
a i视频创作的热潮是从图生视频开始的。输入一张静态的图片,a i就能让它动起来,生成最长可达十几秒的一段动态视频,光影自然细致,细节栩栩如生,运动也十分流畅,堪比某些付费视频素材网站上出售的高质量控制内容还可以天马行空,不管是现实存在的还是不存在的。一下子把做了多年特效的up主我给干沉默了。这种几乎可以重塑剪辑后期产业的进展,让大家将关注集中在了一系列图像视频的a i工具上。如最最早出现的running n two,华人学霸打造的皮卡等等,这强大的工具很受欢迎。唯一的缺点可能就是要花钱,还挺贵,一个月大几百的订阅费用,你下得去手吗?但就在去年年底,stable diffusion的开发公司,开源模型界的扛旗手stability ai发布了他们的视频模模式able video diffusion,简称s v d,成功依靠其免费可本地运行的特性与不输主流产品的质量,在a i视频领域占据了一席之地。和刚刚介绍的一样,它可以帮助你从一张静态图片乃至一段提示词,就去生成一系列丝滑流畅且富有风格特色的视频分镜。你可以用它做动画,做视频素材,甚至是会有剧情的电影短片连连。

是的,宣传片里都有它的摄影出现,你想知道它要怎么用吗?在今天这期视频里,我们就来聊聊它的安装方法和运用精髓,以及借助各种工具实现视频的运动设计、智能抠像以及补帧放大等功能的方式,看完这期视频,无需在付费应用里购买价值几百的会员,在自己的电脑上你也可以轻松零成本的体验a i生成视频的乐趣。教程内容比较充实,我猜你肯定不只要看一遍,建议先点个收藏再开始接下来的学习。准备好了吗?我们开始这节课的s v d探索之旅吧。按照惯例,从它的下载与安装开始讲起吧。你可以在stability ai官方的honeybee模型页面下载到最新版本的s v d模型。最早发布的有两个版本,它们的区别是用于训练的视频帧数不带x t的原版是在十四帧视频上训练的,而加了x t的版本有额外在二十五帧的视频上进行过微调,理论上运动会更加流畅自然。我会推荐你下载这个最新的一点一版本x t模型,以后也完全有可能有更新版本的模型。试出有线用最新版下载了模型以后,要去哪里使用它呢?绝大多数s v d的玩家会使用空调u i中的工作流来运行模型。
目前最新版本的功能u i已经源。生支持了s v d的相关功能界面。如果你有conf u i的操作经验,可以直接将s v d模型放置进coffee u i的check point文件夹内和其他的绘图模型一起就可以使用它了。如果你之前完全没有接触过过v i i i也可以不用来的。我在这个视频下面将完整的copy i程序与s v d模型打了个包,并上了这个视频里面会用到的所有工作流。你可以给这个视频一键运行,然后在这几个按钮下面的简介区里找到他们的下载方式,下载并解压后,双击这个run nvidia g p u,并按照后面讲解的方式去运用它。你也可以轻松在自己的电脑上使用这个模型。另外一个可以用上s v d的方式,则是最近新进流行起来的forge u i。

这个出c controller作者之手的web u i改良版,将s v d功能作为了一个内置扩展植入了进去。对习惯web u i的用户来说,操作或许会更加友好。使用这些方式在本地运行s v d模型时,对g p u的性能是有一定要求的。根据实际测试,绘制十四帧视频的显存需求大约在十二g b左右,绘制二十五帧会更高,低于这个水平的设备可以运行,但有报显存降速的风险。在生成视频的过程中,我们会用到的其他。工具也可能会产生额外的显存占用。因此如果你有一块显存在十六g以上的g p u,就可以本地无压力畅玩s b d一类的视频生成模型了。例如支持了本期教程制作的微星显卡,最新上市的g false r t x gaming零零魔龙系列的四零七零钛super就拥有十六g的超大显存与接近四零八零的核心性能与绘图速度,保证s b d这种本地部署的视频模型的生成体验。

