
这是一段两分钟的海绵宝宝音频,现在把它放到这个神奇的软件里,经过简单的处理和训练,就能得到现在这样的效果。没错,只需要几分钟你就拥有了海绵宝宝的声音。以此类推,其他任何人的声音,只要你有两分钟甚至一分钟的素材,都可以轻松的把它克隆下来。当然我这个视频是真人配音的,各位一定要信我啊。能如此简单快速的克隆一个声音,都得感谢g p t service这个项目。
它是由花儿不哭和r sel这两位大佬共同开发的。本期视频就仔细讲讲该怎么用。如果你遇到了什么问题,都可以向花儿不哭大佬请教。因为你问我的话呃,我大概也是不懂的啊。首先g p t service有官方的整合包,大家可以去关注花儿不哭大佬,然后私信回复这其中任意一个关键词,就能获得下载链接。
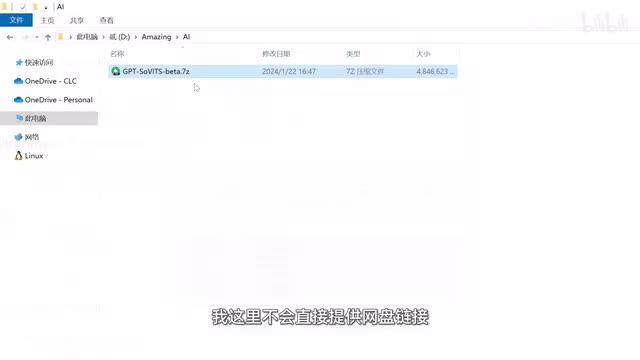
再或者你也可以打开g p t service的github页面,从这里直接下载整合包。只不过githa对网络有一定要求,这个就得大家自己解决了。出于对原作者的尊重,我这里不会直接提供网盘链接。那下载整合包之后解压一下,然后打开g p t service的文件夹,双击运行go web u i d b a t就能成功启动了。然后我们来准备一下克隆所需的音频数据。

g p t service最大的优点就是少量音频也可以获得不错的效果。所以如果你懒得弄,那一分钟两分钟都可以长一点当然会更好。那么目前仅支持中文音频用于训练,未来会支持其他语言。对于训练素材来说,质量比数量更重要,因此千万不要滥竽充数。如果你准备克隆自己的声音,那么直接录制就可以了。
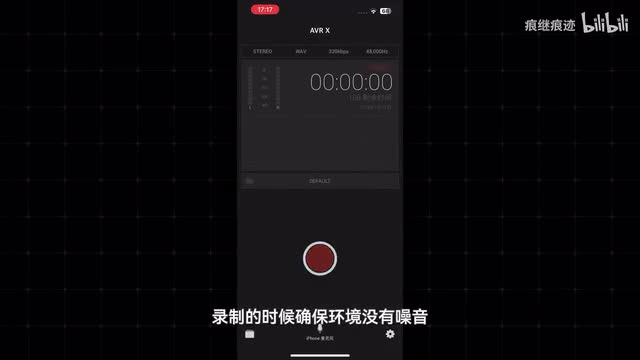
没有专业麦克风就用手机,安卓可以用自带的录音机app记得把格式设置为w a v,以获得更好的效果。iphone可以用a v r x这样的软件,在设置里同样选择w a v格式进行录制。录制的时候确保环境没有噪音,并且嘴巴和手机底部保持一个适当的距离。录完之后直接用分享功能把它发到电脑上,就可以直接用于训练了。如果你准备克隆别人的声音,那么大概率是从网上下载的素材。
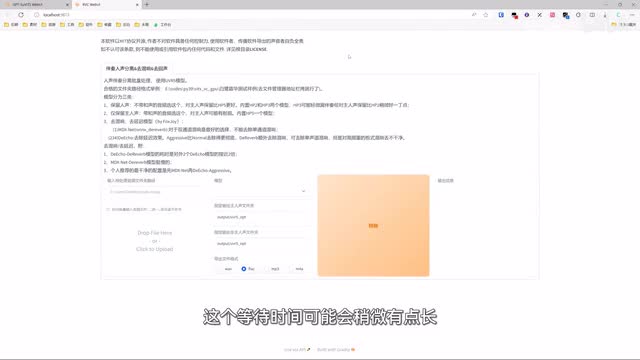
所以如果有背景音乐之类的噪音,可以用这里的u v r五处理一下。勾选这个u v r五杠五b u i之后,耐心等待。一会儿它会自动打开一个新的页面啊,这个等待时间可能会稍微有点长。把需要处理的音频素材拖进来,然后按照文字提示在这里选择对应的模型,再转换处理一下就好了。转换后的文件默认会保存在output u v r五杠o p t目录下。
