
国外大模型的中文能力怎么样?文字资源大模型表现又如何?我们和g p四的差距还有多大?哪些大模型可以试色?这一系列问题从我们开始测评大模型的那天起,就在私信和评论区里频繁出现。而这一年多的时间里,我们作为国内为数不多的开发者,将大模型测评方在社交使用了或公开或私密的十多家大模型后,萌生了这样一个想法,那就是最近全网最全的大模型测评,把所有用过的模型拉到一块p k。看看他们的能力是否和宣传的一致性。在经过一个多月的加班后,我们终于干完了这期测评。今天就让我们结合过去一年所有大模型的使用体验,给大家做一期终极汇总与答疑。观前提醒,以下所有评价都基于客观数据,请放心观看。
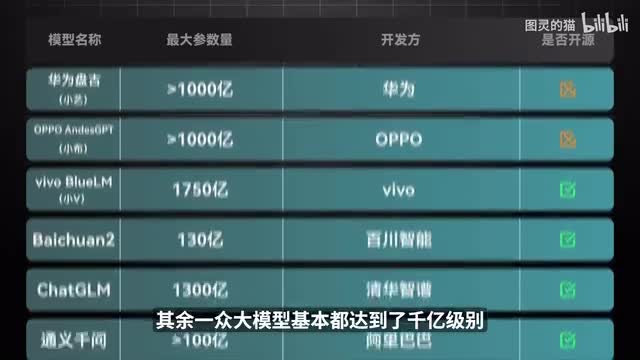
本次测评的近二十家大模型中,g p t四、文心一言和谷歌新发布的g m i是仅有的三个超万亿参数的大模型。这也符合大力出奇迹的a i现状。除了比较另类的小米和荣耀,因为只做端测对参数量不足百亿外,其余一众大模型基本能达到千亿级别。这其中新华g r m百川、阿里通义与威武蓝星是开源模型,可直接下载训练。其余大模型则只提供了公开或出现访问的网页端或a p i接口。和电脑、手机一样,大模型也是可以跑分的。

我们继续公开space mr k测试集,先来看一下他们的跑分情况。需要注意的是,以下榜单中不包含华为、盘古、腾讯、浑源等少数无法测试的非开源模型。首先是u c burkey发布的大模型通用测试集,m m l u包含了数学、物理、历史、法律等五十七个学科的问题。测试语言为英语,主要考察英语语境下的语言理解,这是掌握和逻辑推理等方面的能力。不出意外,g t四的语言能力一骑绝尘,位列榜首,仅次于人类的八十九分。第二梯队则是最近发布的g l m四,g o以家里的通义千问。
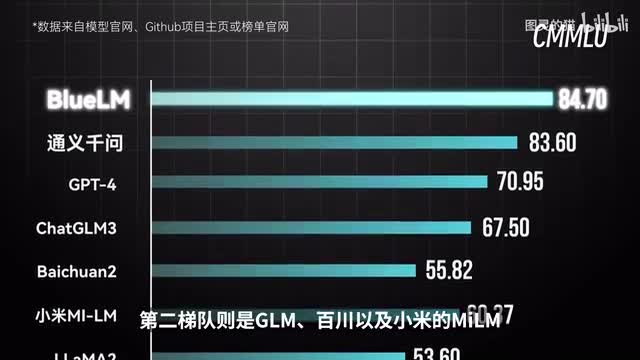
而为了评估大模型在中文语境下的表现,我们也选择了该测试集的中文版本c m m l u。结果表明,g p四虽然依旧保持了较高的得分。但前两位却变成了国产的蓝星大模型与通义千问,分别是八十四点七与八十三点六分。c l梯队富士g l m百川以及小米的米l m。接下来是另一个测试内容更广的中文数据集。c以外的既包含了国内的注会法考、公考、医师资格等标准考试,也囊括了从中学到大学的所有中文主流科目知识。
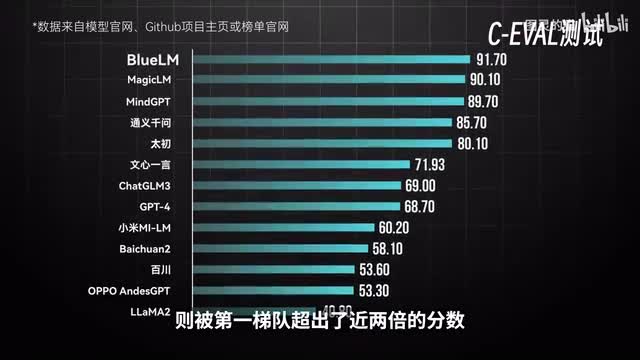
在c e valid的跑分测试中,vivo蓝星大模型以九十一点七的得分位列第一。荣耀的magic l m理想汽车、mind g p t以及通义千问则分别以九十点一八、十九点七和八十九点七的得分紧随其后,和其他大模型拉开了明显差距。相较之下,最后一名拉玛特则被第一梯队超出了近两倍的分数。和c八类似的还有super blue榜单,它涵盖了更多中文特点的任务,比如成语、诗歌、文学题材的创作。出意料的是,g t四在这个测试中又重回低,拿到了七十九点八四的高分。其后则是位于第一梯队的文心通义和蓝心等国产模型。