根据实测,以它的性能系统绘制一个标准的幺零二四乘五七六分辨率,一四真的视频只需要大约四十秒的时间。你可以以它作为标准衡量你使用s v d生成视频的速度。当然并不是说低于这个配置线就和s v d无缘了。你还可以通过它的官方在线应用这个stable video网站来运行它。但它不是本地运行的,免费的额度用完以后也需要付费购买credit。我们今天并不会着重介绍,但要是你看了接下来的内容感兴趣,也可以拿它去尝试一下。那接下来我们就从最基础的图像视频功能开始,了解如何在一分钟之内实现一个画静为动的操作。com p u i里加载这个图片视频的s v d工作流,它的结构非常简单和最基本的文生图有诸多。
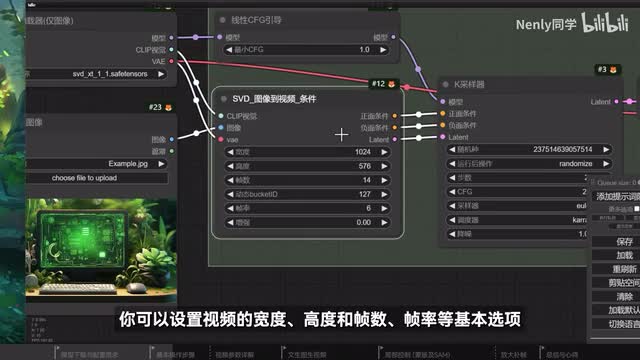
相似之处。首先我们在最左侧的check point加载器这里加载刚刚下载下来的s v d模型。随后在下方的图片加载器处输入一张想要让它动起来的初始图片,可以直接从电脑上的文件夹把图片拖拽进来。这张初始图片的尺寸最好和你最后生成的视频尺寸比例保持一致。那视频的尺寸在哪里调整呢?看到右边这个条件节点,在这里你可以设置视频的宽度、高度和帧数、帧率的基本选项,其中视频尺寸我会推荐按照默认设置的幺零二四乘五七六来。因为s v d模型是在这个尺寸的视频上训练的,所以我们也应该尽可能把初始图像裁剪到十六比九的比例上。视频的帧数决定了视频的总长度,同样会根据你选用的s v d模型而已。原版的最佳选择是十四帧,x t版则是二十五帧,而f p s代表每秒播放的帧数,可以维持默认六不变。
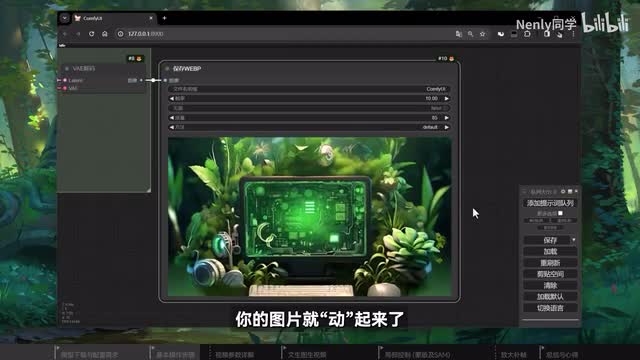
这样会生成一个约四秒左右的视频。随后再在右边设置k采样器里的各项参数,这些参数和绘图时的作用基本一致,如果你不了解它们的详细作用,也可以维持默认不变。设置完毕,点击一下边栏上的添加。提示词队列等待读条完毕,在最右边的保存窗口里就会输出一段视频,你的图片就动起来了。你可以在coffee u i根目录的输出文件夹里找到这些图片,也可以右键点击将它保存下来。很简单对吧?不过按照默认的这一套参数运行,有时生成的视频效果会有点奇怪。碰到类似这样的问题时,我们就得去更改下面这一系列和视频生成有关的参数了。这其中有三个是你需要重点关注的。
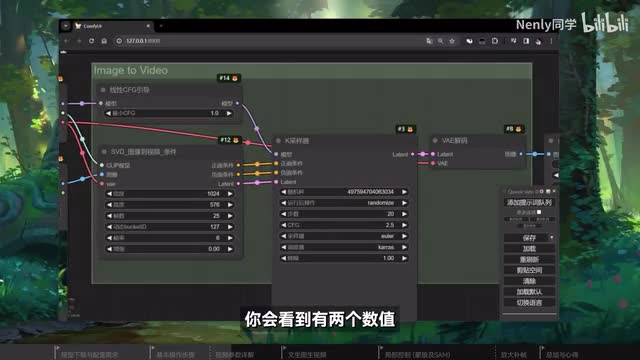
首先是这个运动统i d,它是s v d模型里最直观的控制视频运动幅度的参数,默认幺二七范围从一到二百五十五越大运动幅度就越剧烈。如果运动太过剧烈导致画面变形了,就降低它。反过来,如果画面不怎么动,就可以适当增大它和运动间接相关的另一个参数是这两个节点里的最小c f g和k samper里的c f g数值。c f g是五分类器指导的缩写,和图像绘制中一样,在控制绘制内容与条件的相关性,你会看到有两个数值是因为s v t采用了随帧数动态控制c f g的思路,在绘制第一帧内容的时候应用最小值。然后逐渐增大到最后一帧时变成k三play的最终c f g,以此来适应视频不断变化的画面。官方解释它的作用是保持原始图像的忠实程度,低则画面会更更自然,更高的画面会更稳定。如果实际嬷嬷中发现它不会影响大的运动过程,但会影响运动推导的细节。如果你的画面里出现了类似这样不成一团的成分,就可以适当增大。

