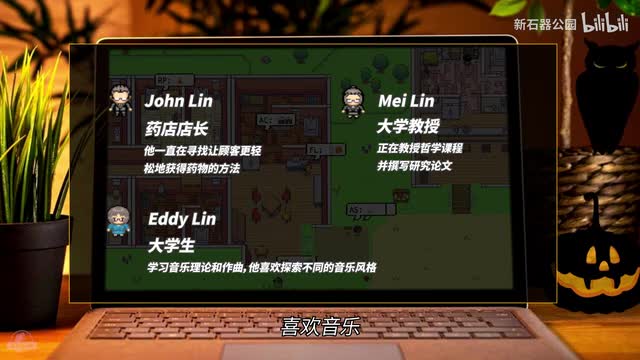
二零二三年四月,当世界上所有的人还沉浸在chat g p t带来的震惊中时,谷歌和斯坦福大学的几个研究人员做了一个很有意思的实验。他们在一个类似虚拟人生的游戏中放入了二十五个a i并为这些a i设定了相应的角色和社会关系。比如小玲是一个药店的店长,而他老婆则是一位大学教授。他们还有一个上大学的儿子,喜欢音乐,诸如此类。小镇麻雀虽小五脏俱全,有药店、有学校、有商店、有酒吧、有咖啡馆,当然还有每个人自己的家。a i小人可以吃饭、睡觉、刷牙、洗澡、买东西、去咖啡馆或者在街上散步。与我们见过的常规游戏不同的是在这个游戏中没有预先设定的剧本,a i小人每天的生活由他们自己决定。

出乎意料的是,这些a i就根据这点初始设定,在游戏中有滋有味的生活起来了。一段时间以后,他们交了新的朋友,互相交换小镇的新闻,讨论市长候选人的人选,甚至成功举办了一个情人节派对。在派对上一对互相暗恋的a i还获得了亲密接触的机会。这个实验被称为斯坦福小镇实验。在斯坦福小镇上到底发生了什么?我们之前认为没有动机、没有规划、没有行为能力的a i似乎活了。他们学会了安排自己一天的生活,维护和发展社交关系,并能够自己组织起一项活动。a i获得了心智开始觉醒了吗?要回答这个问题,我们需要先从一个概念开始说起。

a i agent中文可以叫a i代理。大家都用过chat g p t,你一定知道chat g p t拥有超越常人的知识,它通过非常巨大的预训练数据了解了非常多的东西。你可以在一问一答中和它很有效的交流,比之前的人工智障不知道强了多少倍。但也许很快你就审美疲劳了,毕竟一个只会聊天的a i实际的作用并不大。它的先验知识停留在过去的某一个时间点,它无法搜索互联网获得最新的知识。它无法买机票、订酒店、叫外卖,也无法对最新的八卦提出看法,陪你科学的吃瓜。最重要的是他没有规划能力,也缺乏长期的记忆。
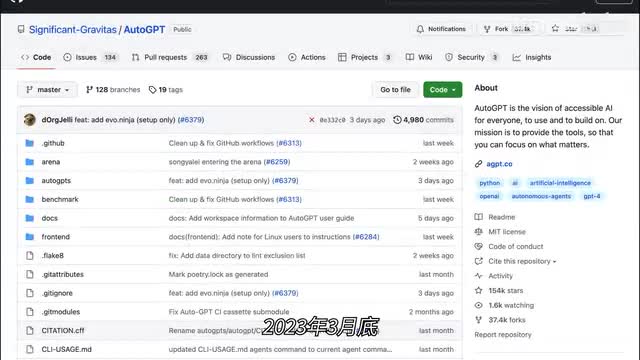
今天你跟他掏心掏肺的聊了半天,明天他就不记得你是哪根葱了。这让他的实际应用处处受限,离我们所设想的通用人工智能似乎还差很远。所以自从g p t出现以后,就有很多人在想,如何利用g p t的先验知识,让a i做出更多的事情。二零二三年三月底,一个叫做auto g p t的开源项目首先做出了尝试。他在chat g p t上封装了一套框架,补全了chat g p t所缺的这些东西。于是一个全新的概念出现了,这就是a i agent。此后国内外一票厂商也迅速跟进,纷纷推出了自己的ai agent框架。

