
能用中文输入生成,免费不限量。在今天刚刚举办的云栖大会上面,曾经推出过妙丫相机一五一某等大热门a i g c产品的阿里,终于官宣了他们的通义万相a i视频生成模型。内测体验了几天,我隐约觉得它很可能是目前市场上最适合小白的a i视频创作工具。为什么这么说呢?这次通义推出的视频模型准确来说有两个,分别是文声视频和同声视频,涵盖了这两条最常见的生成路径。它们集成了通义实验室的多向性技术,而且专门针对运动生成和物理建模做的算法优化,号称是生成复杂、大幅度但却连贯的运动,并准确还原真实世界的物理规律。

前阵子火过的那些操作,什么影视剧乱创老照片,动起来抱一抱小时候的自己啊,都能用它来实现。你可能会觉得这没什么,因为现在几乎所有的视频生成模型好像都在卷这一点。但它有一个非常突出的亮点,就是它的语义理解能力,对提示词的理解相当准确。你想在视频里生成什么,它都能给你准确呈现出来。深入挖掘以后,你还可以直接通过提示词控制画面、运镜、拍摄性别,甚至是设备镜头类型。

此外这个模型在概念的组合能力上也展现出了非常。强的竞争力。所谓概念组合其实就是提示词里涉及到多个不同元素时,它们能否有机的结合在一起,提供符合我们预期的生成结果。随便展示几个案例,像什么猫加p r眼镜,公女加自行车结合在一起都毫无违和感。这两个点共同支撑起了一个比较抽象的概念,就是模型的想象力。

它可以拉高模型的上限,帮助我们去创造很多以前我们难以想象的内容。他们的官网上有一个非常有代表性的案例,就是一个猫变少年的提示词是通过纯文字控制的方式实现的变化。我尝试了一下类似的格式,还真能做出不少有趣的东西来。另一方面它也保障了模型的下限,就是只要你能做到准确描述核心元素,它基本都可以端出一个还不错的成品来。它的原始生成分辨率也达到了七二零p而且细节比较饱满,配合一些视频超分手段,应该能很轻松的达到可用的级别,基本时长五秒,但真的可以达到三十帧每秒,换算下来其实是优于很多行业里的其他工具呢,如果要给它的综合能力做一个评级,那我觉得在国内可以直接用上的工具里是可以排到第一级别的。
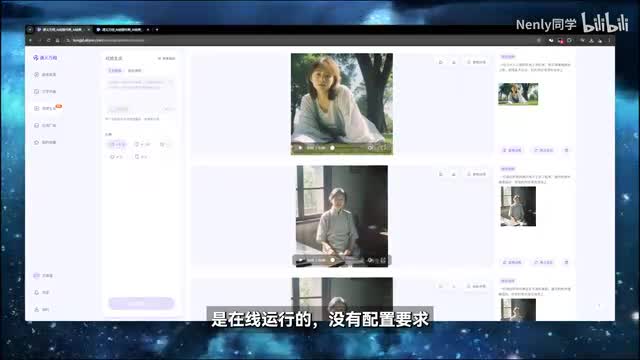
这些是模型本身的素质,但同义万相对新手。友好的另一个方面体现在它的产品形态上。通义万相给用户提供了双端入口,在电脑上和手机端app都可以操作电脑,只要在浏览器输入网址就可以打开。这个主操作界面是在线运行的,没有配置要求,手机上则需要下载这个通义app,然后在频道里找到通义万相的入口就可以进入。之所以说它适合小白,是因为目前阶段它的最大亮点之一就是免费不限量,没有尝试的成本,如果你愿意,现在就可以去试用一下。
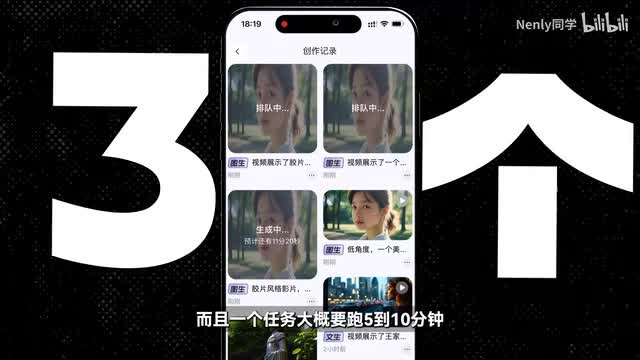
当然,免费可能也会有一个相对的弊端,就需要排队。虽然说是每个人不限量使用的,但实际上它会对并发的任务数量有一定的限制。手机端最多并发三个,而且一个任务大概要跑五到十分钟,不排除和一某刚上那会一样,因为人多会挤更久。它的操作其实很简单,以p c端为例,进去以后在左上角切换纹身视频和图像视频两种模式。纹身视频在下面可以直接选择目标比例。
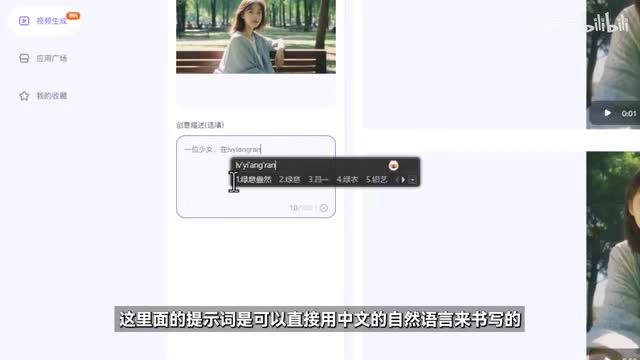
图像视频在上传一张图片以后会让你选择裁剪的比例,但也支持自由比例生成。在下面会有一个这样的框,用来输入提示词。这里面的提示词是可以直接用中文自然语言来书写的,所以只需要把你想生成的东西描述进去。就好了。来支持大段的长提示词输入,最长五百字都可以消化。
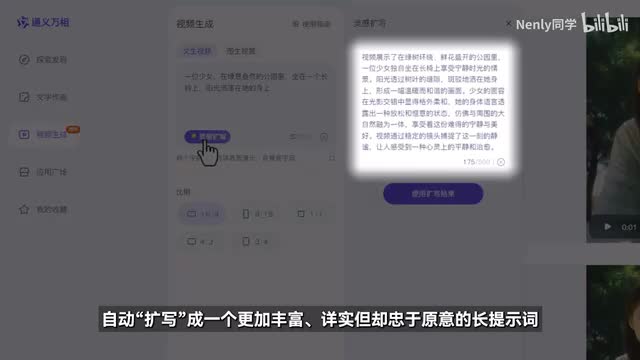
不过屏幕前的初学者朋友偶尔可能也会有这样的一种感觉,就是在生视频的时候不知道该怎么去描述我想要的画面。通义万相里面就有一个很神奇的功能,叫做灵感扩写。在文章视频里面点一下,它就会把你输入的简单描述词内容自动扩写成一个更加丰富详实但却忠于原意的长提示词。这个小功能我觉得真的是新手福音,应该是接了他们自家的通义千问大模型,体验相当丝滑。那这样扩写到底有没有用呢?字多就一定好吗?我也做了一个小小的对比测试,可以看到在描述成分更加充实的情况下,画面的表现力是会有非常明显的提升的。

