
你可能听说过不少ai动画项目,例如open ai的sora、快手的可怜、腾讯的mimic motion、腾讯音乐的muse post等,这些项目之间有什么不同,我该选择哪一个呢?在我看来,除去能否本地部署以外,主要的区别在于使用方式。使用sora和可零时,只需要或者说只能提供一个想法或首尾真。大部分内容由他自由创作。我们很难插手。这样生成的视频帧连续性较好,但其表达的内容可能会有偏差,需要抽卡。而muse pose may make motion或animate diff等则通过输入完整的参考视频、逐帧的图生图或control net阶段提示词prompt travel等,能确保视频按照你的想法进行,但受制于训练数据,需要额外步骤优化视频质量。

在当前阶段。我更倾向于第二种方式。因为这样我可以完全参与整个视频的制作过程,而不是完全依赖于运气来讲故事。今天我将带领大家搭建一个我心目中目前效果最稳定的,能逐帧控制的图生视频方案。它结合使用了p i a模型和anet dif。记得在最早制作animate dif系列教程时,我以生成小姐姐眨眼的视频为例。
但那时候是纹身视频。而这次我们要挑战的是输入任意一张图片。都能让他眨眼,即使它不是ai生成的。本工作流涉及到的开源模型p i a是由open m l a b分享的文本转视频解决方案。优点是运动控制出色,非常遵从文本提示查看提供的实例效果确实不错。但今天我们不仅仅满足于简单的使用这个功能,而是将其融入到anet gf流程中,这样可以配合分阶段提示词生成一个我们全程控制的长视频。
首先。我们需要升级coffee u i enemy def evolve的插件。确保版本在六月十七日的这个commit之后。可以通过config u r manager dead pool或下载安装包等方式进行升级。接下来下载p i a模型,就是这个一点六七g的p i a c k p t文件地址我会放在简介里,下载后要放在config u i customer nodes conf u i admit d evolved models目录环境准备好了,现在我们开始搭建工作流吧。首先我们处理输入图像部分。