另外c f g太高或太低也会导致画面的异常。如果你上这种情况,就应当把它拉回到正常的区间内。还有一个有用的参参数是这个增强水平,直接理解就是添加到图片中的变成了它越高,视频与初始帧的差异就越大,所以也可以通过增加它来获得更多运动。但它的实质调整很敏感,一般不超过一,不同场合使用的水平就不同,多数时候你可以让它保持认识,但当你在使用与默认尺寸不同的视频尺寸时,最好把它增加到零点二零零点,否则画面就会有很大概率会是错乱的。了解了这些,你就可以尽情享受s v d的便利了。有一张图片就能做出一段生动的视频素材来。不过。这里我们幻想的用嘴拍视频好像还有一段距离,毕竟还得有图片对吧?但其实文生视频和图像视频本就只有一线之隔,而文生图的技术在过去一年多的锤炼里早就已经高度成熟了。
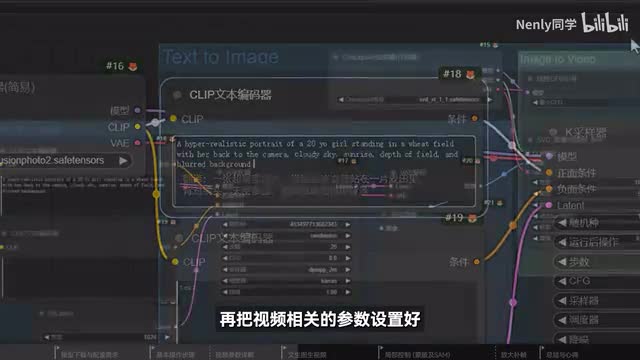
因此我们可以用一套非常流畅的文字图像视频的丝滑连招,实现从文字到视频的生成控制,在同比u i中加载这个工作流。比起刚刚的图像视频,它只是在前面多了一个文生图的节点组合,在最左边的模型加载器这里选择一个合适的绘图大模型,无论是s d一点五还是excel的都可以。然后在上方的文本编码器窗口里用英文输入一段画面的描述。按照刚刚提到的方法,再把视频相关的参数设置好,点击生成,它就会在第一个节点组里完成生成图片的工作。随后立刻将图片转化为一个动态视频,看是不是也非常流畅轻松。其实s v d用起来是非常自由的,原则上只要你能给它喂一张图片,它都能帮助你让图片动起来。因为a i视频模型的训练就是像a i大量投喂视频片段,让他学习这些视频在不同时间节点上的静态帧的差异。久而久之视频的所。
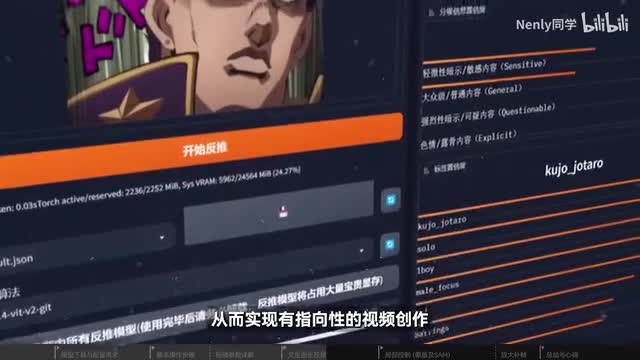