国外比如auto g p t、baby a g i等,国内做的最早的就是阿里云推出了model scope agent框架,这些框架我们更愿意叫他们a i智能体。一个什么样的ai我们才可以叫它智能体呢?首先它必须有独立的记忆,它要记住自己是谁,记住过去发生的事情,并形成自己的记忆流。然后他必须有规划,如果他有一个目标,他应该可以根据先验的知识,过去的经验,来把这个目标分解成一个一个的任务。然后按顺序去执行它。比如先赚他一个亿,最后他得有行动能力,具有在现实世界中实现他的渠道。这三样都是大模型所缺少的。所以几乎所有的agent的框架都是在这三个层面补全了大模型的不足。

如果你了解过任何一个a j的框架,你就会发现它们一般分为四个模块。最中间核心的肯定是大模型的调用模块,它通过调用大模型的a p i来实现决策。在大模型模块之外有三个模块,分别是记忆、计划和工具。记忆模块负责存储记忆,比如一个医疗ai。最好能记住你过去和他聊过的一切信息,这样才能更好的判断你现在的身体状况。计划模块负责把目标分解成需要实现的一个个任务。比如你让a i策划一个生日派对,他至少应该知道去网上选蛋糕,准备礼物,制作邀请函,并检索出你的好友,一个一个发给他们。

而工具模块则是去调用很多网站的a p i或者小模型去完成一个一个任务的过程。比如在网上找蛋糕店搜索评论选择最好的,然后调用支付接口下单调用图片生成ai制作邀请函等等等等。他们就像积木一样,可以搭建到大模型之上。甚至对于不懂代码的普通人来说,你也可以在可视化的工具中轻松实现一个属于你自己的agent。你别不信,比如up就可以在十分钟之内用开源框架给你搭一个自主演进的小游戏出来。turkey is cheap. show me code. 我们选择阿里云魔搭社区的model scope agent来试试看。首先你需要一个摩哒社区的账号登录以后,我们可以进入这样一个地址。
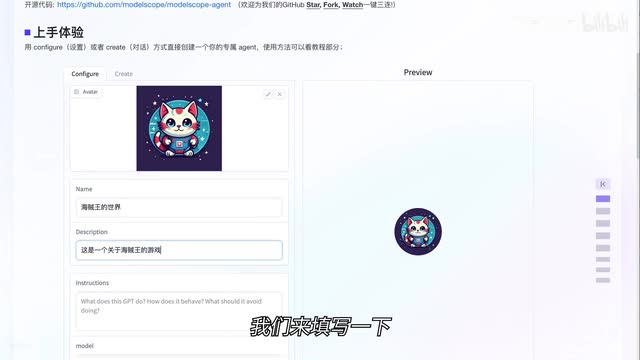
然后我们就会进入这样的一个界面,这就是摩哒专门为大家准备的可视化界面。我们可以在这个界面上直接填写游戏设定,就可以做自己的小游戏了。没错,就这么简单。我们看到界面左侧是游戏的介绍、标题、描述、简介等等。我们来填写一下下面简介。这一段稍微复杂一点,我们准备了一个现成的具体任务说明,初始设定用户输入开始游戏巴拉巴拉什么意思呢?这一段其实是发给大模型看的。如果你看过代码就会发现,程序会把这一段作为提示词直接发给大模型。
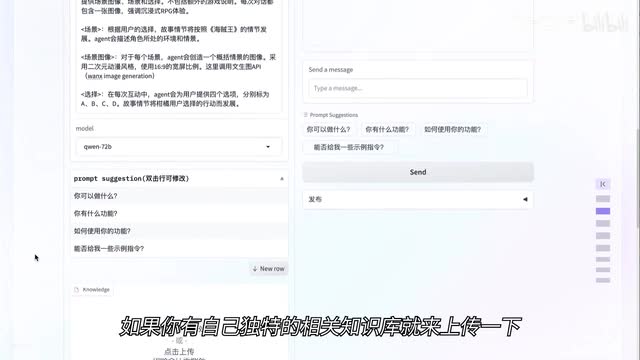
大模型就会记住这段提示词,根据提示词内容设计的场景,按照提示词要求的规则来回答问题,这是我们整个agent的核心。下面的这项模型,我们来个最新的阿里云刚刚开源的千问七十二b知识。这块是上传知识库的。如果你有自己独特的相关知识库就来上传一下。比如你要做一个新时期公园的问答,你可以把我们的所有稿子和背景资料做成知识库传上去。在下面能力这一项是调用外部能力的。比如你要用到文生图的功能,就可以选择通义万相文生图能力。
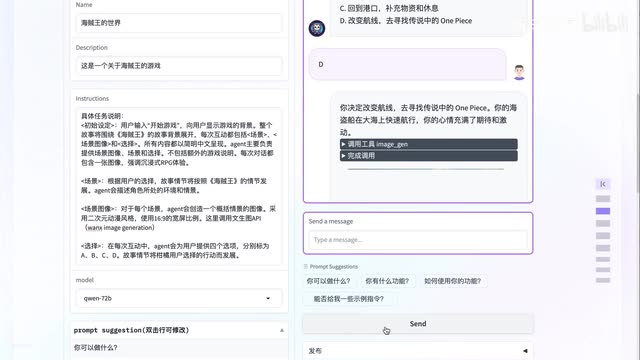
最后点击更新。你看到了右侧的预览界面已经变化了,试一下吧。如果你满意了,点击下面的发布,一款你自己打造的基于a i大模型的小游戏就已经实现了。怎么样?就这你说的我都懂,就是在大模型外面包个可让他实现一些更复杂的任务嘛。但是斯坦福小镇的居民这样复杂的东西也是这样简单粗暴的拼出来的。是的,没错,你别不信。虽然up算法能力有限,只能搭出一个小游戏,但基本结构和原理是相通的,只不过斯坦福小镇在记忆和规划层面做了更多精巧的设想。

