚刚提到的创新性方法是什么呢?在这里他们也概述了一下l c m laura的核心思想,就是仅训练少量的适配器,而不是完整的模型。我的理解是s d一点五或者s d x l模型通过l c m laura的过程指针流出了针对l c m采样器最有效的信息被保留下来。所以在使用l c m采样器,只需要很低的步数就可以生成不错的图像,从而提升了生成速度。

那么通过l c m laura蒸馏之后,生成的图像质量是否会差了一些?来到质量比较这里可以看到使用的图片越多,图片的细节也就越出色。但是在第三步的时候,其实图片的整体效果已经非常不错了。而如果使用原来的s d x l模型,想要生成整体效果优秀的图片,大概需要二十步,而二十步之前的图片几乎都不能使用。所以根据官方的说法,就是使用l c m生成图像,相同的图像质量,但是速度快了很多。

为了让你好理解究竟快了多少,官方还放出了在各个不同的硬件平台上,使用s d x l laura a l c m四步生成的图片时间和s d l使用二十五步生成图片的时间。其中我觉得最出色的就是在c m系统上使用m一max芯片,生成的时间分别是六点五秒和六十四秒,速度相比之前快了接近十倍。所以使用s s l l的模型又又降低了当前我们要能够使用的l c m l o a的模型主要有三种,分别是l c m lora s d x l l c m lura s d一点五和l c m lura s s d一b前面两个ora都很好理解,就是对应s d s l模型和s d一点五模型使用。而这里的s s d e b模型又是什么?可以简单介绍一下具体的s s d e b模型,我们放在下一期详细介绍。
s s d e b模型是一种精炼的s。d s l模型比原始的s d s l模型小百分之五十,速度快百分之六十。所以在搭配上l c m laura就是快上加快。现在我们可以在conf u i上体验l c m的完整流程。
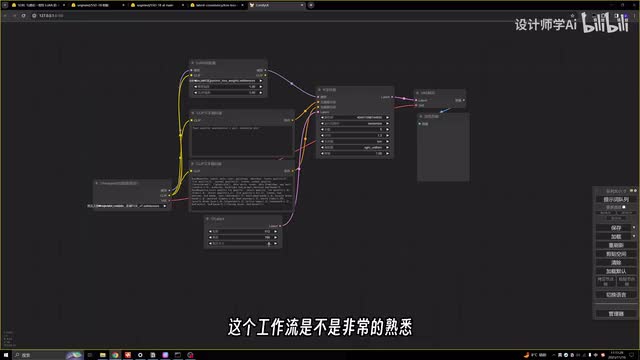
不过在使用之前,你需要打开你的manager,在商店中搜索l c m,下载这个l c m simple。然后还还是在manager点击update date l将你的conf u i更新为最新的版本,然后再重启conf u i即可。我已经搭建好了工作流,这个工作流是不是非常的熟悉?没错,其实就是使用最基础的文身图工作流增加了一个laura加载器。不过有一点不一样,之前使用laura加载器需要将clip节点连接到文本编码器上,而使用l c m laura的时候则不需要,只需要将laura节点连接到采样器上即可。
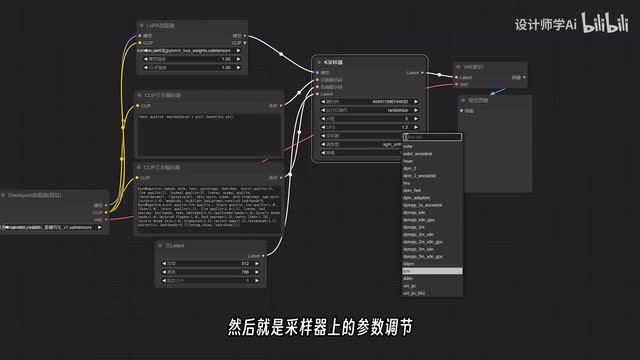
如果你使用的是s d一点五的模型,l c m laura就对应选择s d一点五的工作理由就是这么简单。然后就是采样器上的参数调节。根据l c m的原理,首先你需要将采样器修改成l c m。调度器的选择可以根据你自己的喜好。

我这边测试下来d d i m uniform和s g m uniform的效果比较不错,然后降低c f g和步数,一般c f g在一到二之间步数数可以在四到二之间都能获得还不错的效果。点击生成一下,可以看到生成的效果和速度都是非常不错的,生成一张图应该不到一秒的样子。切换到s d s l模型,这边也相应的切换到l c m laura s d s l尝试一下效果。生成的速度还是很快,大概是两到三秒一张图,但是效果没有那么清晰了。
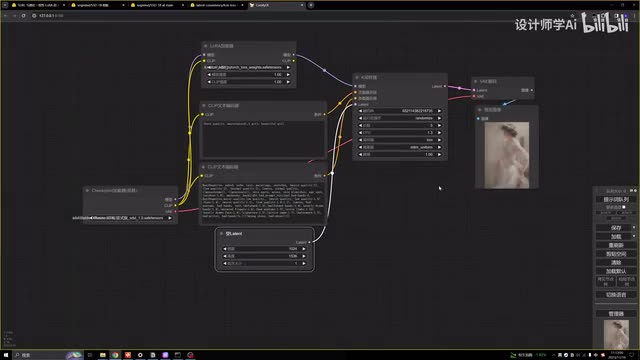
多尝试几张都是同样的效果。或许是提示词的原因,也有可能是步数太少的原因。我将步数调整到八,我们再尝试生成一下。生成的图片明显变得更加清晰了。