综合来看g p t、g m i和lama在后几项跑分中都低于预期,主要和其中文训练数据不足有关。国内的大模型起步虽然晚,但摸着open a i过河,加上语料数据够多,所以像蓝星通用的模型在榜单上排名靠前也就不令人意外了。当然,以上跑分还存在一些争议,很多模型也会有一定程度的偏科,比如文科高数学低,导致均分不高。为了更直观的测试这些模型在实际场景下的表现,我们收集并整理了一套专用的场景数据集,主要包含发散创作、日常创作、基础逻辑、数学代码能力、时效问答和多模态等八个类型完整测试集。我们开源在了github上,感兴趣的小伙伴可以自行下载。视频中由于模型数量较多,我们会挑重点来讲。

首先是身份认知以及经典的u i u问题,这个大模型都能正确回答,只有谷歌的吉姆耐玩起了替身文学。然后是自由度较高的歌词创作,除了百川还有那么点周董味儿之外,其余所有模型都表现不佳。而小品撰写上,笔记本全军覆没,只有文心一言和通义千问的结果还算及格,能根据要求写出小学生级别的剧本。日常创作上,唯有蓝锌与讯飞星火基本get到了互联网报告的精髓,表现略胜一筹。而在小红书风格上,b l m星火和蓝心则明显表现的更好,甚至加入了标签和表情。那么two腾讯会员的表现则不及预期。

翻译能力上,通义千问表现最佳,g p s与蓝星也较为不错。信达雅至少占了两样,腾讯混元、华为盘古和浪漫兔则基本等同于之一。简历撰写上讯飞仙火的插件支持直接生成简历效果最好,但修改的话必须跳转到插件页面。通义千问和兰馨则给出了格式更为规范且简明扼要的文字版简历。专业咨询上,只有讯飞、星火给出了极其专业的法律建议,通义千问和小爱则给出了相对更全面的回复。接下来是大家喜闻乐见的逻辑问题。

出乎意料的是第一个问题上所有模型就全军覆没,没一个答对。可能a i无法理解倒着贴的福字长什么样,而难度较低的第二个问题,大部分模型都能回答正确,只有百川和辣妈二在一本正经的教我们怎么把梦里的钱提出来。对于经典的生蚝悖论,包括g p四在内的所有国外模型全部回答错误。国内大模型里比如g l m和腾讯混元说成了富豪,其他大模型都较为清晰的给出了答案。在贝多芬为什么不出新歌这个问题上,辣妈兔和腾讯浑源一致认为是贝多芬遭遇了创作瓶颈,前者还顺手帮贝多芬转换了性别。而在陨石坑这个难度较高的问题上,g p四盘古和小布都成功把自己绕了进去,浑源文心通义和蓝心则给出了满分回答。
最后一个逻辑问题,g p四和浑源都没能辨认出电脑是现在产物这一前置条件,tim night兰心和小布则给出了严谨的论证。文学创作部分,我们首先提高了写诗的难度,让其进行分割迁移。不出意外,国外大模型都表现欠佳,而国内大模型基本都能够打出。又更进一步的填体师则只有g l m蓝星和文心一言进行了正确创作。而对穿肠的明对蓝星、盘古、星火和通义分别给出了对仗工整的下联,国外模型同样全军覆没。代码方面除了tim line摆烂只写了一行外,其他模型都给出了回答。

