
这是一段文字,这是一个光标,把光标放在生产按键上并点击,你就得到了一张刚刚文字所描述的精美图像,这就是ai绘画,它离我们并不遥远。事实上,如果你有一台电脑,不管是mac还是pc,只要五分钟时间,你也可以快速上手ai绘画。大家好,sherry. 在今天视频我们就来在在p c上快速入门ai绘画最好用的工具之一,stable的fusion。如果你一直想尝试ai绘画,但是出于各种各样的原因没有去做,跟着这个视频一步一步走,相信在视频的最后你也可以制作出你的第一张a i图像大作。
好,那现在我们直接进入教程。首先我们就要确定自己的电脑配置,有独立显卡的p c是比较推荐的。虽然和显也能出图,但每张图需要等很久很久。当然如果有一张至少八g显存的显卡,你就会得到一个相对来说不错的体验。

显卡越好体验越好。当然如果你没有显卡或者配置不达标的话,也可以使用一个叫做利不利不a i的在线s d工具。这我们在后面也会讲到,当你确认电脑的配置之后,接下来就是环境的搭建了。之前搭建这个。
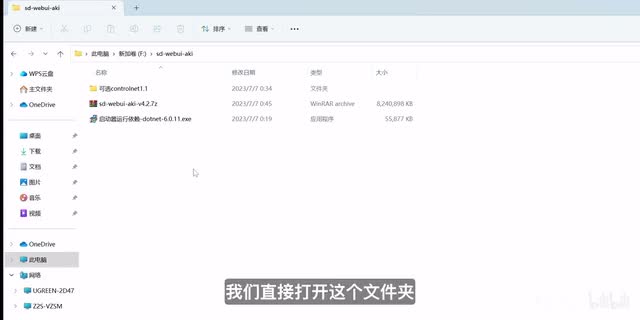
东西很麻烦,但是现在因为赛博菩萨秋叶老师的无私奉献,我们可以轻松的一键配置好所有的东西。首先我们先去下载安装包链接,我会放在功能区。下载好之后呢,我们直接打开这个文件夹,然后双击运行这个文件,按照说明进行安装,非常简单。结束之后我们直接打开这个一键安装程序,点击启动,然后就配置好了,叫出来这个浏览器界面。
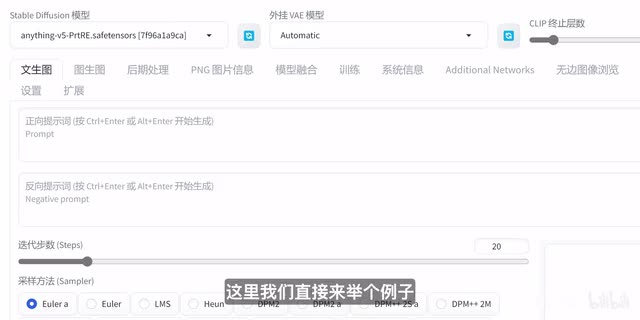
就是stable diffusion的本体。虽然看起来花里胡哨的东西有很多,但是一点也不用担心,入门绘图所需要的核心功能只有简单几个。这里我们直接来举个例子。首先确保我们在文生图这个页面,然后在提示词中写one girl,意思就是一个女孩。
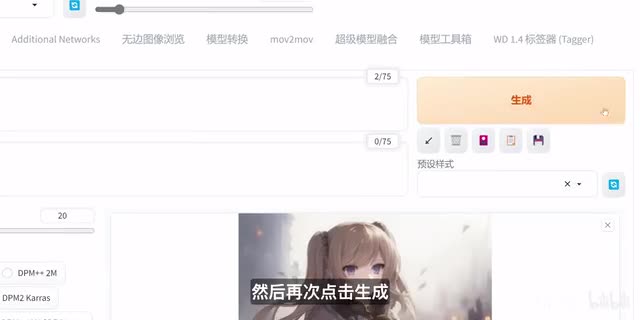
宽度和高度在这里我们都选择五幺二。接下来呢我们什么都不用管,直接点击生成,稍等片刻,这样图像就做好了,是不是很简单呢?接下来呢我们选择数据选择,然后再次点击生成,我们就会看到四个不同的女孩图像,你可以选择我们最喜欢的这一张。如果你想让图像变成十六比九的长方形图片,该怎么做呢?也非常简单。这里我们可以自由调节图像的高度和宽度。
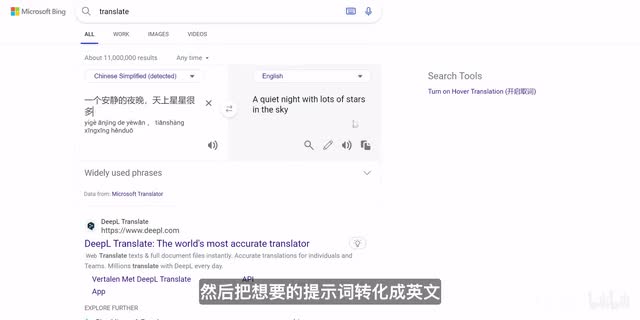
