
google research和m i t的研究者针对大模型训练数据的成本问题,推出sync r不用真实数据,而只用合成图像合成描述来学习视觉表示from synthetic tic images and synthetic c captions,并且其表现与使用真实数据的club相当。

climb就是contractile language of the training对比语言图像预训练。加州大学和snap的研究者推出定制化影像修复方案,towel paper tuning双支点调整。
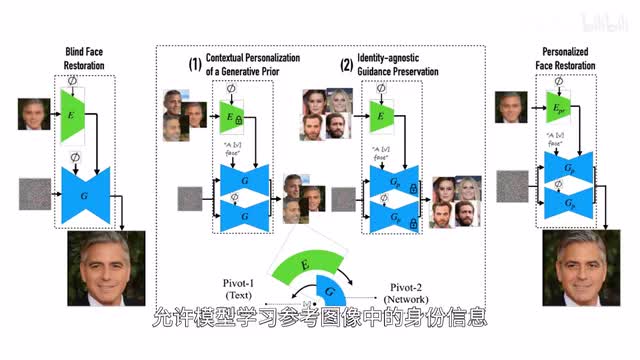
相较单纯基于扩散模型的盲目重建,java paper tuning主要采取两个步骤,首先以文本为支点对扩散模型进行微调,允许模型学习参考图像中的身份信息。然后对指导网络进行微调,让编码器专注于提取图像的细节信息而非人物身份信息,从而在保持人物身份的同时让模糊的图像清晰化。

meta i的研究者推出hyper bowl train,能够基于单张图像快速生成三d结构。首先生成多角度的图像作为输入,然后根据输入图像调整s d f network,也就是符号距离函数网络的这个权重,让模型通过hyper network前馈适应新的场景。

相较同类方案,bolt rain生成结果与输入更加一致,质量更高。香港中文大学等研究者推出rich dreamer,可以根据文本生成细节丰富多样的三d内容,比如呃敲鼓的鳄鱼或者骑摩托车的爱因斯坦等等。
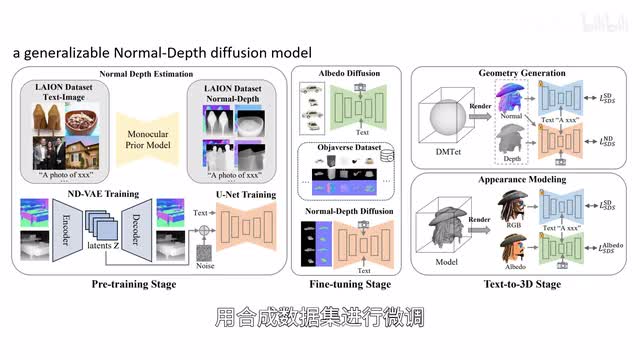
团队首先基于一个通用的法线深度扩散模型生成物体的几何结构,用合成数据集进行微调,然后对基于物理的渲染材料进行建模。相较同类方法,rich dreamer的表现更好。
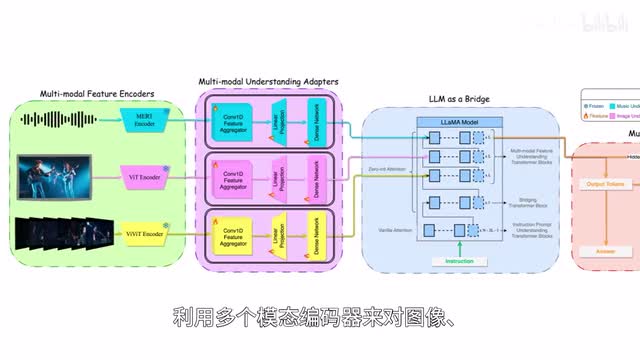
新加坡国立大学和腾讯a r c love的研究者推出m skirt you jane多模态音乐理解和生成框架,赋能音乐相关的艺术创作模型。利用多个模态编码器来对图像、视频和音乐进行编码,由lama two模型进行理解并执行下游任务,擅长音乐理解、编辑和生成任务。
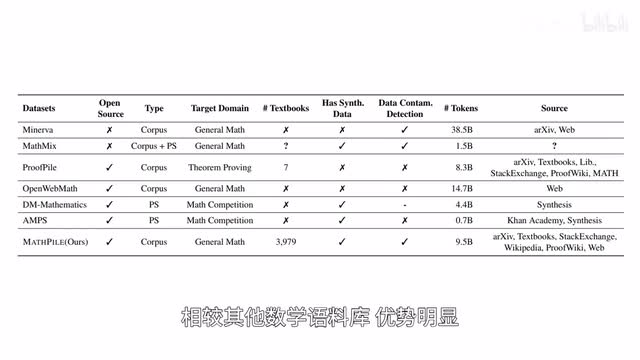
上海交通大学等的研究者面向数学领域推出预训练数据库mass pile tokens达到九十五亿,相较其他数学语料库优势明显。mass pile遵循lessons more的原则,进行细致的数据收集与处理,保证数据的质量,帮助增强语言模型的数学推理能力。

