
不知道你会不会经常有这样的一种错觉,二十世纪前半叶的人是生活在一个黑白的世界里的,他们的世界中没有颜色,分辨率很低。为了克服这种错觉,你常常要有意的告诉自己,他们生活的世界跟你现在的一样,全真色彩视网膜像素波尔和薛定谔的动作也不是量子态的,他们的世界同样流畅顺滑,走路也不是一卡一卡的,好吧。同样对我五岁的儿子来说,他老妈的青春岁月可能也是发黄的,高斯模糊的。因为所有那个时代的电影都是这样的这样的,这样的。为了让我们的青春重新回到四k我们需要a i。a i是如何把模糊不清的老照片变回四k的呢?这就需要用到一种技术,a i超分辨率。现在想象你有一张二五六乘以二五六的图片,你把这张图片放大十六倍,他就来到了幺零二四乘以幺零二四。

图片中的每个像素现在变成了十六个。如果你不做任何处理,他就可能是这样的这不是你想得到的结果是。你决定给这些像素重新添加一下颜色,该怎么做呢?最容易想到的办法就是把相邻的两个像素的颜色值相加一下,然后除以二,于是你就得到了一个新的颜色。电脑也是这样做的,这种算法就叫做差值。利用差值算法我们可以补充很多像素的颜色,让像素过渡起来更自然。但是简单的插值方法会导致边缘均匀过渡,看起来很模糊,和实际人的主观感受不符。很明显锐利的画面需要像素值上更陡峭的过渡,你这样一平均,边缘反而变得更模糊了,怎么办呢?如果修复图像的是人,我们可以自己手动来精修。

我们知道图片上是什么,所以可以有意加强边缘和对比。但是电脑对真正的图片一无所知,它只有零一零一,也就无法根据图片内容做出调整。当然这仅限于二零一几年之前。二零一四年深度学习算法横空出世,让电脑进入了图片,但是c n n可以提取图片特征,于是。电脑终于知道你照片上的猫是一只猫了。接下来生成对抗网络干实现了ai作画。a i修复就不再仅仅是填补一些像素了,它可以检测边缘,重新创造细节,于是a i图片修复出现了质的飞跃,这是real e s r干的修复效果,看起来是不是还不错。

紧接着就是大模型时代了,ai绘画开始达到以假乱真的地步,而开源免费的程序也让普通人拥有了ai创作的机会。a i小姐姐泛滥的时代来临了,创造这种奇迹的是stable diffusion。但是你在跃进a i小姐姐的闲暇,有没有想过这样的一个问题,stable diffusion到底是如何作画的呢?它是像我一样勾线上色,然后完成一部作品的吗?并不是的。stable diffusion底层使用的是diffusion模型,它用了一种和绘画八杆子打不着的自然现象,扩散。什么是扩散呢?这是一杯清水。现在我们在水滴中滴一滴墨汁,你会看到什么?墨汁在水中逐渐散开,最后和水融为一体,整杯水变成了一杯深色的水。现在我来问你一个问题,我给你一杯深色的水,让你回到一开始刚刚扩散的样子,你做得到吗?好吧,可能除了信条中的人,谁也做不到这一点。

商是不可逆的,散开的墨水不可能完全回到之前的样子,但是或许我们可以找到一点点规律。扩散是由布朗运动引起的。为了寻找扩散的规律,我们可以把扩散的过程拍摄下来,然后分成一帧一帧的图片。仔细观察这些图片,我们会发现每一张图片与上一张图片比起来,墨水的威力都会更散开一点点。废话好吧,这种散开遵循什么物理法则呢?朗之万方程朗之万方程是是什么?物理学家保罗朗。之外在一九零八年搞出来的。简单来说就是布朗运动粒子平均运动位置离原点距离的平方和时间成正比。