因为斯坦福小镇有很详细的论文,并且代码也做了开源。我们索性就具体看看斯坦福小镇是如何实现的吧,也给你在产品设计上开开脑洞。首先我们来看记忆,斯坦福小镇居民的记忆来自于他们日常的活动,包括他自己所做的事情,以及他观察到周围环境中所发生的事情。比如一个叫做伊莎贝拉的a i在咖啡馆工作一段时间内,可能会发生这样四件事情,一、伊莎贝拉正在摆放糕点。二玛瑞亚在喝咖啡的同时准备化学考试。三、伊莎贝拉和玛瑞亚正在商量在哈布斯咖啡店策划情人节派对。四冰箱里什么都没有。

这四件事情就会按照顺序记录到一个叫做记忆流的列表里。像这样,但这种记忆流的记录方式有很大的问题,很快你就会积累非常多的记忆。这些记忆不光不便于检索,并且会有很多无关紧要的事情。比如如果有人问伊莎贝拉,你最近在忙什么呢?伊莎贝拉应该怎么回答?他的记忆流充满了像冰箱空了或者刷牙、洗澡、睡觉之类的记忆,总不能把这些都一股脑的告诉对方吧。所以我们需要一个很好的记忆检索系统,能够把最关键的记忆提取出来。斯坦福小镇中采用了一个检索函数来解决这一问题。他们从三个角度为一条记忆打分,时效性、重要性和相关性。

离现在越近的事情,肯定应该更容易被想起来,这就是时效性。失恋这种记忆肯定比每天刷牙洗脸、例行公事更让人刻骨铭心,这就是重要性。如果问你与音乐相关的问题,你所有和音乐相关的记忆肯定更先被提出来,这就是相关性。按照这三点给每一条记忆加权组合评分,就可以挑选出最有用的记忆了。接下来的过程可不是直接把这几条记忆扔给对方,agent需要把这些记忆放到提示词中,连同对方的问题一起扔给chat g p t。chat g p t会根据这些情况给出一个合理的回答。agents收到这个回答以后,把这句话说给对方听,好吧,这看起来就像你去相亲,但你一句话都不会说。

