
当你第一次打开stable diffusion的时候,是不是感觉它的界面复杂还难以理解,或是因为它的功能和参数太多,不知道该从哪里下手呢?那么这个视频将帮助你轻松上手,让ai创作变得简单而有趣。为了更容易的学习stable diffusion,我们需要先了解它的工作原理。在slap diffusion中有两个关键的空间概念,像素空间和前空间。
像素空间是我们在现实世界中可以看到的,前空间,是我们看不见的低维度空间,而stable diffusion就是在前空间中进行扩散和降噪,生成图像再转到像素空间的。整个生图的过程是先在提示词框里输入文字,通过clip编码后把它转化为stable diffusion可以理解的数据,并传入到前空间。在前空间中会生成一个随机的噪声图片,然后通过大模型进行干预,接着采样器开始降噪。
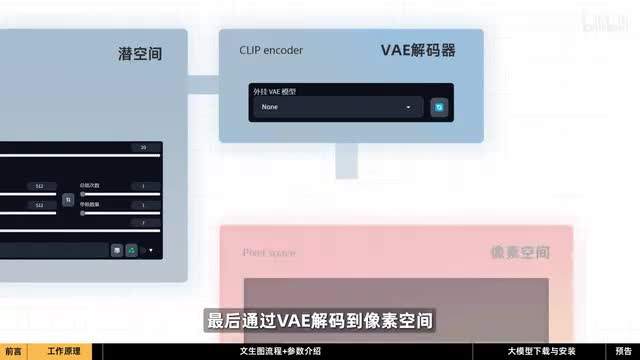
经过几十次的迭代后,我们想要的图像就在前空间中形成。最后通过v e解码到像素空间,我们就可以在现实中看到这个图像了。这就是stable diffusion生成图像的基本原理。
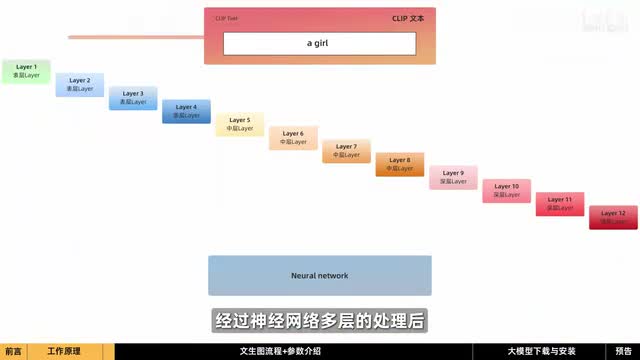
我们来试着生成一张图里的女孩为提示词。首先这个提示词会被送到clip编码器,经过神经网络多层的处理后再传送到前空间。这个过程的目的是提高提示词的精确度,使生成的图像与提示词更匹配。
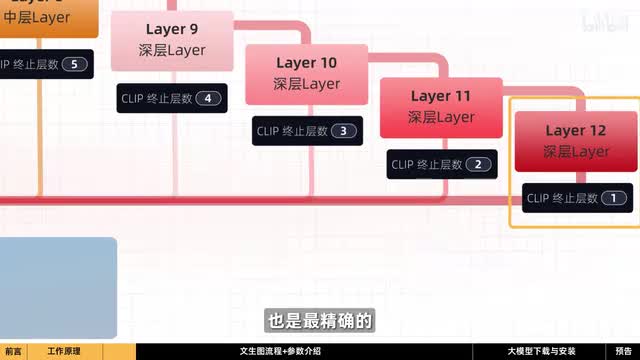
在这里终止层二意味着在倒数第二层结束。一则表示传递到最深层也是最精确的,但并不一定是最好的。根据使用的大模型不同,生成的结果也会有所不同。

通过比较我们发现中子层的数值越大,生成的内容与我们的提示词相关性就越低。因此我们通常会选择数值为二的中止层,这样可以得到更符合我们想要的结果。然后选择采样器,不同的采样器会产生不同的结果,具体的说明会在后面的视频中详细介绍。

