
这个清晰度和丝滑的人物动作,你敢相信这些视频都是由ai生成的吗?我所输入的仅仅只是一段描述性的文字,也没给他提供任何图片作为参考。前几天我用mobley生成第一个视频的时候,简直惊为天人。它的效果跟目前市面上其他的a i视频生成工具,完全不像是同一个时代的产物。频道的老观众应该记得我之前做过一期关于pig labs的使用教程。

下面咱们来看一组效果对比,是我使用同样的提示词,分别用on valley和pga来生成的视频。moon valley的使用方法跟披萨一样,也是在他们的官方disco的服务器通过机器人指令生成视频。new belly机器人目前不支持私信,所以我们在左侧的new梦频道中任选一个加入,然后点击右上角的井号图标,创建一个新字区。在文本框输入斜杠,create空格。
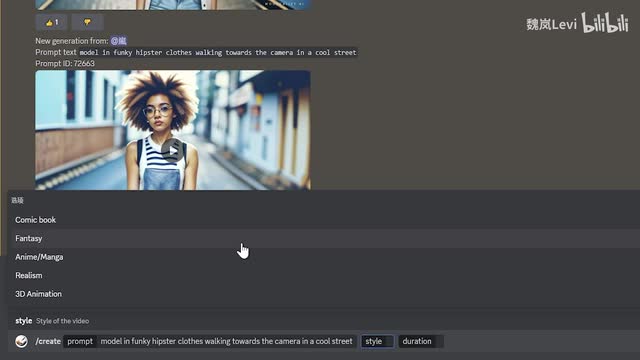
在prompt这一栏输入你想要生成视频的文字描述。在第二栏的style这里选择一种风格。目前有五种预设风格,分别是美漫、幻想、动画、写实和三d建模。第三栏的duration选择视频长度短中长,生成的视频时长分别是一秒、三秒和五秒,视频越长需要的等待时间也越长。
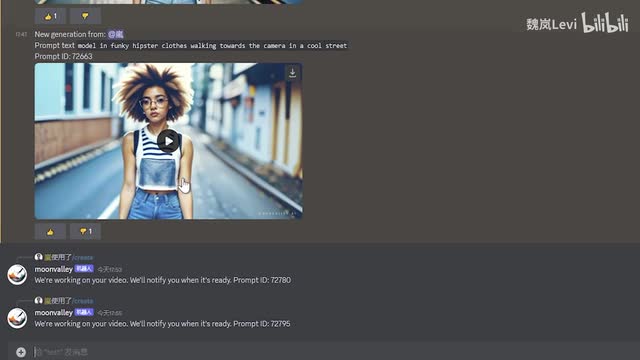
他们在右侧也标上了平均等待时长,同一个用户同时最多可以发送五个生成请求。你需要等前面的视频生成完毕了,才能继续发请求。如果生成的视频达到了你的预期效果,可以在下方点个大拇指,不好的话就点个踩,这会有助于他们训练更好的模型。视频文件是原生七百二十p十六帧。

为了节省大家的时间,我将mova ley预设的五种不同风格分别列出来做个对比。首先是美漫风格,很像dc和漫威那种手绘漫画。第二种是写实风格,顾名思义,还原真实的人物和环境。第三种是幻想风格,它的效果和写实会有点相似,但是更像游戏c机。

第四种是动画风格偏向日系,动画有很明显的重绘痕迹。而且从观感上来说,帧生成不够连贯。第五种,三弟建模有点像blender引擎的建模材质。moon valley目前没有提供任何额外的参数调整选项,你需要写的只有提示词。
在这里,我给大家分享我写提示词的个人心得。首先最重要的是镜头和视角,你要在提示词中注明是俯瞰特写还是广角镜头之类的。其次是角色人物的外形特征,衣着和附属物品,人物在进行什么样的动作。最后是场地和背景。