需要注意的是,高度和宽度越大,图像生成所需要的时间就会越长。所以一般显卡如果不是顶尖的,建议不要选择太高的分辨率,具体大家可以尝试一下哪个大小更适合自己。如果想要生成别的东西,我们可以尝试打开任何一个翻译软件,然后把想要的提示词转化成英文,最后再粘贴到提示词一栏就ok了。如果我们想要生成不同风格的图像,比如动漫风、写实风、建筑设计、古风等等,我们需要下载并且选择相对应的图像模型,也就是在这里的这个东西。
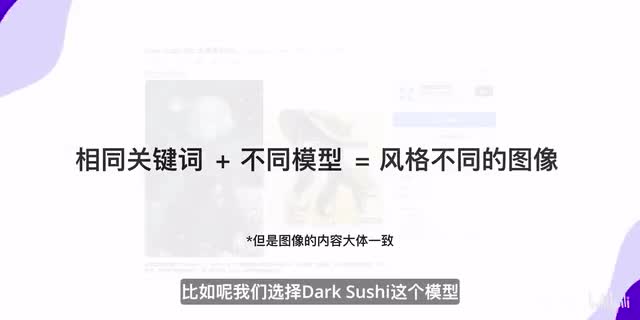
我们只需要知道,只要载入相对应的模型就可以生成类似模型中的图片。输入相同的关键词,选择不同的模型,生成的风格也是不同的。比如呢我们选择dark sushi这个模型,生成的图像风格是这样这样和这样的。又比如我们选择一个比较写实的模型,生成的风格是这样这样和这样。
那网上现成的模型非常之多,可玩性也很高。如果你没有魔法上网的体质,在国内呢我们可以去选择使用利布利布这个网站。去寻找模型。这个网站在国内玩ai绘图的话呢是非常方便的。
网站里包括了大量的线程免费模型,包括了stable的fusion模型、lora模型、textual inversion等等。大家也许不知道这些是什么东西,不过不要紧,对于我们新手小白来说,这个暂时没有那么重要。那这期视频呢我们就先来主要的聊stabled fusion大模型的下载和使用。在网站中找到右侧的筛选,选中check check point,然后想要的模型样式点击进入,然后在这里可以直接下载。

这边有几个比较推荐的模型,包括dream paper、dark sushi和any phone。这几个模型在ai绘图界的口碑是真的很不错的。生成的样式非常的精致,然后适合我们新手串口使用。下载完成之后呢,我们会得到一个后缀为c tensor的文件。

我们打开原文件里的models文件夹,然后选择stable fusion,接着将刚下载好的文件直接拖进来,点击这里的刷新,然后模型就可以找到了。如果你觉得这样很麻烦,或者你的电脑配置不能很好的支持stabled fusion,我们也可以直接在刚刚这个网站里选择想要的模型,然后点击加入模型库,然后点击右上方的在线。就可以直接在这个网页使用了,工具的还原程度是非常高的那虽然我们都没有讲到,但是其他的一些工具,例如图生图、laura选择,甚至是control net t都有,几乎就是我们的原原本本地的stable fusion,而且每天可以免费生成一百张图片啊,真心很不错。这个教程中我们展现的一些东西呢,在这里都可以直接使用。