我们现在选择这个默认的采样器,接下来是迭代步数。这可以理解为在生成图像的过程中,模型重复执行采样去噪的次数。次数越多生成的图像质量就会越高,但生成的速度也会变慢。
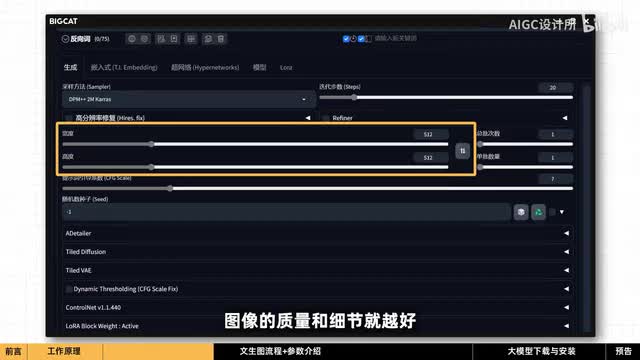
实验表明超过一定的步数后,质量不会有明显的提高,只有细节上会有轻微的变化,所以根据需求适当的选择,在这里可以设置出图的尺寸宽度和高度尺寸。越大图像的质量和细节就越好,但对电脑的性能也会要求更高。需要注意的是因为我们使用的s d一点五版本的模型,是用五幺二乘以五幺二的图片进行训练的,尺寸过大可能会导致异常现象。
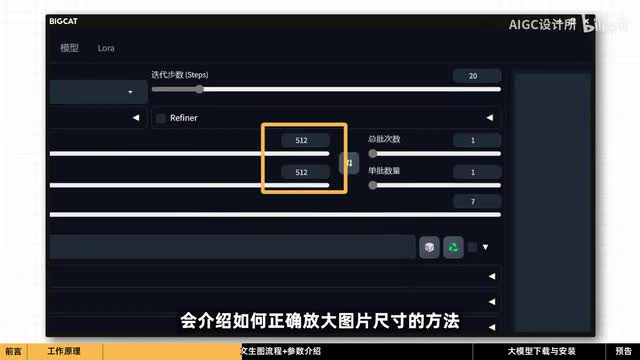
所以我们在这里选择的是五幺二乘以五幺二。在后面的视频里会介绍如何正确放大图片尺寸的方法。在这里你可以设置一次生成几张图像,默认设置是一次生成一张。

如果你想一次生成多张,该怎么设置呢?总批次数表示生成图像的批次数,单批次数表示每批生成图像的数量。例如如果总批次数设置为一,单批次数为四,那么就会一次生成四张图。相反,如果总批次数设置为四,单批次数为四,那么就会分为四次,每次生成一张图。

这两种设置都会生成四张图。但如果电脑在生成过程中出现问题,单批生成的方式可以保证已经生成的图像不会丢失。因此我们通常会设置总批次数来控制生成图像的数量。

下面是提示词引导系数,可以把它理解为提示词的权重。系数越大,生成的图像就会越接近你的提示词。系数越小,a i的创作自由度就会越大,生成的图像也会偏离你的提示词。

较小的系数给了模型更多的发挥空间,而不是严格的遵循提示词。有时候较小的提示词遵循提示词会比较大的引导系数生成更好的结果。但系数过大也会得到不理想的效果。
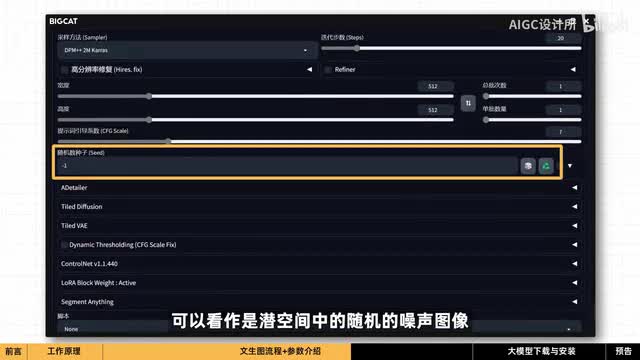
因此在保证图片质量的前提下,找到一个平衡点再做选择。随机数种子可以看作是前空间中的随机的噪声图像。默认值负一代表生成图像是随机的。
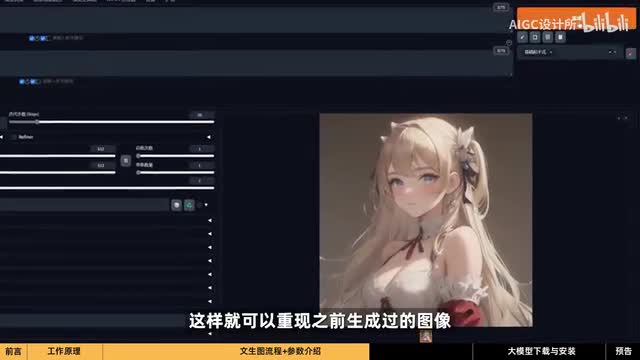
然而每次生成图像后,这些随机的种子都会被记录下来。我们可以固定这张图片的种子值,这样就可以重现之前生成过的图像。重现的前提是在所有设置参数保持不变的情况下,包括提示词。
通常我们使用这个功能,在固定种子的情况下修改某一项参数来进行效果的对比。这里可以选择随机,最后进入到v e解码阶段。这里的外挂v e模型是在大模型内的v e出现问题或者我们对结果不满意时的替代方案,但并不是必须使用的。
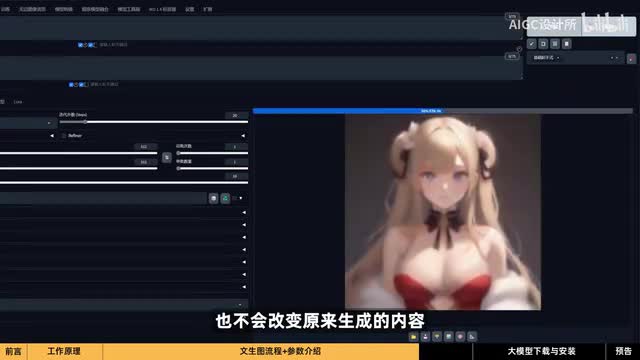
外挂v e模型是在前空间生成图片之后再进行修正。因此已经生成了一张满意的图片后,再使用v e模型修正也不会改变原来生成的内容。整合包里自带两个v e模型,一个是用于二次元风格,另一个是用于写实风格。