如果你想要搭配其他的laura,需要复制一个laura加载器,将它们串联起来,在提示词中添加触发词,就可以获得laura的效果。最后还有一个model sampling described模块,这个模块建议在串联laura的时候一起使用,以防有的laura产生效果。然后我再串联一个陌生的laura,这个laura的风格化比较强,这样就能很容易的看出laura在工作流中产生的效果。点击生成一下。
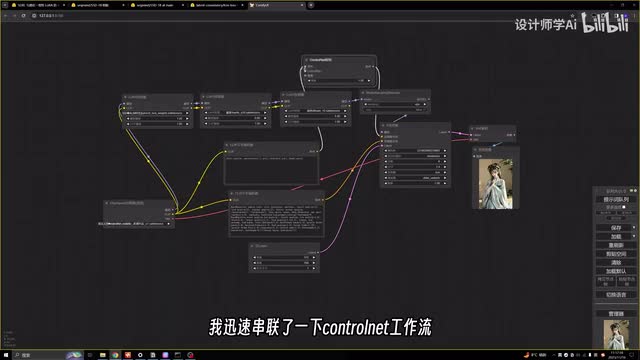
可以看到生成的图像有着明显的水墨风格。接下来再尝试一下能不能结合c t l l e t使用。我迅速串联了一下control l t的工作流,这里我使用软边缘的control lt模型。点击生成一下。
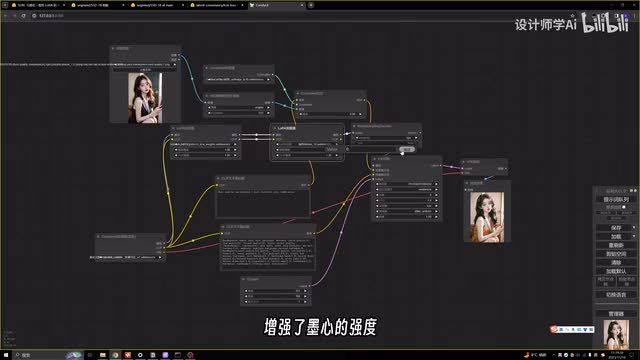
可以看到生成的图片成功了,也有可能是服装被control lt识别,所以生成的图像并没有汉服的特征。所以我稍微降低了control len的强度,删掉了汉服的laura增强了模型的强度。主要就是看l c m laura是否能和controlled结合使用,再生成一张效果和预期的差不多。看来s d一点五的模型结合l c m laura能够适应laura和controlled。
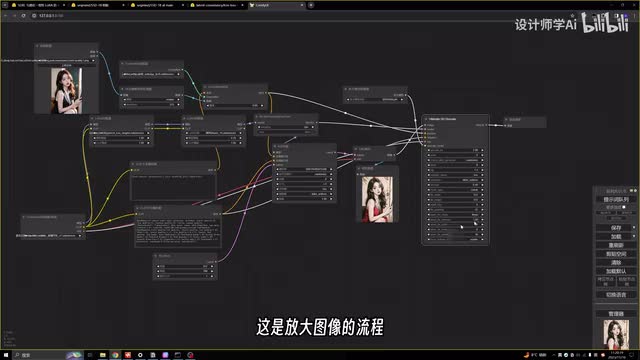
最后再添加一个s d upscale的模块,让图像细节增加尺寸,放大一下试试。在这里同样可以把采样器调整到和前面的采样器相同的参数。试试放大图像的流程是不是也会变快?点击生成。可以感受到放大图片的流程也同样变快了,而且放大之后同样添加了细节。
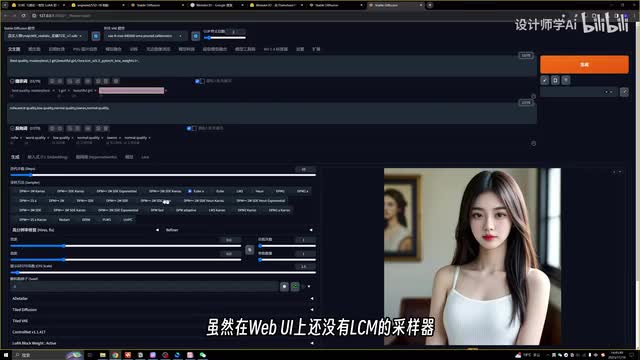
那么结合animate diff生成动画同样也是可以的。这个之后我会单独出一期视频。现在虽然在web u i上还没有l c m的采样器,但是我也尝试了一下能不能用l c m。laura结合现在已有的采样器,达到提升生成速度的效果。

我对所有的采样器进行了测试,s d一点五的模型使用的还是麦菊写实,c f g部署使用的是一点五,分别生成了步数为二到八的图像测试效果。在服务部署使用一点五,其中有不少的采样器都能生成还不错的图像,其中有八个采样器可以在四步内生成完整的图像。大家可以参考这张图来进行采样器的选择。s d x l模型进行测试是使用的是原版模型,生成的效果就比较惨不忍睹了。

几乎没有一个采样器能够完成完整的图像,唯一能够生成图像的也就是欧拉a了。但是这样的图像质量应该也不能使用了,或许需要等到web u i对应更新l c m采样器之后生成的。图像质量才会有很好的改善。最后l c m laura可以到官方的hugging in face上进行下载。

如果嫌麻烦的话,b站的小伙伴可以在视频简介中获得我整理好的模型包,其他平台的小伙伴可以加入我的粉丝群获取模型包。最后总结一下,l c m laura在康复u i上使用,能够获得比较不错的加速图像生成的功能。并且l c m laura s d一点五支持与control l t s d upscale等等结合使用。这就是本期的全部内容了。