你需要把眼前的一切告诉远方的恋爱高手,让他一字一句的教你怎么回答。所以现在你明白agent为什么叫agent了吧。接下来一个更难的问题,a i是如何感知到自己的社交关系并对周围的人做出评价的呢?比如谁跟自己更亲密一些,谁和自己很疏远,竞选人sam是不是适合成为市长?如果仅仅是简单的记忆列表,是不足以得出这些结论来的这需要a i具有一种更高的能力反思。在斯坦福小镇中,a i的反思是用一种非常巧妙的方式实现的。a i会把最近的一百条记忆全部都列出来,然后扔给chat g p t,直接问他基于这些事情我们可以回答哪些主题的高层次问题。说白了就是把记忆直接抛给g p t看我都干了这么些事了,你有啥问题要问吗?g p t就会搜肠刮肚的想出一些问题,比如你和张三的关系怎么样啊?然后agent就用这个问题去自己的记忆流中搜索到。这个时候就跟第一步一样了,加权相加以后,最重要的几条记忆就会被检索出来,然后agent再把这几条记忆扔给g p t。
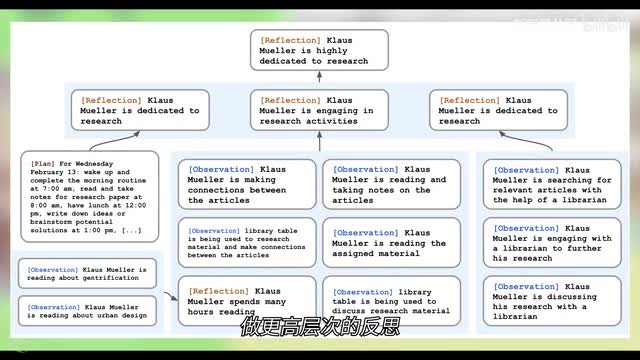
张三请我吃饭了,张三给我买东西了,张三看见我大老远就跑过来哈哈哈哈,然后问g p t你觉得我和张三咋样?g p t根据这些信息回复一个,我觉得张三挺喜欢你的哦,原来张三喜欢我哦。agent把这条回答拿过来作为反思,放到自己的小本本里嗯,记忆流中,这就是a i agent反思的过程。有意思的是因为反思本身也是记忆流的一部分,所以agent还可以把这些反思作为记忆再次提交给g p t做更高层次的反思。最终形成一棵反思树。然后我们看计划,与一般的a i agent的不同,小镇居民需要知道自己的一天应该怎么度过,所以他需要有一天的计划。这个计划是怎么产生的呢?是通过一种递归的方式一步一步拆解完成的。首先agent会向大模型提供自己的基本信息,自己是谁?自己是做什么工作的,自己的兴趣是什么?自己最近的目标是什么?让大模型帮自己制定一天的计划。

然后把这个计划先保存在自己的记忆流中,接下来取出计划的第一部分,然后提交给大模型,让大模型继续把计划细化成几部分。就这样反复几步,一天的计划就被细化好了,agent的按照这个计划来安排一天的行动就可以了嗯,等等。假设张三的计划是出去买自行车,但是一出门就碰到了自己暗恋的小美,然后小美说要不跟我去小树林散散步怎么样?张三应该怎么回答?不行,我要去买自行车,没时间去散步,再见。所以计划是比不上变化的,这种情况怎么处理呢?什么时候应该坚持计划,什么时候应该做出变化?很简单,还是交给g p t来决策。agent会老老实实交代自己的背景,我是谁?我是干啥的?我和小美是什么关系?我计划去干什么?然后小美跟我说了啥,最后问g p t我应该咋回答?g p t会说这还不赶紧去散步,还要啥自行车啊,agent于是就改变计划和小美去散步了。这就是小镇居民基本的决策和行动模式了。怎么样?不管结构多复杂,核心的结构还是去大模型做决策。