我们可以利用它来调整图片的颜色、明暗等细节,以获得更好的效果。通常我们会把它当成滤镜来使用。那么我们的第一张a i作品就完成了。
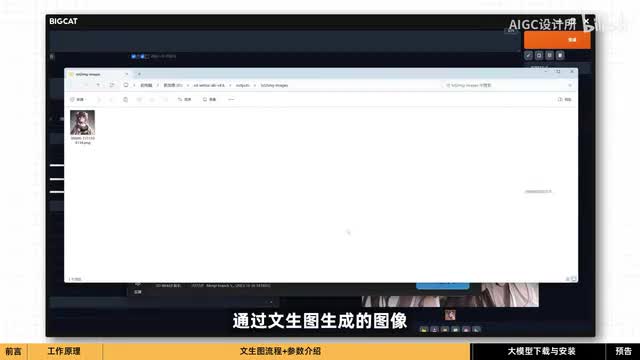
如果想保存这张图片,你可以在这里找到它,点击它并不会弹出,需要到下面点击打开。你也可以在启动器里的文生图这里打开这个文件夹,通过文生图生成的图像都会存放在这里。如果想要尝试生成其他风格的图像,那么我们就需要使用一个叫做checkpoint的模型,它也被称为大模型、主模型或者模型。
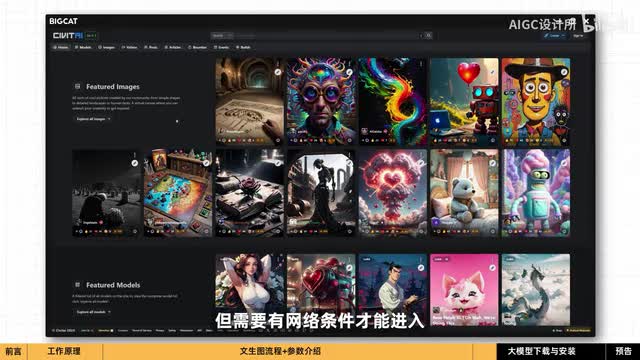
你可以在这些网站上下载模型,其中最著名的是c站,但需要有网络条件才能进入。在model里。右上角的筛选功能里选择check point的模型。
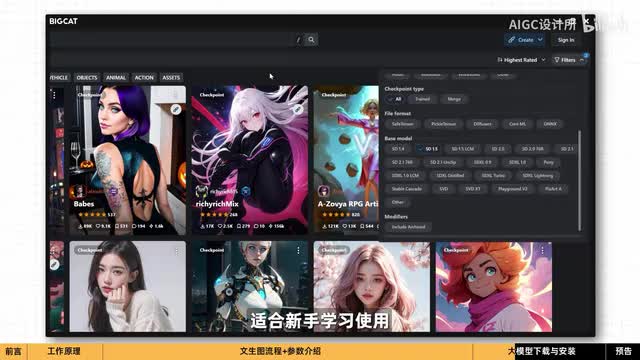
这里建议使用s d一点五版本,它的模型种类多,使用门槛低,适合新手学习使用。你可以选择一个喜欢的风格。在这里点击下载。

下载完成后,把它放到启动器根目录下的stable diffusion里。或者通过启动器在模型管理里点击选择模型标签页,再点击右上角的打开文件夹,也可以打开模型的文件目录,把下载好的模型放进去即可。安装好模型后回到y b i界面,点击刷新,展开下拉就可以看到我们刚才装好的模型。

选中后我们需要加载一段时间,下载好后我们再点击生成画风就变成我们选择的大模型风格了。steve ty fusion有许多的模型,这意味着我们有更多的选择来满足我们的需求。