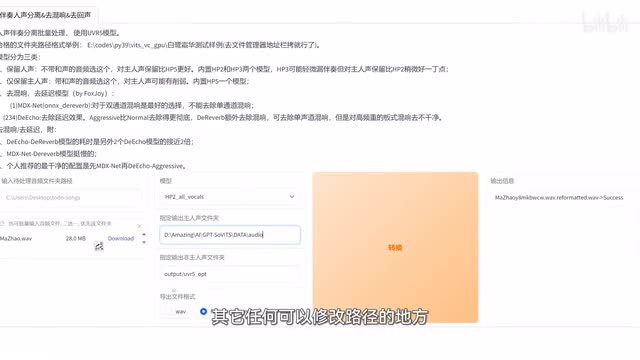
这里可能会存在一些非人声音频,所以建议把每一条都听一遍,然后把不需要的删除。当然你也可以手动修改保存路径,像这样复制粘贴一下路径就可以了。这个操作同样适用于其他任何可以修改路径的地方。所以为了能够使文件井井有条,你可以像这样创建一个专用文件夹,然后按照角色名称来整理。同时在每个角色文件夹下创建不同的子文件夹,用于存放不同的数据。

就像视频里的这样,你还可以整一个文件夹模板,以后只要复制再改个名称就可以直接用了。音频处理完成后,关闭当前标签页,回到g p t services页面,取消勾选u v r五杠web u i,然后我们来切割文件,所以在这里输。音频所在文件夹直接点这里复制一下路径地址,然后在这里粘贴就可以了。其余参数保持不变。如果需要调整,一定要先看一下这里的说明,然后直接开始切割。
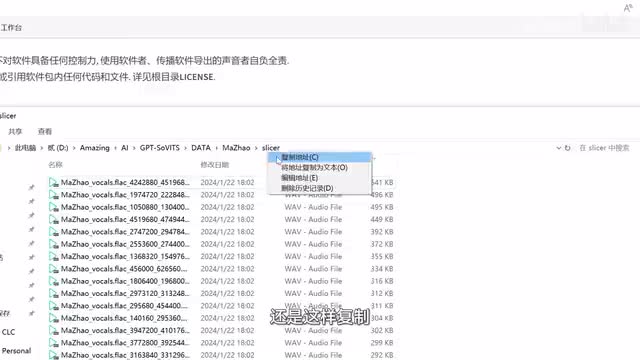
这个应该很快就能完成了,默认会输出在output slice o p t文件夹里,你可以简单听一下。如果发现有很长很长的片段,比如超过二十秒的,那么可能就需要先清空这里的文件,然后调整一下前面的参数,重新切割一下。切割完成后我们来打标,就是把音频对应的文本内容整出来,还是这样复制,然后粘贴一下,填写切割后的音频路径,接着点开始并耐心等待,直到看见这个提示打标的结果在output a s r o p t文件夹里。这个路径目前还不能直接改,你可以用文本编辑器打开这个list文件查看结果。当然为了获得更好的效果,我们需要对打标结果进行校正。
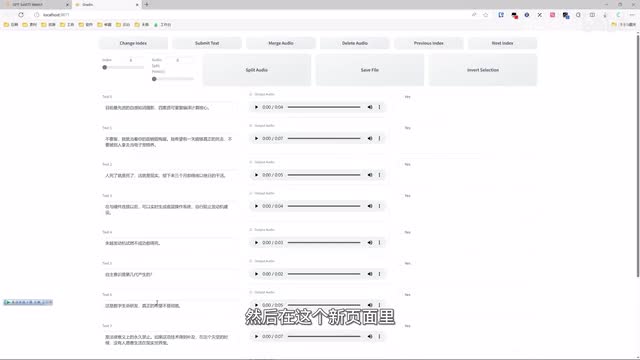
首先选中这个list文件,然后点击主页这里的复制路径,接着在g p t service这里粘贴刚才的路径。你勾选打标web u i,耐心等待它自动打开。然后在这个新页面里点这里可以播放音频。你对照着看左边的文本有没有差错,有的话就修改一下。另外也要看语气停顿和标点有没有对上。
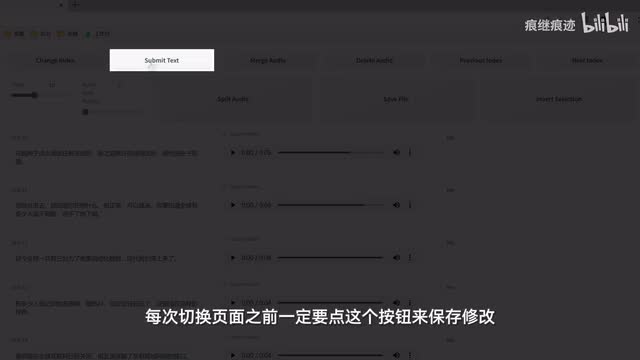
比如说这样一句话,卓越发动机是人不成功。都得死,它在这个地方应该是有个停顿的,所以我们手动插入一个逗号,以此类推,咱们就一个个听过去。改完这一页之后,点一下submit text的保存结果,然后点net index切换到下一页,然后点击页面之前一定要点这个按钮来保存修改,然后点点点点点。然后特特别好或者不好的音频呢,可以先勾选音频旁边的yes,然后点击delete audio来删除,然后再点live audio保存文件。如果你需要合并音频,也是先勾选,然后点merge audio就行。