再补充一些诸如色彩、光线之类的描述,完善细节。你还可以在提示词中写上需要参考的风格,比如弗兰克米勒的罪恶之城游戏最终幻想等等。整体来说,mobley的提示词写法跟mid journey很相似,你甚至可以直接将mid journey的提示词照搬过来,效果出奇的好。当然,你也可以在官方的精选频道或者公共频道中参考别人的优秀作品借鉴学习。
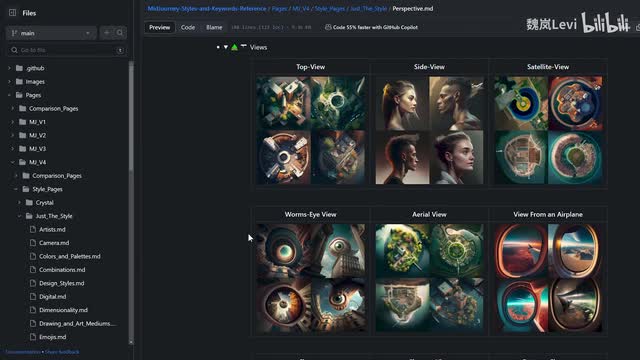
这里我再额外给大家分享一个工具,这是github上一个适用于mint juny提示词写法的项目。里面汇集了各种摄影和绘画的专业术语。如果你不知道怎么去表达自己想要呈现的效果,不妨先到这里参考一下。mobley未来有计划添加更多的新功能,具体请关注他们的官方公告。
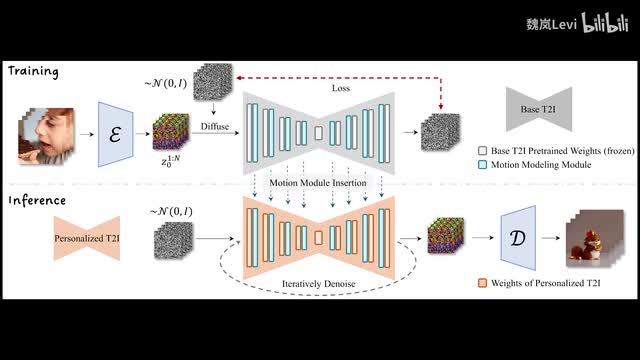
视频的后半段,我会介绍一种使用ai绘图工具stability fusion来生成视频的方法。使用的是一个叫animate diff的插件。类似于control net animate diff也是一个可用于sleep diffusion的插件。生成视频的原理是在基础的文本到图像模型中添加一个运动建模模块,这个模块通过网络上的各种视频和短片进行训练。

a i会参考训练内容中的动作轨迹来生成一系列的相似图像。这里我给不太了解的朋友简单科普一下帧数这个概念。比如我们平常经常会听到的高刷新率显示器,游戏中的f b s。还有电影的标准二十四帧。
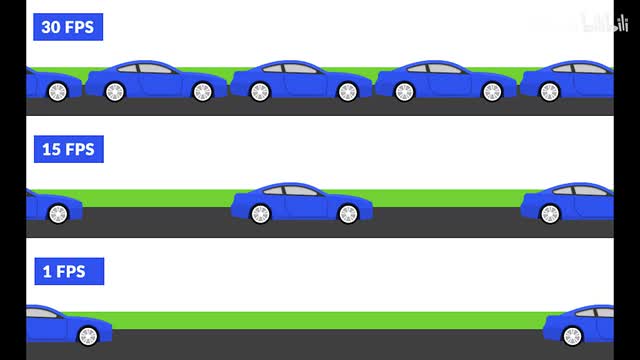
f p s就是指画面每秒播放多少帧,每秒刷新多少次。举个例子,一个物体从a点运动到b点花费的时长是一秒钟。如果刷新率是两赫兹,你在这一秒钟就只会看到两帧的画面,这个物体会从a点瞬移到b点。如果刷新率是六十赫兹,物体从a到b的运动过程中,你会看到六十张不同的画面,整个过程会更加流畅连贯。