这意味着我们可以根据这个规律推算上一个时间点粒子可能的位置。但是请注意平均这两个字儿,这意味着这只是在大量粒子运动下计算出来的平均值。每个粒子的位置到底在哪里还是不知道。这就需要另外一个数学概念了,这个概念叫高斯分布。啥是高斯分布?如果你把全世界人的身高做一个统计,以横轴代表每一个身高区间,纵轴代表身高处于这一身高区间的人数就构成了一个直方图,然后你就会发现它形成这样的一个形状,大部分人集中在中间这个区域,越靠近两边人数就越少,但是下降速度也会变得平缓,这就是高斯分布。高斯分布也叫正态分布,为什么叫正态分布呢?因为它太常见了,很多大数据量的分布都是高斯分布。比如身高,比如体重,比如收入,比如高斯分布。

扩散也。遵循高斯分布。也就是说一个墨水的微粒在下一个时间点出现的位置,概率上是遵循高斯分布的。而更妙的是,如果时间间隔足够小,它在上一个时间点曾经所在的位置也是近似高斯分布的这意味着什么?这意味着这从计算上是可逆的。如果我们知道在某一个时间点微粒在水中的位置,是有可能反推出上一个时间点微粒的位置的。当然只是有可能。因为高斯分布是一个统计学上的概念,是一个出现概率。
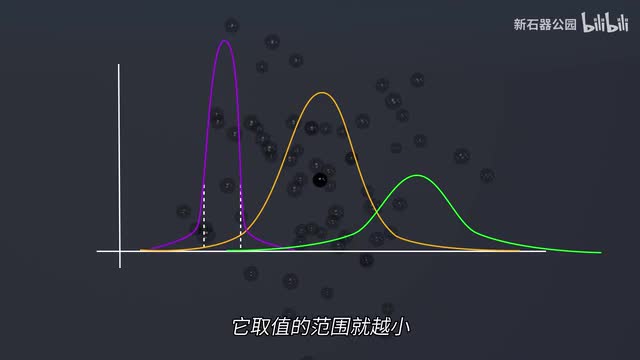
我们不可能确切知道每一个微粒的位置,而且只知道是高斯分布是没用的。因为它可能是又高又瘦,也可能又矮又胖。专业点说,它的均值和方差我们无法确定,也不知道它长什么样。我们希望它尽量是一个又高又瘦的位置,因为越是是高值的,范围越越小,我们越容易确定的位置的。现在你知道了,虽然你的确不能完全繁衍墨水的扩散过程,但是反推大量微微的运动过程还是没有问题的。特别是我们知道成千上万个的。墨水散开的视频以后,你是可以想象出墨水没有散开之前是什么样子的。

a i的训练过程也是一样的,首先我们有一张原图,然后我们逐渐在图中添加噪点,其实就是像素上的色值根据高斯分布逐渐扩散的过程。每次散开一些我们就保留一张当前的图片,直到最后完全变成一片看不出来的噪点。这个时候我们告诉a i这片什么也看不出来的噪点原来是什么,让它把原来的样子画出来。呃,这好像有点为难人呢,但是有了上面关于墨水扩散的经验,我们就可以贴心的提供一点帮助。a i不需要一次生成出最初的图片,它只需要生成出最后一张图片之前的那张图片就可以了。于是a i调整造点的分布,将它调整后的分布跟我们给它的图片进行对比,反复尝试直到收敛成正确的分布,再往前一张走。这样最终一张一张图片生成下去,来到最初的图片,在经过无数张类似的图片图片之后我。

可以说给我来一张画吧,a i就可以直接运行这个生成图片的过程,从一堆噪点中反向扩散出一张画了。就像你从一杯深色的水中想象出墨水散开之前的样子一样,深色的水是伤最高的土,就像全是噪声。然后每次迭代反向扩散,就像是根据当前墨水的状态推测前一个阶段水的状态,最后得到墨水没有散开前的样子,也就是图像最原始的状态,这就是diffusion模型作图的过程了。既然stable diffusion可以从一堆噪点中反向扩散出一张完美的图,我们直接给他一张有很多噪点的图片,让他去猜一猜原来的图片是什么样子。他能不能搞定呢?太能搞定了,咱这么多年就是这么训练过来的嘛。所以如果这张有很多噪点的图片,是一张老胶片,你就解锁了stable diffusion的新能力。老电影修复stable diffusion做老电影修复具有很多先天的优势,除了它的训练方式先天对于去噪点就有很好的适应能力之外,它本身也是一个a i大模型。