添加load image节点,并选择一张需要转换为视频的图片。接着添加image size by longer side节点。并将size设置为五百一十二。这个节点的目的是确保输入图片的尺寸适合s d一点五处理,然后添加getting image size和empty latent image节点,以生成对应尺寸的latent ent。我们现场是生成十六张图片,将batch size设定为十六,整理下节点加个组。现在我们开始添加animate dif和p i a相关的节点。
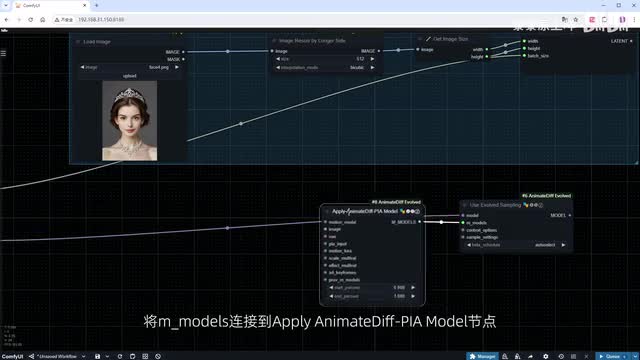
首先从use of of the sampling节点开始,将模型输入端连接到load check point节点,并选择一个与输入图像匹配的大模型。毕竟如果我们使用真人大模型来处理动漫人物,效果可能会很糟糕。然后将m models连接到apply animate diff p i model节点。选择我们刚刚下载好的p i a c k p t作为motion model。输入的图像使用经过recess处理后的输出。将v i e连接到一个load v a e节点,并选择我们熟悉的八十四万模型。
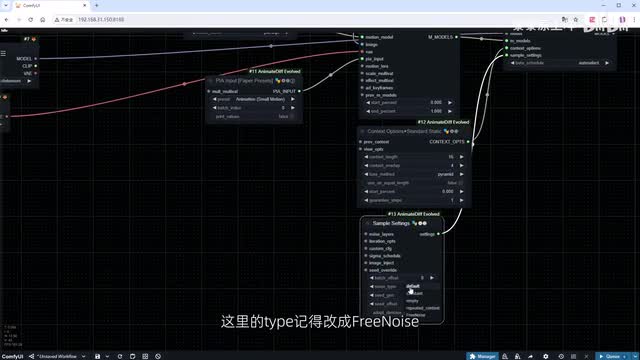
添加使用论文预设值的p i n input节点里面有很多预设好的对应不同运动幅度的值。我选择这个small motion的加上context和sample settings节点。这里的type记得改成free noise。将这些节点编个组,方便查看。因为需要为视频的不同时间段提供相应的提示词,我们加上prompt travel相关节点。在这个例子中,我设置在第八帧时闭眼。
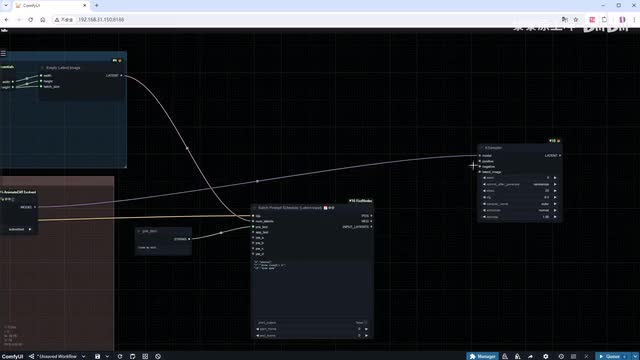
这里为什么是七?是因为插件从零开始计数,完善各个输入输出端口。protecting填写所有帧都共用的部分。添加采样器节点。调整其中的参数基本是常用的选择,选择一个喜欢的种子并将其固定。c f g调低到七,采样方法使用d p m p p二m配合cas。补上v a e decode节点,将前空间内的latent转换为图片。
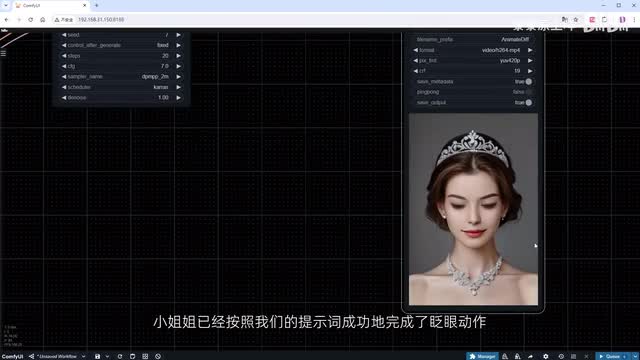
使用video combine节点生成一个m p四格式的视频。点击开始运行。稍微加快处理速度。你会发现在视频中小姐姐已经按照我们的提示词成功的完成了眨眼动作,但是画面有略微变暗,这是p i a每帧参考值不同导致的。后面我会跟大家分享怎么重新打光。现在我们尝试制作一个更长的视频,将图片帧数增加到四十八。
