欢迎收看人人都能懂的a i大模型科普课,第二节之啥是大禹语言模型。二零二二年十一月三十日open ai发布chat g p t,一跃成为当下最快达到一百万用户的线上产品,也带动大语言模型成为了时下热点,更多a i聊天助手雨后春笋一般出现在大家的视野里。那你真的了解大语言模型吗?大语言模型也叫l l m linh language model,是用于做自然语言相关任务的深度学习模型。给模型一些文本内容输入,它能返回相应的输出,完成的具体任务可以是生成、分类、总结、改写等等。
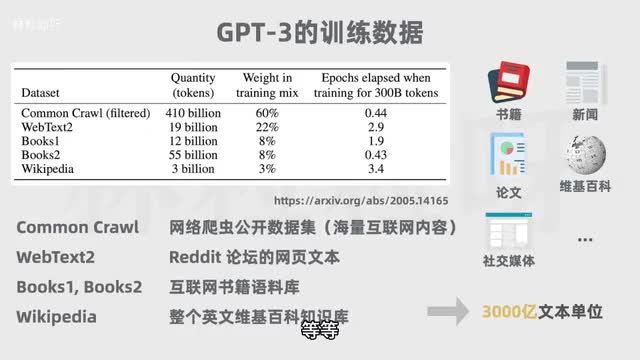
单元模型首先需要通过大量文本进行无监督学习。以g p t三为例,它的训练数据有多个互联网文本语料库,覆盖线上书籍、新闻文章、科学论文、维基百科、社交媒体帖子等等。借助海量的训练文本数据模型,能更多了解单词与上下文之间的关系,从而更好的理解文本的含义,并生成更准确的预测。但大语言模型的大指的不仅仅是训练数据巨大,而是参数数量巨大。
参数是模型内部的变量,可以理解为是模型在训练过程中学到的知识。参数决定了模型如何对输入数据做出反应,从而决定模型的行为。在过去的语言模型研究中发现,用更多的数据和算力来训练具有更多参数的模型,很多时候能带来更好的模型表现。这就像要a i学习做蛋糕,只允许a i调整面粉、糖蛋的量和允许a i调整面粉、糖、蛋、奶油、牛奶、苏打粉、可可粉的量,以及烤箱的时长和温度。

后者由于可以调整的变量更多,更能让ai模仿做出更好吃的蛋糕。随着参数的增加,他甚至有能力做出别的玩意儿,创造一些全新的品种。所以如今语言模型的参数数量可能是曾经的数万倍甚至数百万倍。以open i的第一个大模型g p t一为例,它有一点一七亿个参数。
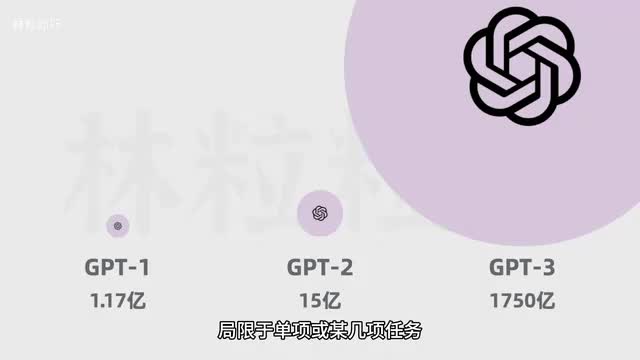
到了g p t二参数有十五亿个,而g p t三的参数又增长到了一千七百五十亿个。这让大模型不像小模型那样局限于单项或某几项任务。而是具有更加广泛的能力。比如在这之前,我们可能要训练单独的模型,分别去做总结、分类、提取等等任务。
但现在一个大模型就可以搞定这一切。像chat、g p t cloud、文心一言言通义千问等ai聊天助手都是基于大语言模型的应用。如果说二零二二年年底chat g p t的惊艳亮相,是大语言模型公众认知被显著提升的里程碑。那它技术发展的里程碑其实要回溯到二零一七年。

二零一七年六月,谷歌团队发表论文attention is all it,提出了transformer架构。自此自然语言处理的发展方向被改变了,随后出现了一系列基于transformer架构的模型。二零一八年open a i发布g p t一点零,谷歌发布bert二零一九年open a i发布g p t二点零,百度发布a i一点零等等。所以大语言模型的发展早就如火如荼了,并不是像很多人以为的到了二零二二年才有所突破。