也就是说它像chat g p t一样,经历了大数据的洗礼,跃进世间万物。这让他了解了世间万物的样子,相当于有了超级强大的脑补能力。如果画面中有什么已经破损了的信息,让stable diffusion直接给补出来不就完美了。说到这里,你是不是已经跃跃欲试了,想用stable division去修复一下自己的老电影了。等一下理想很骨感。现实可能很骨折。stable diffusion本身是一个图片生成的a i它的大量训练也是基于a i生成图片的。

所以现在你把它用在老电影修复上,如果不好好拾掇拾掇,可能会遇到不少问题。我们刚才说了stable diffusion跃进世间万物遇到损失掉的图像它可以脑补出来。但是啥是损失掉的信息呢?对于老电影来说,可能就是无数划划痕、噪点等等这些东西stable diffusion是没有见过的,你要让他把它们都识别出来去掉,再补上这些东西,所以让他先能识别这些玩意儿吧。所以我们需要自己生成出一些污渍、划痕、噪点的数据,然后把这些数据和原来完好无损的影片一起扔给a i,让a i好好学习学习。当然直接扔到它是不行的,因为stable diffusion拥有很多鲜艳的信息。如果我们直接用一些小数据集训练原来的模型,呃,它可能记住了新的就把原来学到的搞混了。所以我们直接把原原来的模型。

不动,在它的基础上增加一层小模型,然后针对污渍、划痕、噪点这些情况进行训练。其次,因为ai生成的能力太强大了,优点是它会贴心的帮你补充一些细节,但缺点是它有可能也会画蛇添足。所以如果完全不加控制,你会发现影片中会出现一些并不存在的没影,或者a i自作主张搞出来的一些纹理。甚至因为不同帧之间处理的不太一样,影片连起来之后就会闪烁。这种闪烁经常看a i生成动画的小伙伴是不是表示自己很熟,怎么办呢?为了克制a i创作的随机性,我们可能就需要把模型的边界值调高,也就是说训练的概率分布收窄,这样随机性就会减少,说白了就是降低模型创作的自由度。你好好修片就行了,别有事没事自己创作,模型就会相对更稳定。当然闪烁之类的问题更多的可能是不同帧之间修复的不同造成的。

在这种情况下,我们需要把前后多帧统一考虑进来,这个时候每帧里的光流信息就很重要了。啥是光流呢?简单来说就是三维的世界中不同。物体在二维的摄像机平面上不同的运动,我们通过它们相对速度的变化,可以反推出三维世界中不同物体的远近角度等等信息,帮助建立三维世界中的模型。所以通过不同帧之间的光流信息,我们可以分辨出视频中不同的物体特征。然后通过建模尽量保持物体在不同帧之间光流信息的统一,这样就能更好的保证视频在不同帧之间平滑的过渡。好了,模型拾掇完了,你可以开心的去修复电影了。但你很快就会发现,这个修复的龟速实在是忍受不了,为啥呢?前面说了stable diffusion是从造点中反向扩散的画面来的。
也就是说对他来说生成一张画面需要进行多次反向扩散的模型也可以的。数据中生成的效果越好用过stable diffusion的小伙伴可能有体会,用stable diffusion画画你是需要等它一会儿的。这个时间对画画来说不长,因为毕竟就一张。啊,等会儿就等会儿吧。但是修复视频就不是这么回事了,最低限度一秒钟也得二十四张图片,这一张一张修下去,得修到何年何月怎么办?有一个算法可以减少迭代的次数,叫做蒸馏算法。蒸馏算法把模型分成教师和学生两个。教师模型很复杂,它负责在极大的数据量下学习特征,然后这些学习得到的特征经过蒸馏。