内事不决问模型,外事不决还是问模型。看到了吗?并没有什么黑科技,更没有什么意识觉醒。就是这样很low的方式,在a i agent的精心的设计下,仍然呈现出了惊人的效果,甚至让我们看到了一种虚拟社会的雏形。同样是调用大模型,只要你想法和创意足够好,我们当然也可以做出类似的东西。所以ai agent不在于实现架构有多么高深,而在于对现实问题的理解和创意。只要想法够好,解决的问题足够痛点,就可以做出足够好的应用。当然作为一款国外的应用,斯坦福小镇背后调用的是g p t三点五,g p t本身是闭源的。
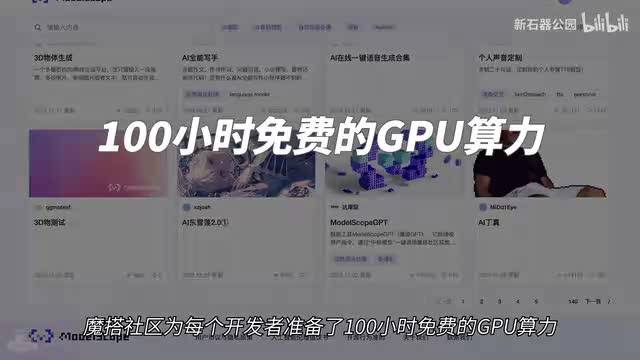
他没有办法在模型层面做出任何调整,所以这从一定程度上限制了agent的进一步发挥。并且因为token的调用是收费的,所以整个小镇运行会产生很高的费用。这一点上我们前面演示用的model scope agent显然更有优势。摩达社区为每个开发者准备了一百小时免费的g p u算力。agent还还可以调用通义千问大模型和数千款开源模型。早在几个月前,阿里云就已经开源了自己旗下的一堆大模型,包括七十亿和一百四十亿参数的大模型。现在阿里云干脆直接把七百二十亿参数的大模型也直接做了开源,性能更是杠杠的。

超过大部分商用闭源模型提供一个链接,大家可以自己去试一下。此外阿里云还开源了音频理解大模型千问audio和视觉理解大模型千问v l,让模型既能听又能看,完全具备了多模态的能力,给你打造具有现实世界感知能力的ai agent创造了更多可能。所以对于我们来说,如果你要打造斯坦福小镇这样的东西,基于众多开源模型,你的发挥空间肯定会更大。开源的agent的框架加上开源的大模型,这给我们各行各业的普通人带来了机会。开源模型透明安全,可以进一步进行训练,使用成本低。对普通人来说,这就是站在巨人肩膀上的机会,通过a i agent来实现与大模型的嫁接,把自己熟悉的领域需求转化为a i工具。是我们与a i最零距离的接触,也是登上a i的高速列车最现实的途径。

i t互联网几十年来之所以能够迅速发展,并让大量科技创新以极低的成本惠及每一个人,正是建立在大量开源共享的基础上,不用重复造轮子,全人类的智慧在共享的平台上汇集。发出新的智慧。阿里云自己做模型开源,并搭建开源模型社区,魔搭一整套开源生态的组合拳,将大模型直接带到了每个产业和开发者身边。阿里云目前已开源一点八b七b十四b七十二b等尺寸,是业界首个实现全尺寸开源的科技公司,谁都能找到一款合适应用落地的大模型。毕竟就像前面说的,a i agent概念虽然很炫,但实际不过是大模型的牵线木偶,它背后的大模型才是最重要的。从这个意义上说,开源的大模型更具有现实意义。想象一下,如果有一天这世界上已经布满了各式各样的a i agent工具和机器人。

而支持他们所有决策的大模型却只源于唯一一家商业公司。这是不是一件很恐怖的事情?所以我们需要开源的大模型,我们也需要自己的大模型。毕竟close的a i或许能赚钱,但只有open的a i才能真正惠及世界。