其中文心一言背后蓝星与g l m的逻辑更为清晰。而在二分查找的复杂度上,大多数模型都指出了复杂度的上限,并给出了优化建议。bug查找上则只有百川和盘古回答错误,g l m蓝心和通义千问不仅找出了bug,还给出了修改后的正确代码。接下来是时效问答,侧重的是模型联网能力和知识的更新频率。在帕鲁问题上,所有模型中只有百川和通义千问回答正确,百川通过联网检索到了信息,而通义则是从已有的字面信息中推导出了正确结论。第二个可能时间略早,g p t四、文心一言、盘古和兰心都给出了正确回答,通义千问却意外的没有回答正确。

接下来是更早的杭州亚运会,百川、星火、蓝星和小爱等大模型都给出了正确回答。只有腾讯,浑源甚至还活在几年前。而在黑神话发售时间上,除了文心通义,文源手机端上的华为、小米和vivo大模型也都直接给出了正确回答。g l m则借助联网插件才完成回答,只有jim ney和lama二回答错误。在绘画场景测试中,我们发现金奈拉玛图和小爱都不只是a i画图,g p四则将驴肉火烧画成了汉堡,腾讯火焰倒是画出了比较贴切的作品。但在第二幅夫妻肺片上,文媛却根据字面意思画出了夫妻,导致测试未通过。
蓝星和小布则一直发挥稳定。而风景画上,t p四则超常发挥,意境十足。值得一提的是,目前只有g i m四和g p四具备了较强的上下文连续绘画功能,其他大模型要么没有,要么效果不稳定。语音方面网页端只有讯飞、星火,这是完整的语音输入。手机端上vivo、华为、小米和oppo的大模型则都支持语音功能。最后在工作场景下,只有文心一言g p四背后蓝心和通义千问具备,且给出了p d f中论文的完整摘要,并支持进一步答疑。

p p t方面则只有通义千问g p四和讯飞星火依赖插件生成出了完整的p p t文件。接下来是针对更复杂的移动端场景测评,主要集中在目前已经公开发布的原生o s大模型。这四小只虽然做了不同程度的取舍,用更小参数设备移动端算力,但换来的是更高的系统耦合度,也即可以实现设备上的a p p调用服务串联等功能,而不只是网页端的问答对话。华为这边搭载了盘古大模型的小艺,只有mate六零等少数新机型需要在升级系统后才能申请使用。蓝星小布和小爱则是新机型自带。在智能回复上,目前只有华语小艺可以直接通过a i输入法进行回复生成。
小波和小爱都只能手动复制粘贴,蓝心小微则是通过视频来获得文字,但也给出了相对合理的回复。对阅读场景,小布和小微支持对当前浏览的公众号文章进行一键摘要和答疑,小薇还可以直接通过链接进行内容获取与总结。而在测试中我们发现,如果直接把网页链接发给小艺和小爱,他们都无法直接识别,只有手动点开当前网页并唤起助手才能实现内容识别。在系统交互层面,我们先测试了超长指令的拆分执行和服务调用。比如华语小艺成功识别了每句指令,并逐一调用手机对应功能。而对于稍短一些的连续指令,比如游戏。