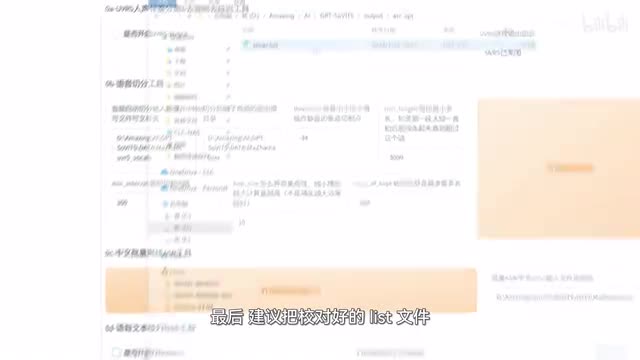
特别注意啊,在删除或者合并音频之前,都应该先点一下submit text来保存结果,这一点很重要很重要。等全部校准完毕就关闭这个页面,然后取消勾选打标web u i。最后建议把校对好的list文件复制一份到自己创建的专属文件夹里,然后可以选择文件来就行。然后我们切换到一个g t t x x t t s文件准备开。训练了。
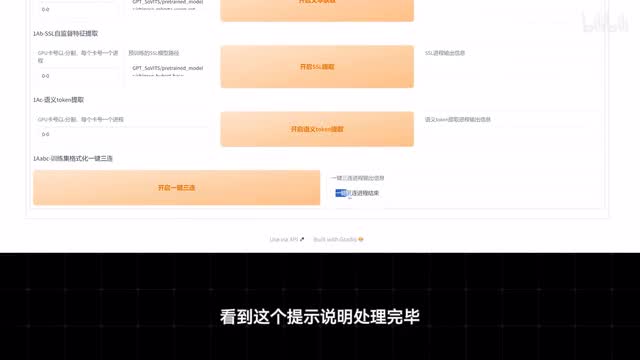
首先用英文或者数字填写一下名称,这个随意。然后在下面这里呢分别填入标注文件的路径以及切割好的音频文件路径。这一步我想大家都会了,对吧?前面都讲过的其余选项都不要动,直接点下面这个一键三连就可以了,耐心等待。看到这个提示说明处理完毕,然后我们切换到e b杠微调训练页面,参数先全部保持默认,我们只需要依次进行这两个模型的训练就行。如果你在命令行窗口中看到了类似这样的报错,那么就说明报显存了,此时需要降低batch sizes,然后再一次尝试。
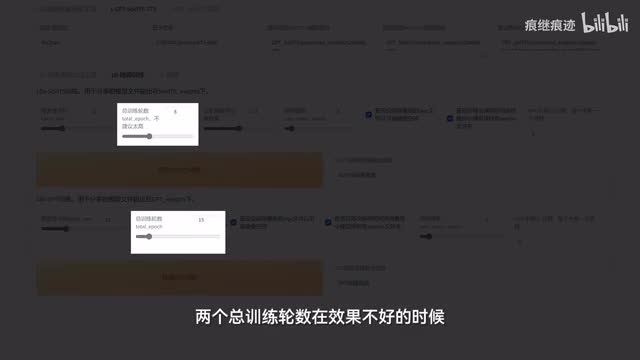
你可以每次减少四来看看能不能正常跑跑完之后你应该能在sweet weight和g p t wait目录下看到保存的模型文件,如果没看到就说明没成功啊,此时就需要看看命令行窗口这里是不是出什么错误了。另外g p t训练的batch ze似乎不能设置的太高,太高了好像没法保存模型文件,这应该是个bug,需要注意一下两个总训练轮数在效果不好的时候可以适当拉高一点,但不用太高,因为太高的话对效果的提升似乎并不明显。最后需要注意一下保存频率,你用总训练轮数除以保存频率,得到的就是最终保存的模型数量,这个数值也不用太。高保存过多的模型没有什么意义,只会占用硬盘空间。两个模型微调训练之后,就可以切换到e c杠推理页面来使用了。
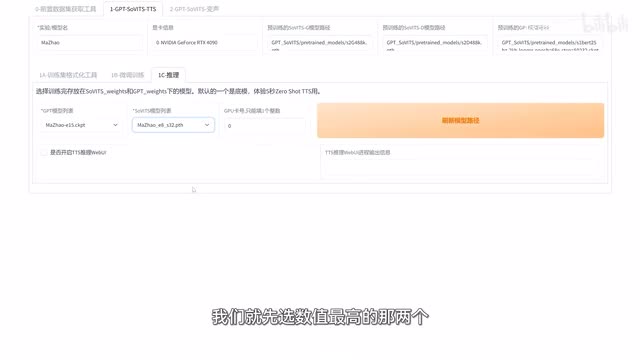
先点这里刷新一下模型列表,然后依次选择自己训练的两个模型。模型后面的e多少多少就表示练了多少轮,而s多少多少就表示训练的步数。并不是数值越高就一定越好,但一般来说我们就先选数值最高的那两个来看一下效果,效果不好再看看其他的。选完之后勾选t t s推理web u i,然后耐心等待推理页面的开启。在这里我们要先上传一段参考音频,你训练用的是哪个人的声音,那么参考音频也得用那个人的,并且参考音频也不用太长。

