
大家好,今天我们来介绍meta i近日推出的seamless communication系列模型。这些a i翻译模型旨在弥合和语言之间的鸿沟,实现更加自然的交流,包括similar expressive无缝表达模型,能够在翻译中保留语言的风格、语气、语速、韵律等差异。

比如轻声低语或者使用悲伤的语气等等。也就是之前是怎样的语气,翻译过来还是怎样的语气。

它不只是翻译啊这句话的意思,还会保留之前那句话它所有的风格、语速、语气、韵律。而此前迈特曾推出a幺幺b项目,全称是。
no language left behind旨在通过开源模型提供两种语言的高质量互译,也就是相互翻译,包括使用人数较少的艾斯图图利亚斯语、strayin, 还有沃尔都语等等,帮助人们跨越语言的屏障分享。交流,还有相互学习。

matt还基于wikipedia a的文章创建了多语言翻译语料库wiki matrix,用于训练翻译模型的并行语料数据集c c matrix。参与创建了大规模多语种语言翻译语料库speech matrix,并且在今年就是二零二三年八月推出面向语音。
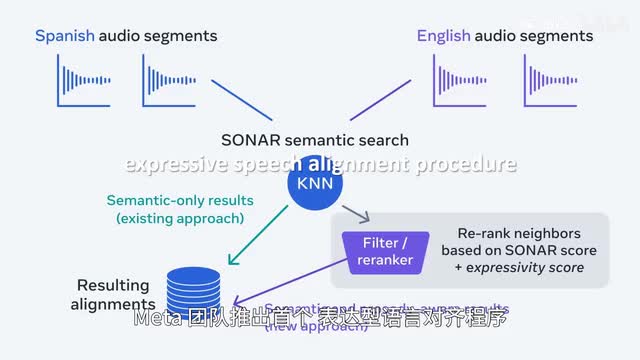
翻译的多模态基础模型similar m f t m m t t t代表massively mulligan and motto del machine translation,大规模多语种、多模态机器翻译,支持近一百种语言的自动语音识别。基于以上成果,mac团队推出首个表达型语言对齐程序,从原始音频数据中自动发掘语言含义、meaning和整体表达overall expressive vey相一致的匹配对,并为此创建基准数据集seen with a line expressive来验证对齐质量。

呃,系列模型还包括similar streaming无缝传输模型,能够以大约两秒钟的时间提供近一百种语言的语音文本翻译。它可以智能地决定什么时候有了足够的输入,形成了语言背景,进而可以输出目标语言的文本或者语音。
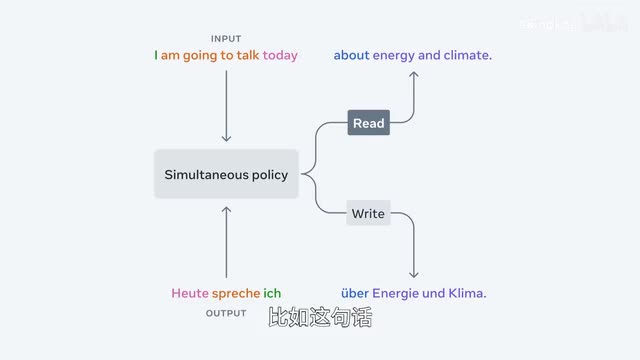
呃,换言之,他可以决定根据不同语言的特有结构来恰到好处的分割语义进行断句。比如这句话,我今天要谈一谈能源与气候,啊,它的英语是i am going to talk today about energy and climate。

我要说今天关于能源和气候,而德语的顺序是今天说我关于能源和气候,那他们的资格顺序不同,就需要把握断句的时机。另外还有基础模型,seamless emptor version二第二版的seamless empty tee,就是前面说的那个seamless and fort的升级版,也是seamless expressive和seamless streaming模型的基础。

它不仅增加了支持的原语和。目标语言而且对小众语言更加友好啊,它的非自回归文本到单元解码器能够提供更加流畅和一致的文本语音输出。

相较此前一些行业领先的模型,让single s and四version tu它的表现明显更优。而seamless就是融合以上模型能力,将similar effort to visit ee的多语种高质量翻译能力,还有similar streaming的低延迟能力,以及similar expressive复刻表达方式的能力,融合到一个统一的系统之中。
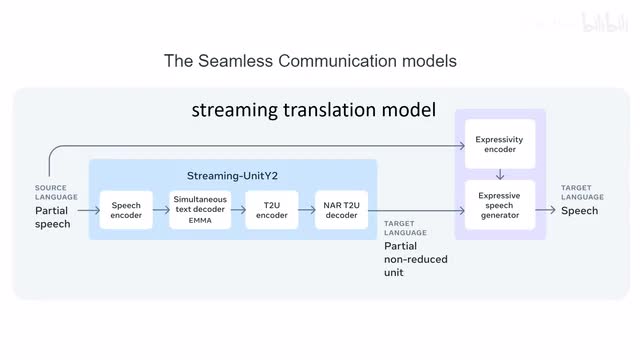
称是第一个能够保留语言风格和韵律的镠翻译模型。streaming translation model. 另外,为了能够验证翻译内容的真实可靠性,模型生成的所有音频输出都会加上水印。
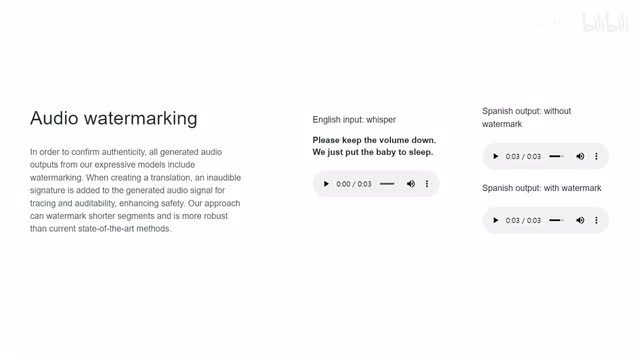
当用户创建翻译的时候,生成的音频信号上会附加一个人耳听不到的签名,保证音频内容可追踪、可审核,进而提升安全性。比如这边这个spanish alpha西班牙语的输出,一个是呃不带水印的,一个是带水印的,两个听起来真的是呃一样的ok呃。
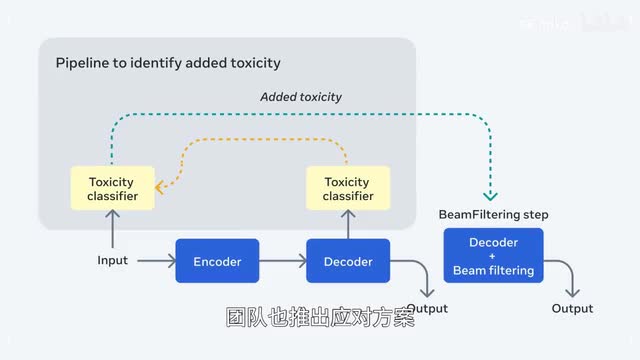
此外,为了降低凭空生成有害内容的风险to reduce pollution,and a taxi si团队也推出应对方案。适用于任何翻译模型,无需重新训练,也不会有损模型的性能。