有动态在他的眼里就会变得有迹可循。这个时候像a i输入一张静态的图片,它就会有能力去预测接下来一段时间内它会发生的画面运动。也因此决定这个视频成色最重要的参数其实就是这张图片。如果你收看过之前我的频道里更新的关于stable division的应用教程,你还可以利用多种手法绘制符合需要的图片,从而实现有指向性的视频创作。正好微信近期在各大平台举办了一个ai绘图创作比赛。希望大家可以通过stable division,围绕龙与微星显卡的主题,创作一幅a i商城作品。作为全球电竞产业的翘楚品牌,微星的显卡产品也是众多a i g c爱好者们有力的创作工作。近期发布的false r t x四零super系列显卡,这为a i绘图创作注入了强大的动力。
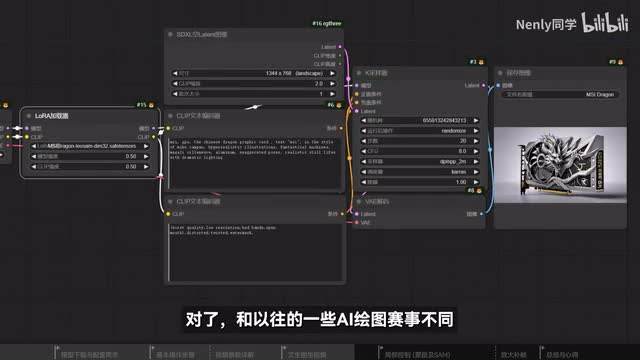
微信筹办这次比赛非常用心,不光体现在他们准备的奖品上,就是三块开头我们介绍过的具有十六g大显存的四零七零钛super魔龙显卡。为了帮助大家更方便快捷的创作出符合要求的作品,他们还特地聘请了专门的模型训练师,把微信全系列显卡的形象变成了laura。只需要简单的在生成中加入laura,再敲几个提示词,就可以把一块生动的微型显。植入到作品中了。对了,和以往一些ai绘图赛事不同,他们这次的征集范围不仅包括了图像作品,还有视频。有了这样一张静态的图片作品以后,我其实非常推荐你将它导入到s v d里跑一跑,因为它有些时候可以给你制造不少惊喜。在绘制的过程里,你还可以使用controller i p adapt等工具辅助进行风格化的延伸,从而创作出更富有特色的作品。这不是今天的重点,但如果你想学习该怎么做,不妨看看我们之前更新的一些视频。