好吧,蒸馏是一个形象的说法,简单说就是通过设定一定的值,提取出重要特征,然后对学生模型进行训练,这样学生模型的复杂程度就大大降低了,具体到扩散模型,就是在迭代过程中隔几次迭代提取特征用来训练学生,这样学生迭代次数就大大减少了,经过四次蒸馏,迭代次数就可以减少为之前的十分之一,是不是效率就大大提高了?看到这里,你是不是脑子已经很痒了?本来是想了解怎么用stable division做电影修复,现在你跟我说这。就我家里这机器怎么把模型手搓出来?好吧,对于咱们人来说,要搞定这些的确太难了。但是好消息是有不少大厂在做这个呀,何必自己手搓呢?比如你喜欢港片吗?如果喜欢的话,火山引擎和抖音中国电影资料馆就一起搞了一个经典影像修复计划,要在一年之内将一百部港片修复到四k版本。八月十六日他们刚刚在中国电影导演中心发布了这个活动,其中十部使用a i加人工精修,可以说是经典中的经典,剩下的九十部以a i算法修复为主。所有这些影片都会放在抖音和西瓜视频上供大家免费观看。所以如果你是一个老港片爱好者,就不用费劲劲了,直接去看就行了。好了不装了,我摊牌了。

前面说的那些针对基于stable diffusion的老电影修复优化方案,都是火山引擎的技术人员自己研发出来的。除了这些,他们还针对清晰度、流畅度、色彩和瑕疵的做了很多优化。比如清晰。度这块a i超分和去模糊这类基本功咱就不说了。单就人像而言,他们就针对人像单独建模,对不同大小的人脸,不同姿态角度的人脸,不同遮挡程度的的脸脸都有较好的修复增强效果。但是效果你对比一下,而流畅度方面则需要补正,但是这种不能补。我们可以通通过修复的针针这个在在前后两帧之间创造出一个中间,但但搞不好就会有拖影像这样而这种运动复杂的就更麻烦了,像这种空中那些闪光的q q q q跑的太快,ai按照自己的理解,中间你差差的就就变成这样了。

呃,这是啥?为了搞定这个,他们只好训练了一个置信度模型,所有置信度不高的就别别下步了。这样就避免了ai在补帧中的错误。除此之外还有色彩,为了让电影看起来颜色比较正常,他们把影片按照场景进行了分割,然后针对不同场景训练不同的色彩纠正矩阵针对场景进行色彩纠正。效果就正常多了。总之吧,为了让大家能够看到高清晰度的老港片,火山引擎还是花了不少功夫的。毕竟老电影和录像厅是很多人难以磨灭的记忆。虽然在回忆中他们都已经褪色了,但无疑他们代表着一代人的色彩,鲜亮的青春。

说到这里,我想起那个喜欢在镜子里给自己磕头的硬核男人最近做过的一期视频。为什么我们喜欢玩老游戏,刷老电影?因为新世界没有能够承载我们的船。毕竟不是每个人都有勇气用自己一条胳膊去赌一个新时代,大家都是普通人,差不多就行了。当你已经失去挑战未知的勇气,只有老游戏和老电影能给你那份确定的踏实与感动。从这种意义上来说,这些高清还原的电影不仅仅是为了延续那个特定年代的电影的生命力,更是一个复原了的时间胶囊,一座青春纪念馆。它通过a i告诉我们,青春可以不褪色。这里是新石器公园,我们关注一切可能影响人类未来的科学和技术,并试图带大家一窥底层的原理。

如果你喜欢本期视频,欢迎点赞、投币加收藏。如果你对航天、人工智能、信息数据、生命科学、人机交互以及未来感兴趣,欢迎关注我们。本期就到这里,很快回来,下次再见。