但因为chat g p t直接向公众开放,而且能让用户在网页上用对话的方式进行交互,体验很流畅丝滑。大众的目光才被吸引过去。chat g p t背后的模型,g p t首字母分别表示generative prechamber transformer、生成式预训练transformer,也表明transformer是其中的关键。所以要了解大语言模型就无法跳过transformer。
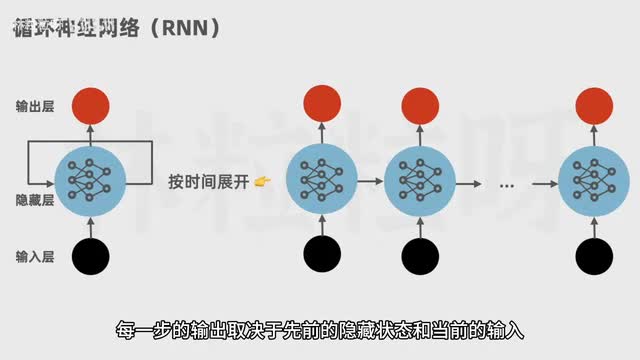
在transformer架构被提出之前,语言模型的主流架构主要是循环神经网络,简称r n。r n按顺序逐字处理,每一步的输出取决于先前的隐藏状态和当前的输入。要等上一个步骤完成后才能进行当前的计算,因此无法并行计算,训练效率低。而且呢r n不擅长处理长序列,也就是长文本。

由于r n n的架构特点,此时间距离越远,前面对后面的影响越弱,所以它难以有效捕获到长距离的语义关系。但在人类自然语言中,依赖信息之间距离较远是很常见的情况。比如这句话里正确预测下一个词的关键是距离很远的广东。如果用r n生成后续内容,到了这里的时候,他可能已经把前面的信息忘没了。
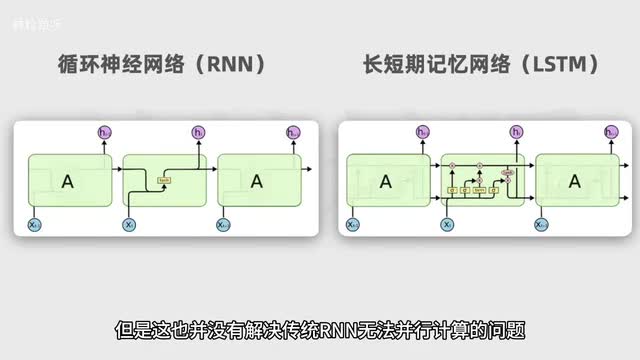
为了捕获长距离依赖性,后来也出现了r n的改良版本,l s t m长短期记忆网络。但是这也并没有解决传统r n无法并行计算的问题。而且在处理非常长的序列时也依然受到限制。后来transformer他的七彩祥云出现了。
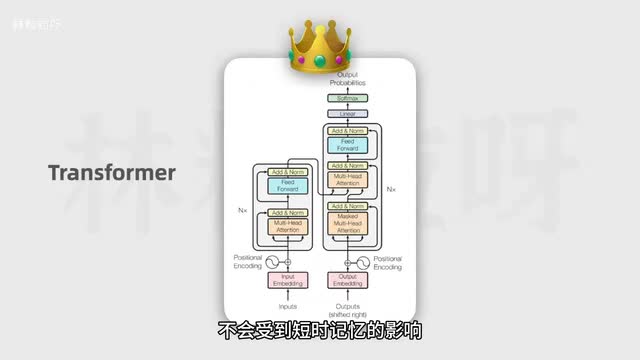
它有能力学习输入序列里所有词的相关性和上下文。不会受到短时记忆的影响。能做到这一点的关键在于transformer的自注意力机制。也正如论文标题所说。