而在这种强风格属性的作品里,s v d同样可以给你惊喜。看来s v d跑一跑,一个水墨流转、山水变换的效果也就做出来了。然而使用s v d出图的一大难点在于,它的动态内容某种程度上是不可控的。你想让它动哪里动什么,其实现阶段还是比较难去控制的。所以要获得一个令人满意的结果,我们总是需要反复收看,然后反复翻车。不过得益于conf u i里各种功能强大的自定义节点,我们可以用一些较为有效的手段控制生成动态内容的区域,从而提高视频的可塑性。这样你用它生成的视频就会更加听话了。首先。

模板在绘制静态图片的时候,我们可以靠蒙版中会精确控制a a i只重绘画面里的其中一小部分。而在生成视频时,我们也可以用类似的手段,让一个视频里只有一小部分动起来。软尾之前有一个大热的运动笔刷功能,就可以做到这样的效果。我在coffee u i里用一系列的节点为你复刻了一下加载这个动态笔刷的工作流。同样在最左边这里导入初始图片,右键点击一下图像,选择在遮罩编辑器中打开,在打开的界面里用笔刷涂抹你想要画面运动的部分,左下角有选项可以调节笔触大小,画错了可以按清除按钮重来。画完以后点击右下角的save to know,然后再像刚刚一样设定好视频参数运行即可。看我就通过这样的方式严格限定了这个视频的动态范围了。这个工作流里还设计了一些辅助性质的选项,这里有两个开关,分别控制蒙板的反转和边缘的羽化。

反转会把蒙版控制的绘制区域倒转过来,默认是被关闭的。但如果你将它启用了,那你所图画的区域就会变成固定不变的区域。在边缘羽化,默认是开启的目的是为。让这些区域和动态区域的过渡变得更加自然。如果你看到了生命的接缝边缘,可以在这里再增大一点数值。这种哪里要动画哪里的感觉还挺舒适的。但在一些更复杂的星星里,靠手图蒙版控图的精确度还是太低了。这个时候我们就可以求出一些非常厉害的智能抠图工具,来实现更精确的能控制。

这里有另一个工作流,运用到了coffee二中的segment anything组件,通过两个功能强大的ai抠图模型,可以帮助我们智能识别并选定图像中的区域。其中g a n i d i n o是一个强大的零样本检测器,能够根据文本描述来检测图像中的任意物体,生成一个大致的区域范围。而sam可以在这个区域里做更仔细的分割,把这个东西抠出来并生成相应的模板。在web u i里有一个非常受欢迎的扩展segment,anything就用到了这项技术。而同比二也有类似的功能节点,用它们在静态图片上智能抠图早就轻而易举。把它们嫁接到s p d的工作流里,会有什么奇妙的化学反应呢?这个工作流的使用方式和刚刚那个差不多,但不需要手图蒙版了,只需要在这里。用提示词描述你想要动起来的画面元素,再按照刚刚讲的方式设置好视频参数看,它就会智能的识别出画面里的对应位置,并且使用和刚刚类似的手段生成蒙版让它动起来了。这样选取区域精确度和效率都比手画高多了。
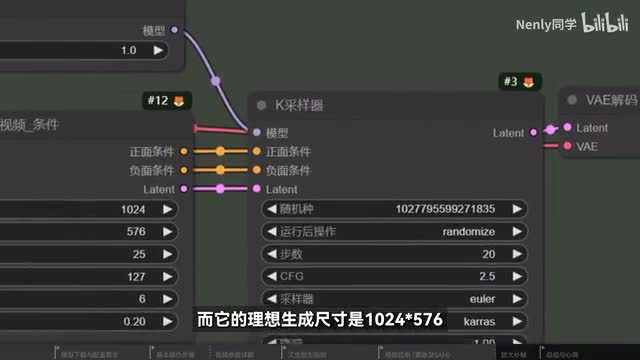
但我做了不少测试,在勾取区域太小的情况下是不会有动态效果的。而在我们现实生成区域的情况下,不少动态内容也有可能会出框,造成比较违和的观感。这种情况我建议你降低几个控制动态水平的参数再来试试看。严格来说s v d生成的视频质量其实并不能算非常高。比如它默认生成的帧率只有六,但常规的互联网视频帧率一般是二十四到三十帧,而它的理想生成尺寸是幺零二四乘五七六乘以一点八七五倍,才是我们常见的幺零八零p清晰度。但这些都不是问题,因为我们已经有很多成熟的视频超分放大与补帧差值手段来升级视频的清晰度和流畅度,在coffee u里就可以实现。再提供一个工作流,你可以在前面导入s p d生成的成品视频,然后在这里设置放大宽度、帧数等信息就可以调用。r e s r g m模型进行放大及film型做补帧。
这里我也设计了一个小开关,如果你只想单独补补或者放大都可以用它来控制。除除此之外,我们在上期视频里介绍过的这个film扩展里面也可以使用放大的视图功能,用它来操作也是相当简单的。如果你有预算,还可以使用一些更成熟的商业软件,如top s video来实现类似的效果。另外如果你使用copy i自带的s v d工作流生成视频,默认的保存格式是weapon图片,可能不是很兼容一些视频编辑应用。这个时候我会建议你安装这个video hyper suit的节点套件,使用它里面的这个video combine节点替换默认的weapon保存节点,就可以在下面把输出格式设置为m p四等更常见的视频格式了。总的来说,s v d是目前开源领域最具竞争力的视频模型。它的操作十分简单,能和已有的ai绘图流程无缝接轨,应用场景可能也远比你想象的更加丰富。在很多传统渠道的媒介里,一些纯静态的展示场景就可以通过s v d非常轻松的转换为动态的演示。