团队计划开源不同版本的mass pile。中国农业大学科研团队对外发布应用于农业领域的行业大模型神农大模型一点零,具备农业知识问答、文本语义理解、文本摘要生成、农业生产决策推理等功能。

模型有海量高质量农业知识数据训练,包含一千多万条农业知识图谱数据,五千多万条现代农业生产数据,两万本农业类图书。中国科学技术大学和real infancy的研究者推出c d n web,可以对网页端的大规模场景进行实时渲染。
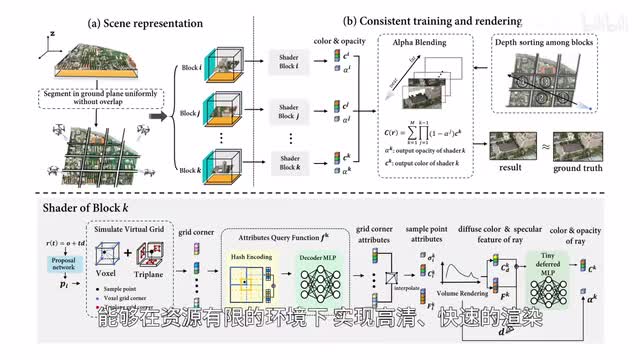
通过将全程场景分成较小的数据包,包含资源有限的环境下实现高清快速的渲染。通过同类方案,c c一一web在恢复细节、达成高质量重建方面表现更优。
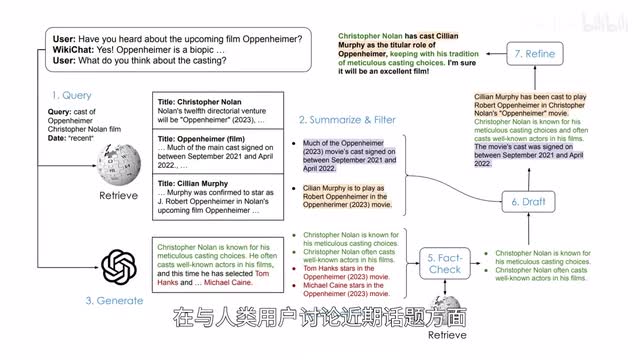
斯坦福大学的研究者利用wikipedia维基百科英文版的数据训练vicky chat成功克服了大模型的幻觉问题,并且具备较高的对话能力和较低的延迟。在与人类用户讨论禁忌话题方面,w i k i h h a t的事实准确度达到百分之九十七点九相,较g p t四要高出百分之五十五,同时获得明显更高的用户评分。

此外,w i k i h h a t在相关度、自然程度、非重复性以及时间准确度方面表现良好。快手和哈尔滨工业大学的研究者推出基于大模型的信息检索代理系统,twy agents能够理解用户的问询、引用外部文件、检索和升级内置信息,并通过时间感知的搜索浏览工具包计划和执行任务,从而提供全面的回复。

复旦大学和海康威视的研究者推出laura m o e低质自适应混合专家模型,可以看作插件版的m o e mixtures of experts,能够根据数据类型合理的协调专家即使引入大量的指令数据来微调模型以适应特定的任务,也不会影响大模型此前积累的世界知识verra knowledge。m i t等的研究者推出laser全球layer selected rank reduction,曾选择降至只需在模型训练完成之后,对transformer的特定层进行修剪,即可显著提高模型性能,并且不需要额外的参数或者数据。
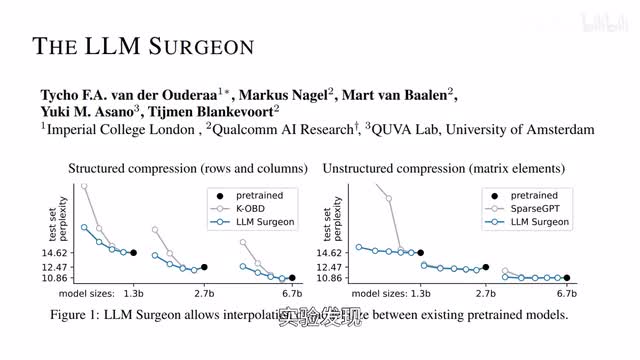
伦敦帝国学院的研究者推出通用框架aleem surgeon,能够有效的对大模型进行非结构化、半结构化以及结构化的修剪。pruning of ala m s. 呃,实验发现l l m m surgeon可以为一系列o p t模型以及七十一参数的lama二修剪百分之二十到三十的行列rose and columns,并且对性能的影响可以忽略不计。