所以说到底视频就是快速切换无数张静止的图像。我们上学的时候应该都做过,在书本的角落里画简单的小人。当我们卷起书的角落,像洗扑克牌那样松开的时候,小人就会动起来。如何使用animated dif插件呢?首先确保你的s d web u i和control net都是最新版本。
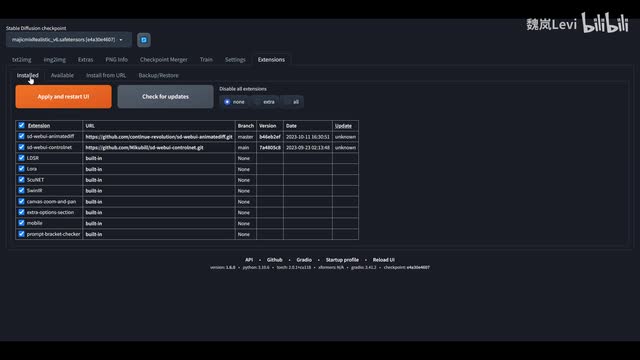
点击extensions插件,从u r l安装,输入animal tifft github仓库地址,点击安装。安装完成后,回到前面的已安装页面,点击确认并重启u i。现在我们能看到下方多了一个animates dif插件选项。下一步,在项目作者的hugging face主页下载动作模组。
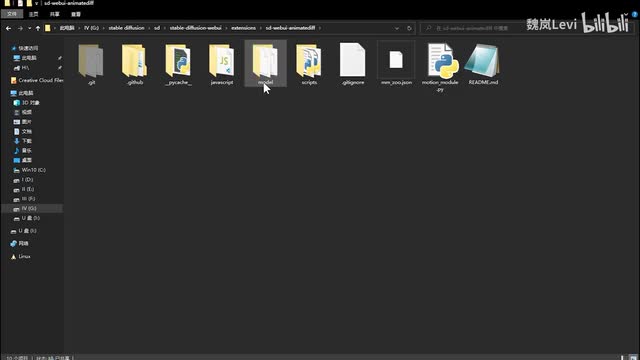
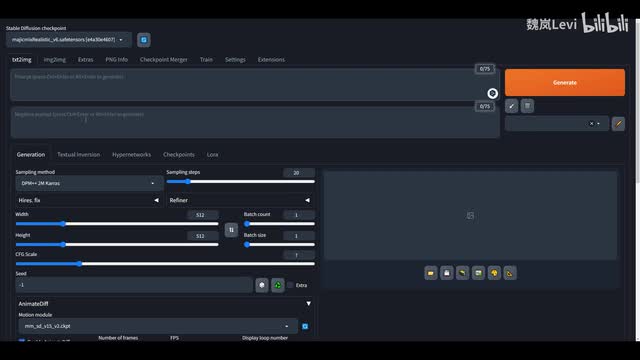
如果只是想试试的话,单独下载这个s d v幺五v二的检查点文件就行了,其他都是可选模组。下载完成后将动作模组放到web u i主目录的extensions s d web u i enemies dive model文件夹。接着打开web u i,点击settings optimizations,勾选pet prompt,negative prompt to be simlins确认更改。现在回到text to image界面。
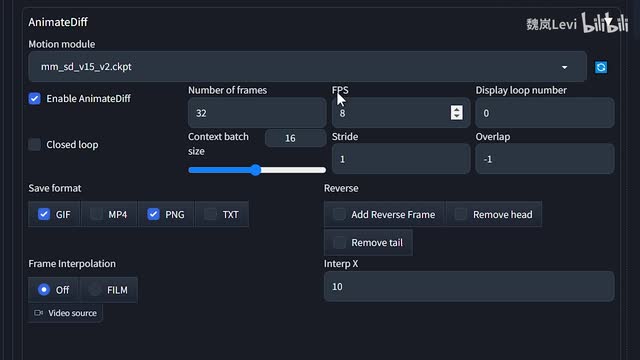
点开animal的diff插件。在动作模组这里选择我们刚刚下载的文件。勾选下方的enable animated diff,在number of frames和f p s这里填入对应的数值。例如总帧数三十二f p s八生成的视频时长就是四秒,总帧数三十二f p s十六时长就是两秒,以此类推。
在下方的格式这里勾上m p四。之后我们就像平常生成图片一样,写好提示词,点击生成就行了。不过需要注意的是,作者目前并没有对一点五以外的模型进行动作模块的训练。所以你只能选用以一点五为基础的模型。
本地部署对硬件的要求比较高,需要十二级以上的显存,建议使用谷歌在线部署。更多使用方法请参考作者的项目主页,相关链接我都会贴在视频下方,下期见,拜拜。