而且写出来的部分也包含了很多氛围感的描述成分,比如温暖、梦幻,其实都会在画面中以一种奇妙的方式体现出来。在这个功能的加持下,即便是从来没有接触过生成式ai的新手玩家,也能非常快速的做出一些不错的视频效果来。目前它只有在文章视频里有这个入口,但对图像视频也可以提供帮助。你完全可以在这边扩写完了以后,再把提示词复制过去生成。这个通义万相还有一个隐藏的玄机,就是它会给生成的视频配音。
在画面包含具体形象和动作的时候,它一般就会配上一些和动作吻合的小音效,一些中远景的镜头则会直接给加上符合情境的环境音,甚至是背景音乐。在这之前,几乎所有我用过的a i视频工具都只能生成无声的片段,需要我们后期人工配音。市场上也有一些主打ai配音的工具,但都需要先生成视频,再到独立应用里去完成。这种一步到位的功能也给初学者做创作提供了相当大的便利。另外我拿很多类型的提示词做了测试,发现这个模型还挺精通不同的艺术风格的,像比较热门的二次元动画c的建模风格都能很好的展现出来。

值得一提的是,它还挺懂国风的,据说是有针对性优化一些中式元素的概念理解与生成表现能力。像之前用一些国外的模型生成我们的传统服饰和建筑等元素时,总是很容易出问题。那么通过这个能听懂中国话,读懂中国风的模型里就简单多了。在我看来,这种风格上的多样性也是一个便利新手小白的点。因为现在主流的ai视频生成操作路径。

其实适合ai绘画技术强捆绑的图像视频,图像视频可以更精确的控制画面里的元素,但前提是你得先得到一张让你满意的图片。比如你想做这种毛毡风格的动画短片,就得先通过合适的模型或plus画出一张这样的图片来。对于真正零基础的用户来说,还得先去补补a i上图的课。但现在靠文字指令就能精确定位到这些富有表现力的艺术风格上,真的是一种非常大的提升了。总的来说,你可以用通义的这个模型的很多的图像一个图像视频。
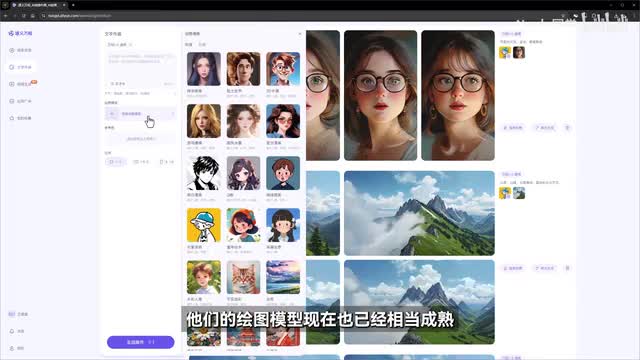
我觉得在它的加持下,要做一些有具体故事情节的短片动画已经不是什么难事了。有大模型扩写自动配音的功能帮忙,几乎可以一站式成片了。如果你更希望通过类似于图像、视频的方式加强对画面的把控,那也可以随时切换到同一万相内置的绘图功能,他们的绘图模型现在也已经相当成熟,有各种风格和控制功能,可以帮助你轻松打造出一张满意的手真图片。假如你本身就精于ai绘图,那你可以借助图像视频塑造更多独特的艺术风格,或者给现实世界中的视频加上各种有趣的特效,而它生成了一些艺术风格的空镜和动画。也很适合用作p p t或文字呈现的背景。

总结下来,如果要给刚接触a i相册视频的新手小白推荐一个工具,我有很大概率会选它它真正意义上的降低了a i视频创作的一些固有门槛,交给了每个普通人最方便快捷的将自己的想象力具象化成一个视频的能力。大家可以通过视频下面的链接直接进入使用。如果有机会我也挺想和大家分享更多a i视频方面的工具使用,乃至后期剪辑制作技巧。如果你感兴趣可以在公屏上敲个一,这样我就知道下一期教程该做些什么了。这里是哪里?感谢你看到最后,我们下期再见了,拜拜。




