
大家好,今天我们主要介绍九个text video文本生成视频的工具。首先是生成式a i视频初创公司runway,它在二零二三年二月推出第一代视频合成模型gen-2,能够基于已有的视频,使用文字提示或者图像生成不同风格和内容的新视频。紧接着在三月runway推出文本视频生成模型gen-2,这个多模态ai系统能够根据文本、图像和视频片段生成视频,提出只要你能描述它,你就可以看到它的宣传语,gen-2已经可以生成最长十八秒的视频。九月gen-2增加director mode系列频功能导模模式,用户可以选择和调整镜头的方向,还有移动速度,就好像真的有一个镜头和拍摄这段视频。
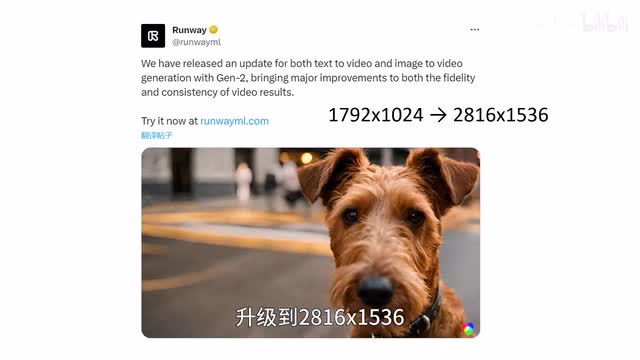
十一月gen-2在整度和一致性方面还有移动完善,让a i生成的内容更加流畅清晰和。真实基于静态图像生成的视频分辨率从一七九二乘一零二四升级到二八一六乘一五三六。至此,人们可以用mid journey这样的工具生成ai图像,再由gen-2基于这些图像生成。十八秒的短视频拼接在一起就能合成一段较长的音乐视频或者微电影。

网友纷纷表示,gen-2简直逆天。目前gen-2有八种模式,分别是文本生成视频text、video, 可以通过文本提示词合成任何风格的视频。二是文本加图像生成视频text press image to video。三是图像生成视频image to video。

四是风格效仿,将任何图像或提示词描述的风格移植给自己的视频。五是故事版,story's board可以对模型样板进行风格和动画渲染。六是面具,musk可以将视频中的某个主体分离出来,比如路边找东西的小狗,并通过文本提示词对它进行修饰或者改造,比如让它变成白皮、黑斑点的小狗。七是渲染render,可以通过图像或者提示词的输入来让没有添加纹理的渲染,也就是entex trate renders变成真实感较强的输出。

八是定制customization,基于训练图像生成高清的定制视频。二零二三年六月,runway宣布完成一点四一亿美元融资,谷歌、英伟达等领头公司估值达到十五亿美元。另外,runway在十二月上线文字生成语音的功能,text to speech, 将文本转化成栩栩如生的、富含感情的语言。请看视频。

接下来看stable video division,由stability ai在十一月推出,可以基于文本、图像或现有视频生成高质量视频,支持对动作、镜头、角度以及视频效果进行自定义。该模型可以轻松适配各种下游任务,包括通过multi view数据集微调而基于单一图像模拟多角度图像。十一月十五日的用户偏好研究显示,stable video diffusion优于主要竞争对手runway和pick labs。请看视频。

说到文本生成,视频领域的黑马,一定要说pick labs。二零二三年十一月,pick labs推出ai视频生成和编辑平台,pick一点零,输入一句话即可生成动画、卡通电影等各种风格的视频,并且可以通过后续描述调整视频的内容和风格。pick的联合创始人郭文锦和陈灵梦都是斯坦福ai实验室的前博士生,其中郭文锦在哈佛大学二年级的间隔年期间成为meta a i research的全职员工,又先后在微软、谷歌、ipad games等公司和团队的同时,灵梦则在本科期间就发表了五篇通用人工智能方向的论文,两个人都具备很强的工程科研的能力。公司已经完成五千五百万元融资,估值两亿美元到三亿美元。

在与runway stability ai等生成式ai视频工具和模型竞争的同时,pick瞄准一些区别于竞争对手的功能。例如如n e一点零,可以对现有视频素材的元素进行修改或者工作,比如修改视频的尺寸,更改视频人物的工作为视频。中的星星,戴上墨镜,转化视频的风格等等。请看视频。
we are going to take to. 我觉得。其他生成视频的模型和工具还有meta imi video。在此之前,meter曾在二零二二年九月推出文本生成视频工具make a video,基于文生图技术的进展,实现文本到视频的内容生成。该系统通过图像和图像对应的描述学习世界的样子以及如何描述世界的样子。
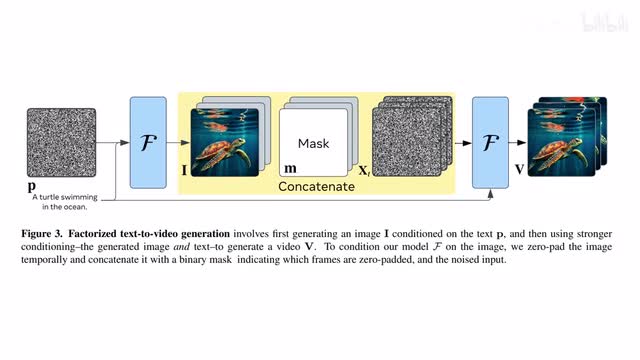
二零二三年十一月meta推出e u video,这是一个基于扩散模型的文本到视频生成模型。生成过程分为两步,首先根据文本生成一个图像,然后根据文本以及前面生成的图像生成一段视频。这样模型只需结合文本预测图像未来会如何演化就可以了。在训练数据算力和可训练参数量相似的情况下,imi video的表现要优于文本直接转视频的方法。