无需进行复杂的建模,后期它对内容创作也是有革命性意义的。我在网上看到了很多借助s p d。生成的动态视觉乃至短篇作品真的非常惊艳。不过嘛它的短板和缺点也是很明显的,或者说现阶段几乎所有视频生成模型的短板就是可控性差。有如s d发展早期,我们只能靠不断调整魔咒和种子来获得更好的结果。现阶段想获得一个符合预期的s v d视频,也只能靠不断微调这些参数来玩抽卡游戏。但好在这个卡抽的还挺快的,平均每半分钟到一分钟就可以生成一个视频。目前通过长度视频,视频比起tm mad的项目都要快,而随着技术的发展,它只会变得越来越快。

像英伟达官方开发的t s r t加速库,目前就已经支持了s v d的生成加速度,经过它编译的模型的生成,视频还能再快上百分之十。这套技术方案目前已经相当的成熟。我们之前也做过一期专题内容,发现它对a i绘画方面的加速效果非常显著。我们可以让显卡的性能提升三倍以上,借助strange diffusion等技术,还能实现每秒百臻以上的实时转换。如果你想了解更多,可以通过屏幕上的链接收看之前的视频。毕竟那会儿现在的t s r t已经完成支持了,包括lora c r r n。animation等常见应用,而且在市面上所有常见的s d操作界面里都是通用的。此外我摸索s v d的过程中,也稍微把握了那么一点点抽出好卡的秘诀。

当我们的画面里有比较突出的人物主体,比较显著的动态元素,乃至比较有空间层次感的场景时,它产出自然流畅的运动的概率就会高很多。而s v d生成一些静物远景的时候,出好卡的概率更高。但要他去画一些细致的动作,就很容易出现像这样非常不真实、不自然的结果,说白了和早期ai绘图画不好手脚是一样的。不过,这些模型肯定会不断迭代进步,在清晰度、关联性上做得更好,将来如果有controller级别的视频控制网络出现,我们刚刚提到的这些问题一定都会迎刃而解。在说未来可期的同时,它已然提供了视频创作的一种崭新可能性,让每个人都有机会成为自己的大片导演,更低成本却更加丰富的视频素材,也会为现在的内容产业注入更多新鲜血液。以上就是本期视频的全部内容了,如果对你有帮助,请别忘了给这个视频点个赞、投个币,一键三连支持鼓励一下,或者把它的供给的视频对的。视频创作感兴趣的小伙伴,如果你对一些其他的a i视频工具感兴趣,也可以给这个视频所在的内容合集点个订阅,后续相关内容都会在这里更新。这里是哪里?感谢看到最后,我们下期见喽,拜拜。