选中模型之后呢,再去写关键词生成,你会发现新的图片已经有了刚刚我们在网站上看到的风格,但是这这这画风还是不太一样的。为什么别人用这个模型上的图片是这样的,而我生成的却是这样的呢?这个最主要的原因之一呢,还是我们的提示词写的不够好。想要写好提示词其实也是一门学问,我们在这个视频暂时不做赘述,更简单的方式就是直接在网上找现成的提示词和一些参数来出图。比如我们打开之前下载模型的lib lib v i网站,在下面的返图区,我们就可以看到很多已经通过这个模型生成的ai图像。
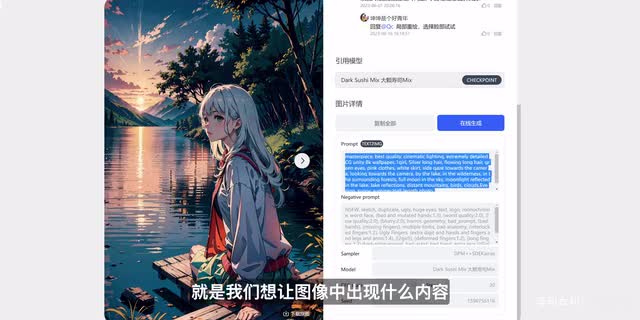
找到自己喜欢的图像,在右下角找到图片详情就可以看到线程提示词。第一个就是我们的关键词,就是我们想让图像中出现什么内容。第二个是反向。关键词,也就是我们不想让图像中出现什么内容。

现在我们先不要管其他的参数是什么意思,直接按照现在有的信息一个一个改过去就ok我们直接复制所有的信息,包括关键词采样方法、迭代步数等等,设置完成之后直接生成,可以看到这个效果是非常棒的。我之前呢也出过一期视频,来介绍一些非常不错的提示词资源网站。当然也包括了stable的fusion提示词资源。大家有兴趣的也可以去看看那些视频,在最开始用别人现成的提示词为基础来生成图像,然后在提示词中修改细节,是一个非常不错的方法去学习这个工具。
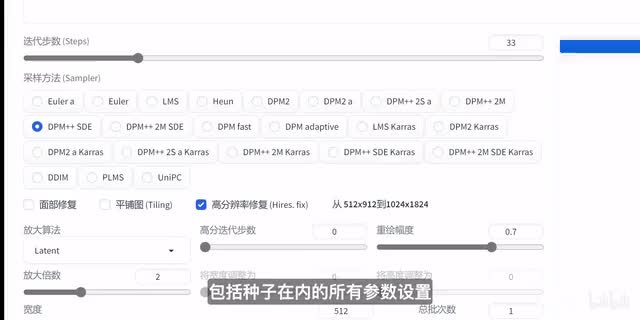
这里需要提到的一个小技巧是,如果把下面的种子设置为负一,其他不变,那么每次我们点击生成时获得的图像都是不一样的,如果每次点击时,随机种子不是负一,而是一个固定的值,那么每一次生成时的图像都会是一样的,包括种子在内的所有参数设置都会影响生成的图像。尝试改变包括采样方法、迭代步数等参数,你也许会得到非常不一样的效果。到这里,你已经初步上手的ai图像,当然可以隐约感受到stable的fusion到底有多强。然而,这仅仅只是冰山一角。

使用stable fusion,我们可以控制人物动作,控制画面的构图,控制景深、视频生成,高清放大等等等等,只有你想不到,没有他做不到。这些内容我也会在以后的视频给大家一一呈现,有兴趣的同学不要忘点关注,这样我更新的第一时间你就可以看到了。我是艾瑞,我们下期视频再见,拜拜。




