
继ai绘画之后,最近ai动画一次又一次的闯进我们的视野,你是否也经常看到各式各样的ai动画不断刷屏,五花八门的ai工具层出不穷,如果有的话,也在弹幕上扣个一,甚至很多已经被应用到了商业动画宣传片中,到底这种不同的a i动画是如何制作出来的?各类a i动画之间的原理又有何区别?我翻遍了内网和外网,都没有找到一个系统的教程。于是我自己花费了很多心血,抽丝剥茧,为你们制作了这个a i动画系统教程,从零开始的a i动画之旅工具案例与灵感。hello, 大家好,我是micco。今天这节课我们就来讲讲a i动画的原理和分类。其实我们知道我们平常看到的动态的影像,其实是由一帧帧的图像连贯而成的当播放速度足够快的时候,就会形成动态的画面。所以要讲a i动画,我们还是得从ai绘画开始讲起。

大家知道ai绘画是怎么生成的吗?嗯,其实啊大多数市面上的ai绘画工具。都是基于扩散模型d fusion model。去生成的。什么是扩散模型呢?它是一种深度学习的模型啊,它可以让你输入一段文字,然后通过扩散模型的扩散扩散扩散,它就可以给你呃生成对应的图像。嗯,我举个例子吧,大家现在跟着我一起把眼睛慢慢的眯成一条线,是不是看到世界变得模糊了呢?这个从清晰一点点加噪变得模糊的过程就是正向扩散。那么,什么是反向扩散呢?就是从模糊慢慢慢慢变得清晰的过程。

这个过程我们要一点一点减去一个预期噪声,最终模糊的图像慢慢变得清晰的这个过程,也就是我们眯着的眼睛慢慢睁开的这个过程,我们称它为反向扩散。如果听得懂的同学在弹幕上扣个一。那么问题来了,你肯定会问这个减去的预测噪声为什么会知道我们输入的文字的信息呢?首先要讲到训练集,大模型的训练啊需要成千上百万张的训练集,也就是我们说的照片。我们如果要让他想理解一只猫是什么样的,我们就需要给他喂很多很多张猫的照片,并且给每张图片上都打上标记,告诉电脑说这只是白猫,那只是黑猫,这只是胖猫,那只是瘦猫。所以当训练集足够多了,电脑就会记住这个猫的特征。接着我们就要讲到文字是如何转变为预期噪声的。

我们输入的每一个单词都会被分词器处理成一个一个计算机能够理解的数字,我们称之为token,也就是标记。然后这个标记会被处理成一个embedding,也也就是一个七六八指的空间向量。如果经常训练模型的同学会知道啊,这个也是训练模型的类型的一种。再通过这个文字转换器这个七六八值空间向量就会转换成一个预期的噪声图像来。那么问题又来了,如果处理一张一零二四乘一零二四的图,每一次降噪的过程中我们都要减去一次又一次的一零二四乘一零二四的预期噪声图像的话,那么整个生成环节就会变得特别特别的漫长。于是stable division就发明了一种方法,叫做later division前空间扩散。
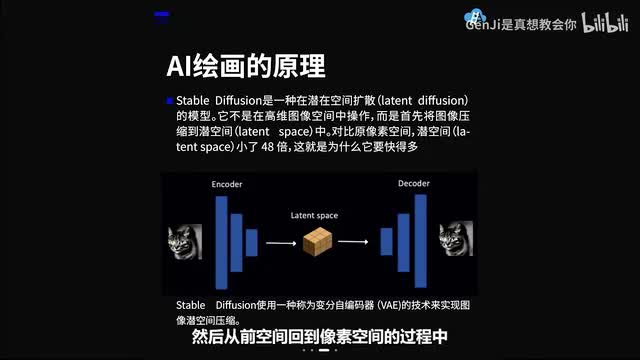
什么是前空间扩散呢?它不是在高维,我们理解的这个图像像素空间中去操作。而是首先将图像压缩到了前空间latent space中。所以对比原像素空间,前空间小了四十八倍,这就是为什么它要快得多。所以这个压缩的过程啊,我们就叫它叫做编码。然后从前空间回到像素空间的过程中,我们叫它叫做解码。大家这个时候肯定会好奇,为什么图像压缩到前空间以后不会丢失信息呢?原因是自然图像不是随机的,它们具有很高的规律性,面部遵循眼睛、鼻子、脸颊和嘴巴之间的特定空间关系。

换句话说,图像的高维性是伪影自然图像可以很容易的压缩到更小的潜在空间中,而不会丢失任何信息。我们举个简单的例子。人看人的脸,看到的是鼻子眼睛嘴巴。但是机器看到你的脸。压缩到前空间中是一个更加抽象的概念,他看到的是你。眼睛、嘴巴之间构成的黄金比例。