o p g是magic a i在二零二二年推出的一系列预训练transformer的语言模型,其中一千七百五十亿参数的o p t性能与g p t三相当,而g p t三参数也是一七五零e呃,而开发消耗的碳足迹只有g p t三的七分之一。清华大学、大连理工大学和北京邮电大学的研究者面向大模型驱动的自动化代理,推出experiential code learning框架,让代理能够从历史轨迹中收集捷径导向的经验,并通过代理之间的相互协作,在执行任务时避免重复的错误和低效的尝试。
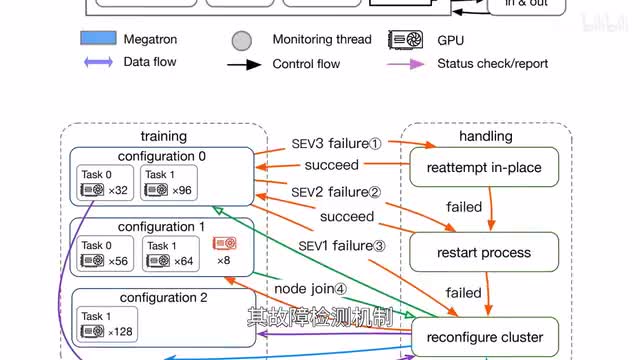
阿里巴巴和南京大学的研究者面向大模型训练故障恢复,推出uni round,融合英伟达的大模型训练库m a c a ron,提升大模型的训练恢复能力及故障检测机制,能够针对故障本身采取修正措施,并且考虑成本配置最优恢复方案。相较领先的同类方案,u n i q q o o的整体训练效率高出一点九倍。
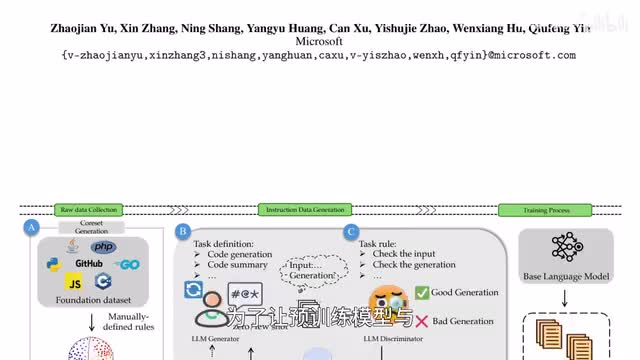
微软的研究者面向指令数据生成推出代码语言模型wave code wave代表广泛多面的指令微调增强。为了让预训练模型与指令遵循训练数据集相一致,团队使用大模型生成判别框架a generator discriminatory framework来生成指令数据,让数据生成流程更加可控、可定制。
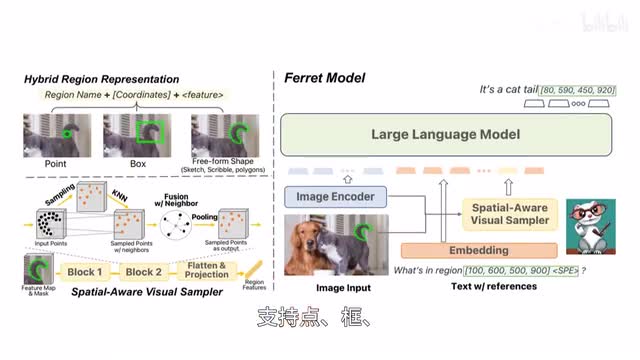
a微调程度相似的情况下,wave code处理代码相关任务的分化能力优于其他开源模型。苹果推出七十亿参数开源大模型favorite,具备良好的多模态能力,能够解读和创作图文内容,支持点框、自由形状等多样的区域输入,也是region input而实现多模态大模型的细粒度引用和定位,开放词汇描述,a favorite可以无缝融合i o s和nike u s,为用户提供流畅的体验。
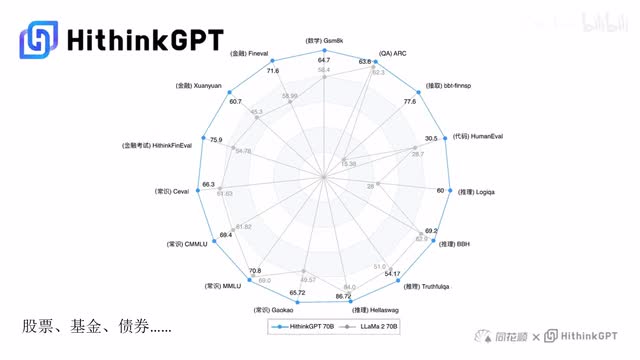
同花顺推出自研大模型high thin k g p t,可以提供股票、基金、债券等十五个金融业务领域的投资建议。投顾对话机器人问才借由hiya n k g p t进行升级,涵盖查询、分析、对比预测等五十多项功能。

印度移动出行平台ola推出a i语言模型crude trim,a crude dram在梵语中的意思是artificial人工的主打,理解印度的文化知识背景。模型型二万亿tokens训练能够理解二十二种印度语言,支持十种语言的文本生成。

钉钉联合i d c发布二零二四年a i g c应用层十大趋势白皮书,预测到二零二四年全球将涌现超过五亿款新应用,相当于过去四十年的总和。白皮书指出二零二四年a i g c应用的十大趋势关键词包括应用层创新、a i agent专属模型、超级入口、多模态ai原生应用、a i工具化、a i普惠化等等。