个人觉得五秒左右比较好,太长可能会导致生成结果抽风。你可以直接从切割好的音频里选一个,然后在右边这里输入音频对应的文本内容,再选择对应的语种。注意这个参考音频对最终合成的效果影响还是很大的。如果你想获得一个平静一点的效果,那么上传的音频也得是平静一点的。如果你想激动一点,那么上传的音频也得是激动一点的啊。

接着在这里输入想要的文本,然后点击。合成语音就能听到效果了,是不是非常简单呢?给我五十,我请你吃蟹黄堡。另外即使是一样的参数,每次点击合成之后获得的音频都是会有一些差别的。所以你可以多点几次来抽卡,你获得最满意的结果。回我五十,我请你吃蟹黄堡。

微我五十,我请你吃蟹黄堡,给我五十,我请你吃蟹黄堡。点击这里的三个点,可以把生成的音频下载下来,或者打开这个temp文件夹,这里有之前生成的所有音频,记得定期清理。还有一点就是即便你训练用上来结果。那另外如果你想一次性合成很长的文本,就需要先切分一下,这样效果会比较好。从左边这里输入长文本,然后选择切分方式,最后把右边的切分结果复制粘贴到上面这里再合成就好了。
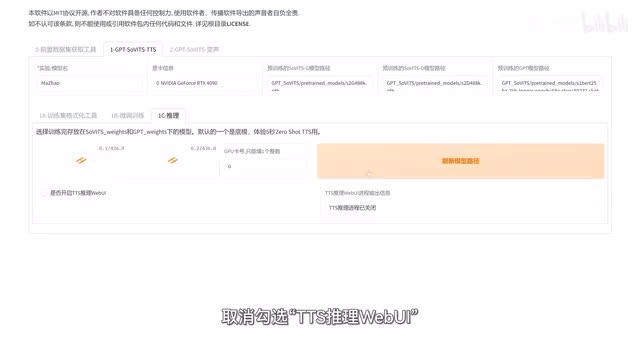
实际上它就是帮你自动分享了,所以你也可以。在文本编辑器里手动分行,然后粘贴到这里来合成也是同样的效果。如果你想切换到别的模型,就先关闭当前页面,然后回到g p t service页面,取消勾选g t s推理web u i,接着重新选模型,再重新勾选一下web u i就可以了。实际上g p t service也可以不做任何训练,就直接克隆声音。只需要在选择模型的时候选这两个默认的,然后参考音频选择你想要克隆的声音,再直接合成就好了。

只不过这样的效果肯定是不如训练之后来的好的,无奈既没有时间,还要冒着被打上不务正业的标签的风险了。如果喜欢本期视频的话,不要忘了一键三连哦。如果喜欢本期视频的话,不要忘了一键三连哦。怎么样?这个g p t service的操作还是很简单的吧,只要你熟悉一遍,后面的操作只会越来越快。各位如果喜欢这个项目的话,可以去github上给他点个star,或者给花儿不哭大佬一个三连。
毕竟这种开源分享的精神是永远值得赞扬的。好了,以上就是本期视频的全部内容了。如果。喜欢的话不要忘了点关注,你可以长按点赞一键三连,我们下期再见,拜拜。