所以嗯这个就是呃前空间中呃信息储存的方式和我们像素空间中信息储存的方式的不同。但是它都蕴含了关键信息的特征。那么讲完了ai绘画的原理啊,讲回到a i动画。由于人类眼睛的特殊生理结构啊,如果看到的画面的帧率高于每秒约十到十二张的时候,那么人眼就会认为它是一个连贯的图像,所以这个现象被称之为视觉暂留。这也是为什么当初的电影胶片是一格一格拍出来的,然后借由其快速播放,让画面看起来是连续的。所以讲到a i动画呢,我们首先来讲一下它的原理和分类。

嗯,这个整理是在国内和国外都没有的。为了便于大家的理解。老师啊这里特别把a i视频嗯常见的工具和原理分为了三大类,分别是纹身视频、图片视频和视频生视频。纹身视频下面又可以分为两类,a i生长类视频和a i动态短视频。而图片视频下面也可以在图片引导的情况下去做a i生长类视频。也可以输入一张图片,让你的图片动起来,去做a i动态短视频。

也可以让你的人物图片开口说话,去做a i口播类的视频。而视频生视频下面的分类呢主要分为a i风格迁移视频和c j角色替换视频,动漫动画生成类视频。这个ai风格迁移是什么意思呢?我们之后会慢慢说。但是他旗下我又把它分为了三类,分别是传统的逐帧绘制,还有啊现在更加进一步的关键帧重绘,在用a i的方式去补间,最后就是一键风格迁移,这是一种特别快速的风格迁移的嗯工具。我们从纹身视频开始讲起,首先要讲一下这种最常见的生长类视频,它通常是用the forum工具做出来的。它的原理还是类似于纹身图,属于一类扩散模型。

它是用文字控制指定帧的画面,再用参数控制前一帧和后一帧之间的连贯度、相似度等等,以及控制镜头的移动参数,制作出一种三d的效果。但是呢这个这类视频的缺点是它会有抖动。和意识流的一个特点。接下来我们来讲纹身视频的第二类a i动态类短视频。这类视频通常是由呃pick lives啊或者runway的粘土等工具去生成的。它生成的视频通常比较稳定,和上一类视频里那种抖动比较强烈的特征来比较的话,这一类视频明显抖动会少很多,更加的稳定。

但是缺点呢是生成的时长通常都比较短,通常只能生成二到四秒。然后最近这两类工具啊都开始不停的放大招。这类工具最近加入了motion强度的变量,可以控制画面运动的强度。他们最近更是都加入了camera movement的功能啊,就是可以控制摄像头的移动。这个类型的视频生成的原理,其实和刚刚说到的the forum用到的纹身图的这个原理是一样的。只不过因为它加入了运动模块,嗯,他给你喂了大量的训练集,告诉你呃女孩的一个头发的飘动是什么样的,大海的波涛汹涌是什么样的,啊,小狗它跑起来是什么样的。

由于它被训练了大量的动态的信息,所以一旦加入了这个运动模块,我们就可以通过一些关键词的控制,使它从文本生成了一个动态的,更加稳定连贯的一个动态的视频。讲完纹身视频,我们现在继续讲图燊视频图片视频类似嗯,刚才的纹身视频其实方法都是类似的,只不过是加入了图片的指引。然后它的原理追根溯源就是图生图嘛,嗯可以在开头的第一帧添加图像指引。然后现在the forum现在加入了guided image这个功能。我们可以控制。在视频的不同帧数,指定用不同的图像结合着文本。

共同去控制。然后这个功能呢,我们到时候在讲这一章的时候也会具体讲到。然后第二类图形视频,也就是我们刚刚说的a i动态短视频。这一类也是可以通过指定的一个图片的指引,然后生成一些简单的动效。比如让你的头发飘动,让雪落下来,让大海波涛汹涌等等等等。还有一类就是我们说的a i口播类短视频。

你只需要输入呃一张图片,不管是人的动物的都可以。然后它就可以嗯控制你的嘴型动起来,嗯,通过你输入一段旁白文字,呃,让它实现唇音同步。这个技术的核心其实是用到了大量的人脸数据训练。神经网络模型时期能够生成或修改人脸的图像。通过这种技术呢可以使静态的人脸照片动起来,或者修改视频中的人脸表情和动作。所以现在很多嗯主播带货呀,数字人啊等等等等,就是用这个方法去实现的。
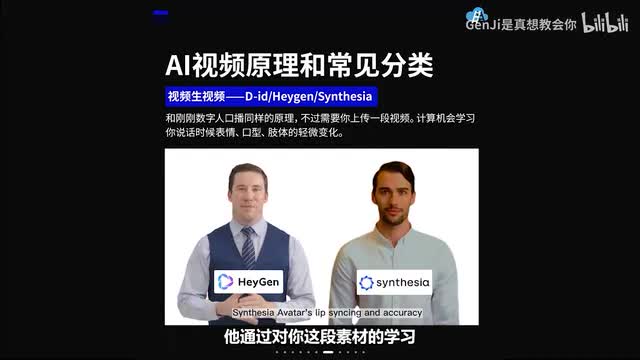
接下来我们来讲视频生视频和刚刚不同的是,刚刚是用一张图像驱动的嗯口播类视频,所以它的那个呃唇部的运动还是会比较假。但是这一类视频的话,你需要上传一段两分钟的你的个人素材,大概需要半身的视频,然后手部自然的运动,它通过对你这段素材的学习,会给你生成你的数字人形象。然后他会拥有你的表情、口型、肢体的。有类似的变化。这一类视频会比刚刚图片跟视频的口播类视频自然很多。接下来我们讲到的这类视频嗯,它都属于风格迁移类视频。