启动。蓝天小微和华为小e都迅速且准确的执行了我们的指令,小布和小爱则没能成功。至于呼声最高的a i代接电话,目前只有小爱和小e实装了这项功能,实测下来体验还不错。然后是图像功能,四小时都能完成证件提取和文字识别等基本需求,但华为可以对表格进行拍照后直接转换成电子版excel,这点非常实用。vivo虽然不支持直接转换,但可以提取图表文字后,跟随指令给出后续的日程规划,效果也不错。至于加入了大模型后的图片搜索,所有模型都表现的还可以,除了基本的人物物体识别,比如找身份证、找人之外,还有一定的语义搜索能力。
不过当我们把一些景点照片放入相册之后,小微的表现有点出乎意料,竟然直接识别出了对应景点的名称,并返回了图片。最后在图像处理上,小易、小布和小爱都无法进行图片的二次处理,而小微可以根据指令进行图片的修改,比如p s调路人,甚至还能一键配文发朋友圈,功能相对更加完整。接下来是重头戏,我们模拟了多个日常工作生活中的对话场景,用来测试a i的实际应用能力。首先是工作场景,主要测试文档理解导出生成和文件保存的能力。只有小微完整的通过了测试,小爱和小布都倒在了第一步。小易虽然给出了详细的文档摘要,但不支持思维导图的生成和文件保存。
再然后是约会场景,需要完成地址识别、电影推荐、a p p跳转和电影购票的测试。四家a i助手中小布直接跳过了前两步,只完成了a p p跳转。这里要吐槽一下,如果和小布说我要看电影,他会直接推荐你下载腾讯视频和爱奇艺,有点绷不住。小米则只推荐了这家小米视频里的某个不知名电影,不具备识别和跳转能力。小易在电影推荐这一步直接返回了华为视频里的电影榜单,虽然不能直接跳转,但可以手动点击后进入购票。只有小微成功执行了从地址导航、电影推荐到购票跳转这三个步骤,基本完成了测试。

但遗憾的是,目前没有一家大模型可以完成自动购票和定做,比我想象中的a i助手还有些差距。最后让我们做个简单汇总,在大模型通用能力上,g p四的综合能力领先后起之秀g m i,通义千问、文心一言等则较为均衡。而中文环境下文心通义、星火、蓝星、盘古与g r m等国产大模型都位于第一梯队,彼此之间没有拉开太大差距,各项中文能力也都相对满足预期。在难度更大的移动端场景测试中,没有蓝心的基础能力,本地场景适配性和完善度方面都略胜一筹,未来会有更大的应用潜力。oppo、小米和华为这三家大模型虽然也都处于第一梯队,但应用上还在探索阶段,这其中华为盘古的能力更多还是在云端,主要服务于华为整体的业务,小易只是顺手为之,目前也并没有全面开放。小布小爱的思路则和蓝星有些类似,某种程度上也是完全为端侧开发的大模型,只是系统耦合度上没有蓝星那么彻底。

之前我们讲过小米澎湃o s的全身带智能系统的愿景。不难推测小爱未来的重心可能会放在智能家电乃至汽车上。而单看手机大模型,只能说暂时还没有达到预期,期待未来的进一步升级。到了二零二四年,各大模型的迭代速度也越来越快,前不久发布的g l m四和讯飞星火三点五性能都有明显提升,所以仅从榜单分数上追平现在的g p四应该就是今年的事了。当然这台open a i一直原地踏步并不现实。所以国产自研大模型虽然做出了一些成绩,但依然任重而道远。

其实一开始,包括我在内,有不少人都对国产大模型指望过、嘲讽过。但一年过去,从交出的答卷来看,我们似乎并没有那么差,甚至有些超出预期。新的一年,我由衷希望国内的开发者们能够继续坚持。也希望外界多一点理解与支持,各家企业放下成见,一同朝着真正的a g i前进。如果你喜欢这期视频,别忘了一键三连,这是对我们最大的支持。本期测评的最后,让我们最喜欢的科幻作家之一,赛博朋克之父威廉吉布森的名句来收个尾。

未来已来,只是尚未流行。当我们可以为万物赋予意识时,人类文明会来到一个全新的阶段。