相较同类模型,imei video在视频质量方面的平均胜率达到百分之九十一点八,在文本忠实度、text faithfulness方面达到百分之八十六点六。谷歌的amazon video是基于一系列视频扩散模型的视频生成系统,具备很好的控制能力和世界知识,能够根据文本提示词生成多样的高清视频。amazon video支持不同的艺术风格,能够理解三弟结构。也可以渲染不同的字体。

再来看阿里巴巴dream moving,我们在周报中有介绍过这个可控视频生成框架和dream moving针对以人类为中心的内容生成,根据人物的身份和动作序列来生成高质量定制化的人类跳舞的视频。dream moving基于stable diffusion模型打造,团队从互联网收集了一千段高质量人类舞蹈视频,并分割成大约六千段时长在八到十秒钟的不包含转场和特效的短视频来进行训练。模型使用video control net来控制动作,使用cotta guider来保持人物身份,也就是人脸和衣着的一致。当输入是文本提示词的时候,dream moving可以按照要求生成动态的人物和背景。

比如一位穿着白色西装和短裤的长发女性走在街上。对于生成人物,可以指定五官面容,将头像的图片以及文字提示词作为输入,就可以生成这个人的动态视频。比如一位身着西装,佩戴蓝色领带的男士在埃及金字塔前跳舞。不只是五官,还可以指定服饰,比如同一个人穿着不同的衣服,在不同的场景中跳舞。
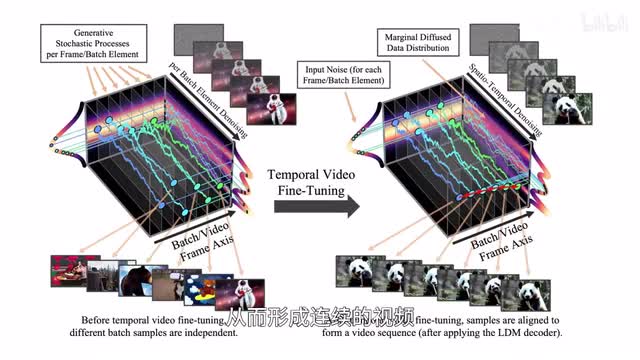
dream moving还可以按照动作序列,也就是前面说的post sequence,基于风格化的图像生成一段视频。现在看英伟达,二零二三年四月,英伟达以及慕尼黑大学等的研究者推出online your late ends,利用潜在扩散模型低能耗生成高清视频,团队将预训练的图像扩散模型转化成视频生成器,经过微调从而形成连续的视频。二零二三年八月,英伟达又和马里兰大学等研究者推出视频生成模型puco,全称是preserve your own correlation,其架构由四个网络组成,包括一个基础模型和三个上采样模型,也就是sampling,能够以极低的算力需求生成高清连贯的视频。与make a video和imaging video的比较显示,pilot生成的视频更具真实感。

比如算术课上一只困惑的棕熊,a confused crazy bear. in calculus class, 相比较make a video生成的内容,pko的这只棕熊看起来才更加困惑。再比如一只羊和一个酒杯的右边,a sheep to the right of a wine glass. 相较imaging video生成的内容,pilot更没有违和感。字节跳动也在五月推出高效能文本视频生成框架magic video。基于前面说的l d m,也就是呃潜在扩散模型来打造能够用一张g p u合成空间分辨率为二五六乘二五六的视频片段,以flops也就是每秒浮点运算计算,那v d m视频扩散模型它的算力消耗是字节跳动这个magic video的六十五倍。

在生成质量方面,呃,magic video相较make a video也毫不逊色。比如夜晚川流不息的高速公路,busy freeway at night啊,仔细看magic video生成的内容更加真实且细节更加丰富。when i spent a least来看moon valley,它也是一个文本生成视频的生成式ai模型。呃,用户加入discord服务器即可免费使用并获得实时支持。

目前可以选择的视频风格包括连环画、范特西啊、动漫、写实还有暗黑等等啊,能够生成三秒到五秒时长的视频片段。ai视频生成领域的其他选手还包括右脑科技red brain a i专注a i图像和视频生成的初创公司。今年六月完成千万元天使轮融资,八月宣布video studio a i视频创作功能开启内测,支持定制视频模型,一键切换风格、生成特效等等。还有ai视频生成创业公司refresh start a i他在十一月被adobe收购。

最终该团队在生成式ai音视频技术,还有文本到视频生成工具方面的专业知识,将扩展adobe的生成式视频功能。啊,说到这里,记得之前第一次看adobe firefly,呃,他的介绍视频就被惊艳到了,一起来看。when i get to the crag i'm putting on my shoes. 但是。这期节目就到这里,以上提到的论文和平台链接请参考视频下方的简介部分。