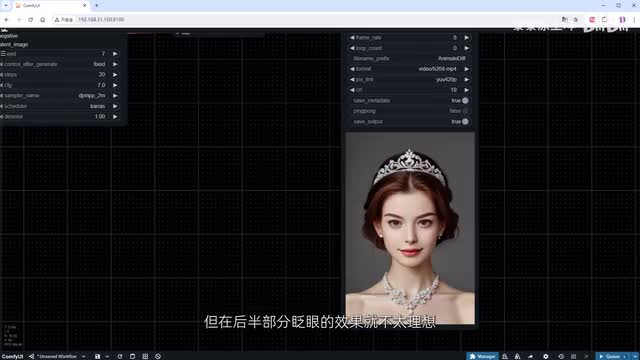
在prompt travel节点中,我们添加一些新的动作,包括让头发变红和第二次眨眼。点击运行加速,查看结果。我们可以看到人物在视频的前半部分眨眼的效果很好,但在后半部分眨眼的效果就不太理想。这是因为预设的p i a参数在长视频时可能无法完全匹配我们想要的动作。为了解决这个问题,我们可以手动设置参数。首先我们添加batch value schedule节点,为不同的帧分配不同的值。
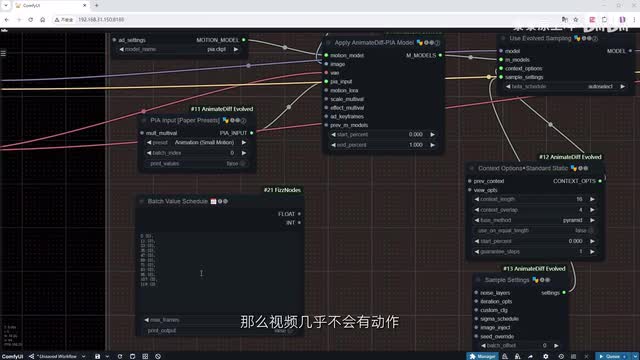
这里的值越接近一。生成的视频就越接近原图。如果前后的值保持不变。那么视频几乎不会有动作。因此我们可以按照这个思路。前十六帧每八针修改一次值。
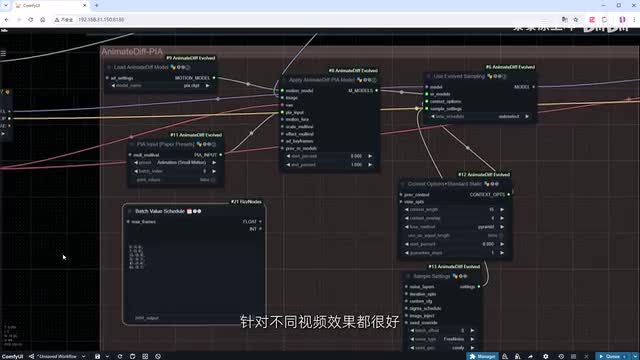
后续每十六针修改一次值。保证值在零点八和零点九之间震荡。这基本是个万能方案。针对不同视频,效果都很好。然后。我们添加mult v和p i import节点。
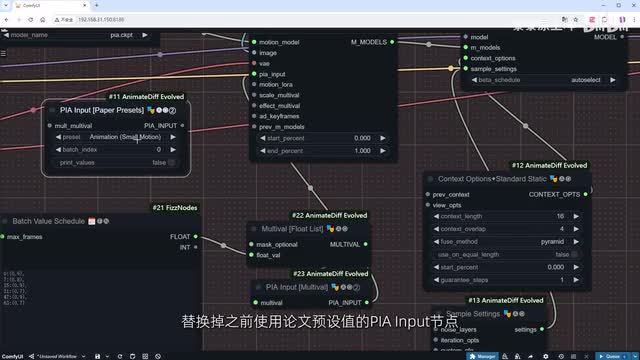
并将它们连接到n d f流程中。替换掉之前使用论文预设值的p i input节点。我们复制一个video combine节点。用于与之前的结果进行对比。点击运行并加速生成过程。对比视频可以看到。
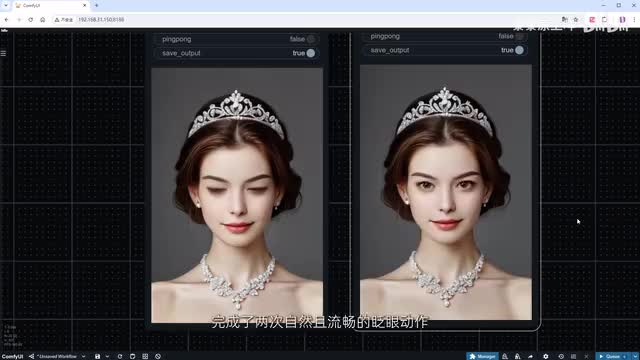
经过参数调整后的结果更为理想。人物成功的根据我们的提示词。完成了两次自然且流畅的眨眼动作。在生成视频的过程中。你可能会遇到其中一到两针完全崩坏的问题。根据我的经验。
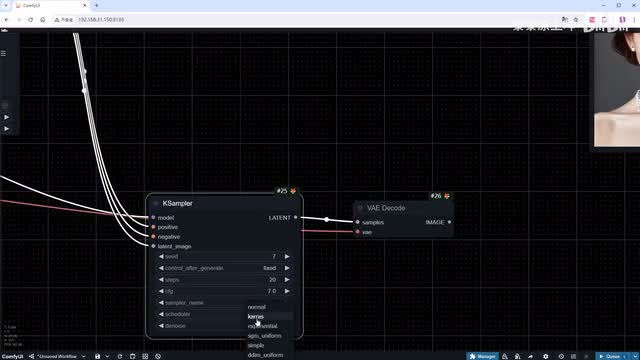
通常可以通过修改采样方法来解决。我来给大家展示不同采样方法的效果。复制采样器节点。选择oiler配合s g m uniform。使用图片合并功能,将两个采样器的结果放入同一视频中,以便于比较。点击运行跳转到结果。

这两种方法的结果都相当不错,你可以根据自己的喜好进行选择。此外oiler和normal的组合也不错。之前我们就提到了p i a的一个小缺点,就是在人物眨眼的过程中,随着震荡值的变化,画面的整体亮度也会忽明忽暗,这在代码示例中的成秃力也非常明显。不过在conf y u i中,我们有多种方法可以减轻或修复这个问题。今天我将向大家展示一种简单的方法,使用i c light重新调节视频的亮度。添加ic light conditioning节点。