什么叫风格迁移类视频?顾名思义就是把一个原视频的风格迁移成另外一种风格。嗯,接下来我们来看一下这一段跳舞的ai动画视频。这一类视频是不是在b站上你们经常也会刷到?嗯,这一类视频到底是怎么样实现的呢?它其实原理是类似图生图,嗯,也就是一帧一帧的去嗯通过图生图实现重绘。嗯,它是一种比较传统的方式,也比较耗时。啊,通常的情况下,你可以直接在stable defusing这个开源工具里用图生图的方式,或者利用这个move to move的插件。去嗯实现。

但是它有一个问题就是耗时比较长,一分钟的视频通常需要至少一小时的生存时间,而且它的抖动会比较强烈。如果你想要实现抖动小的效果的话,嗯,也有一些小技巧。这个时候我们会在具体的章节里面去讲,但是呢嗯这个就需要你和原视频高度的相似,就失去了重绘的意义。就像我们刚刚看到的那个a i动画舞蹈类的视频,它其实和和原视频是非常非常相似的对所以如果想和原视频差异比较大,风格迁移的效果比较显著的话,那有什么别的方法呢?那我们来介绍第二类视频生视频的方法。他是用到了e b c s这个老牌的工具。其实这个工具并不是一个新工具,很早之前前几年就出了。

嗯,但是我们现在把它和a i动画相结合起来,它会有一个意想不到的效果。我们先用a i动画先行对他们的关键帧进行一个重绘。然后呢这个e b c s会嗯根据这个关键帧和视频嗯是。生成中间的过渡针。所以这样的方法它大大节约了时间,而且可以实现比较显著的风格。视频大家可以看一下视频里的效果。

可以看到视频里嗯嗯左下角是输入的一张关键帧,左下角的上方是输入的是原视频。然后这个放大的视频就是我们最终生成的这个风格迁移以后的视频。还有一些可以让你实现很简易的风格迁移的方法。如果你不想要尝试前面两种比较耗时耗力的制作方法的话,你们可以去尝试一下runway的谵妄或者是凯博,它能实现一个更加显著的风格迁移。你可以选择嗯官方的模板,或者是文字描述,或者是上传参考图片三种方式去指定你风格迁移的方向。你到底想要将这个视频转变为一个什么样的风格?但是呢嗯这这一类型一件工具的嗯缺点就是它不能很准确的控制风格迁移的方向,所以只能适合做一些实验性的影片。

讲完了风格迁移类的视频是视频,最后还有一类我也想要给你们介绍一下。嗯,他要求你上传一段视频,然后他可以一键将你的里面的角色替换成另外一个角色。他用到了呃视频动态捕捉等等等等的a i最新的a i技术。然后甚至你可以上传一个自定义的绑好骨骼的模型。然后去替换你视频中的人物。最终它导出来的是一个blender的场景,你甚至可以导出这个人物的f b x,甚至是含有动画的f b x。
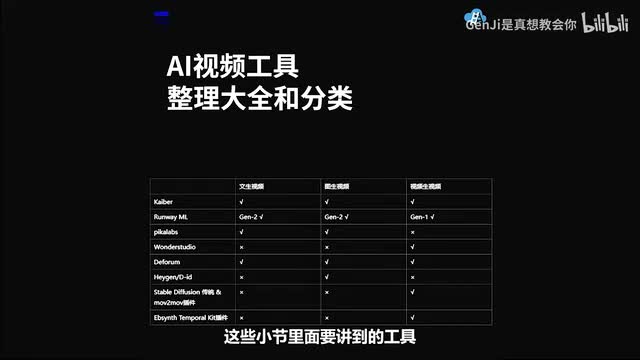
所以这个工具现在在影视界的冲击也是非常非常非常大的。那到现在为止,我们就讲完了所有的a i动画视频的一个分类和原理介绍和工具介绍了。然后我这里把所有的我刚才提到的a i视频工具和我们之后这些小节里面要讲到的工具都整理成了一个表格。大家可以参考一下。嗯,不同的工具它其实有一些功能是交叉的,所以大家可以选择自己想要的一个工具去使用。对,然后我按照它纹身视频、图片视频、视频、生视频的三大类,分别给这些工具就是标上了属性,大家可以自己去看一下。

嗯,截图保存一下。下一节课我们会讲解s d传统的视频转视频的方法和app sense结合temporal kit去生成无抖动的视频的工作流。如果你觉得这一期视频对你有用的话,别忘记一键三连哦,那么我们就下一期再见吧。