attention is all you need. 注意力就是你所需要的一切。简单来说。transformer在处理每个词的时候,不仅会注意这个词本身。以及它附近的词,还会去注意输入序列里所有其他的词。
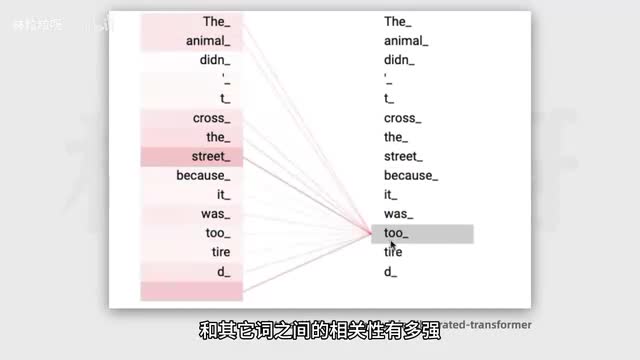
然后其余每个词不一样的注意力权重。权重是模型在训练过程中通过大量文本逐渐习得的。因此transformer有能力知道当前这个词和其他词之间的相关性有多强,然后去专注于输入里真正重要的部分。即使两个词的位置隔得很远,transforming依然可以捕获到它们之间的依赖关系。
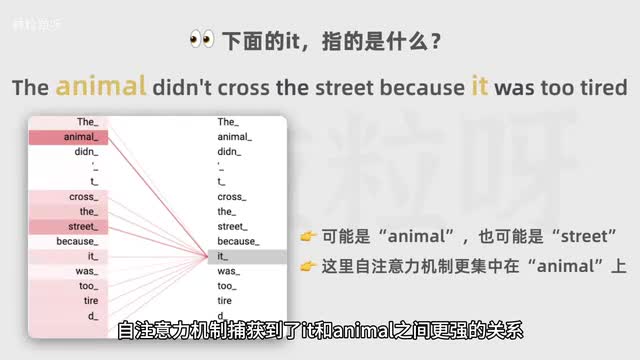
比如这个例子,单从语法上来讲,it可以指的是离得更近的street,也可以是离得更远的animal。这里自注意力机制捕获到了it和animal之间更强的关系。因此更集中在animal上。除了自注意力机制,transformer的另一项关键创新是位置编码。

在语言里顺序很重要,即使句子里包含的字都是一样的,但顺序不一样也能导致意思大相径庭。这也是为什么自然语言处理领域会用序列这个词,因为它表示一系列按照特定顺序排序的元素。前面提到r n和人类阅读文本一样,对输入序列同样是按顺序依次处理。这就造成了训练速度的瓶颈。

因为只能串行,没办法并行,也就是没法同时去学习所有信息。transform再把磁输入给神经网络前,除了会先对词进行嵌入转换成向量,也就是把磁各用一串数字表示,还会把每个词在句子中的位置也各用一串数字表示,添加到输入序列的表示中。然后把这个结果给神经网络,那模型既可以理解每个词的意义,又能够捕获词在句子中的位置,从而理解不同词之间的顺序关系。借助位置编码词可以不按顺序输入给transformer模型可以同时处理输入序列里的所有位置,而不需要像r a n那样依次处理。
那么在计算时,每个输出都可以独立的计算,不需要等待其他位置的计算结果,这大大提高了训练速度。训练速度一快,训练出巨大的模型也不是那么难了。自attention is all you need。fiber之后,transformer以及它的变体已经被普遍运用在大型数据集上来训练大语言模型。
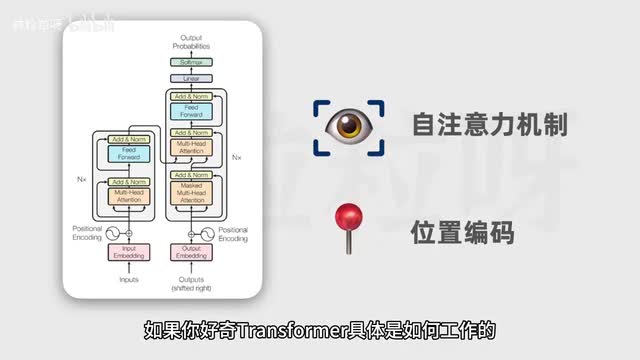
所以呢transworld架构对我们当下能拥有那么多牛叉的大语言模型功不可没。如果你好奇transformer具体是如何工作的,以及chat g p t背后的g p t模型是如何生成文本的。下一节会有详细的介绍。我们下个视频见。