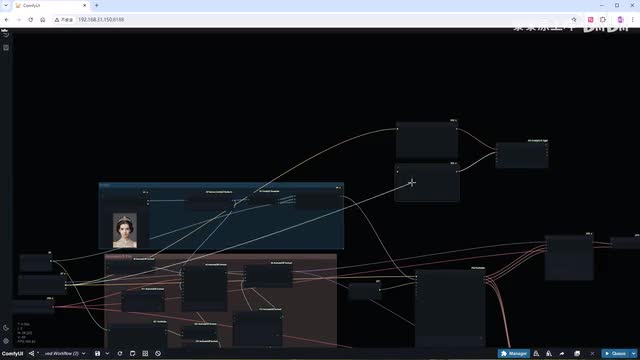
为它添加额外的正反向提示词。正向提示词是光照的类型,我简简单单写个spotlight。反向提示词是最基础的质量提示词,worst quality, bad quality. 再把clip和v i e连接好。i c light有多种工作模式,我们选择把视频作为前景。这里需要注意的是,必须先添加一个image batch to image list节点来转换下格式。再通过v a e n code获取latent list才能进入到foreground端口。
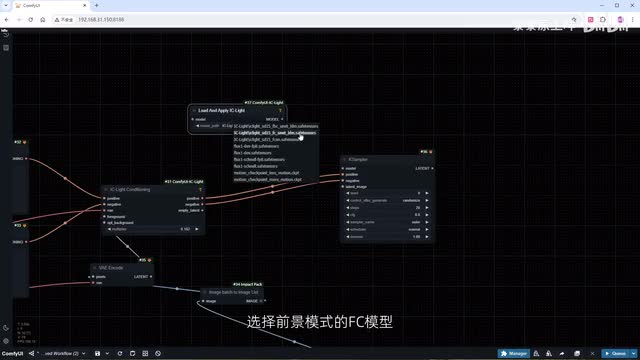
添加k a sampler。连接好输入的提示词。再加一个low and apply icy light节点。选择前景模式的f c模型,并将其左右两边的模型端口分别连接到我们正在使用的大模型和采样器。接下来,我们需要创建一张亮度图。添加一个solid mask节点。
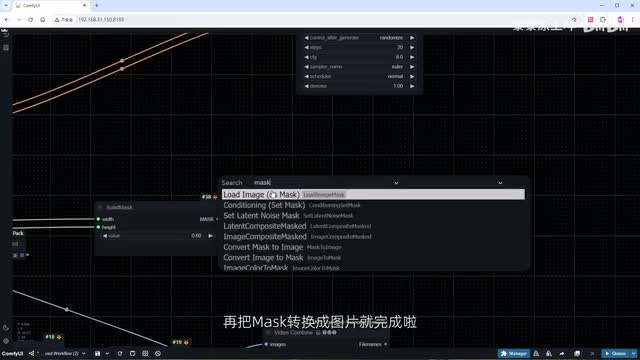
确保其宽度和高度与前景图像的尺寸相匹配。只改成零点六。这样不至于过量。再把mask转换成图片就完成了。接一个预览图片节点等哈看看效果,同时使用v a e n code作为latently传递给k sampler。修改一下k samper里的参数。
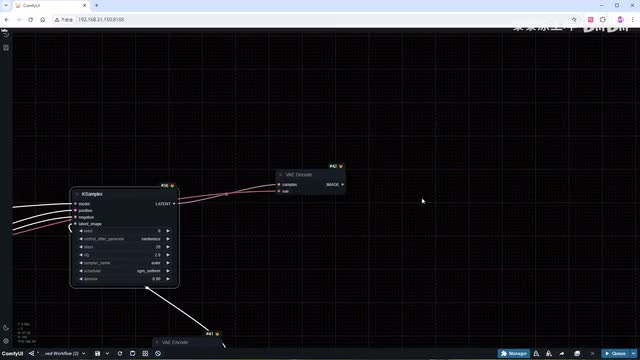
c f g改成二。采样方法选择oiler配合s g m uniform,重绘幅度改成零点九。在v a e d code之后。一定要记得使用image list to batch转换下格式。最后添加video combine来合成视频。格式依旧选择mp四。
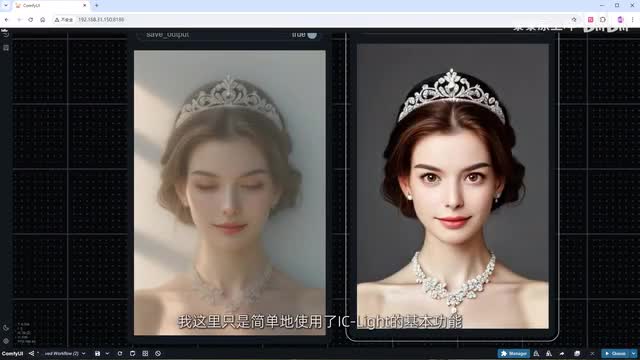
点击生成,加个速看看结果。整个视频的明暗度都被统一了,没有了之前那种明显的变暗。对比一下原视频,p i a的问题被完美解决了。当然我这里只是简单的使用了i c light的基本功能,小伙伴们可以自己选择不同的光照或参数,以达到更惊艳的效果。详细的使用说明可以参考我之前的这个视频。好了,今天的视频就到这里,我会在视频简介中提供这个工作流以及相关插件和模型的地址。
大家下次见。




