
各位最近肯定看过这样的视频吧,老爹你醒了,走吧,我们去把那个逼养的给弄死。现在就那么这个满嘴芬芳的老爹到底是如何做的?我们该如何复刻自己或者他人的声音?那么今天这期视频我们就来一起研究一下。想要制作a i音频,我们这里首推的软件是由b站大佬花儿不哭所制作的开源项目g p t service免费开源而且非常的好用。各位可以去给大佬的视频点个三连支持一下。那么废话不多说,我们马上开始。
首先我们来获取软件,我们可以在b站上找到花儿不哭大佬的主页。在私信页面下输入下列任意一个关键词,即可得到大佬自动回复。得到g p t service的下载链接,将其下载到电脑。我们推荐各位使用这个v r版本,更新更好用,解压之后即可使用了。g p t service有两个生成模式,一种是可以直接克隆声音,虽然效果较差,但是极为方便,非常适合语音素材较少不够训练模型,或者是时间很紧没时间训练模型的情况下使用。

还有另一种模式就是需要训练具体的声音模型,其生成效果也更好。但是需要一定量的音频素材,训练起来也更麻烦一些。那么我们这里讲解一下第一种更为便捷的模式。首先我们来思考一下,我们想要制作一个a i语音,我们都需要什么呢?我们来举个例子,就比如说我想要复刻成龙历险记当中老爹的声音,妖魔鬼怪快离开,我们得先有老爹本来的声音数据吧。哎没错,这就是我们首先需要的东西,原声音频。
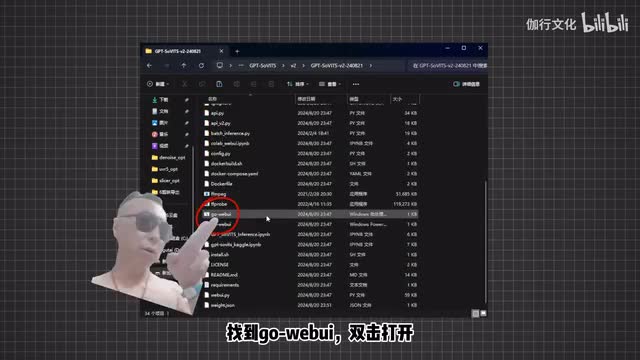
至于音频素材的获取,b站就有成龙历险记的全集,我们可以使用录音工具在动画内进行录制。音频长度在三到十秒钟就好。首先我们来打开刚才解压的g p t service v r的文件夹,向下滑动找到go web,双击打开,接下来就会弹出一个小黑框,这个就是软件的控制台。再稍等一下就会弹出来一个网页,这里就是g p t service的操作界面了。各位注意一下,不要将控制台关掉,这个才是软件运行本体。
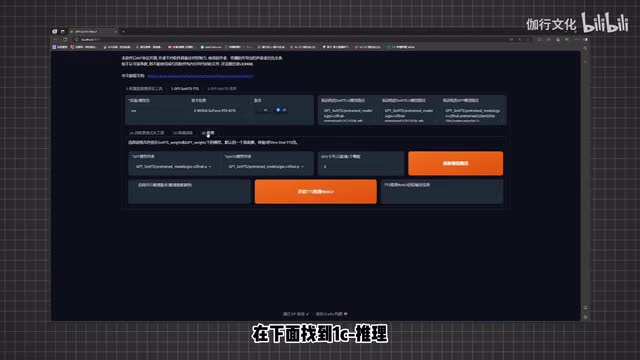
刚才那个弹出的网页只是操作界面而已,关掉控制台后软件就不能运行了。那么接下来将目光回到这个网页的操作界面。我们来直接点击g p t service t t s,在下面找到e c杠推理。这里向各位解释一下,在g p t service中生成语音是需要两个模型的,一个g p t模型,一个service模型。我们保持两个默认模型不变,直接来点击开启t t s推理web u i。
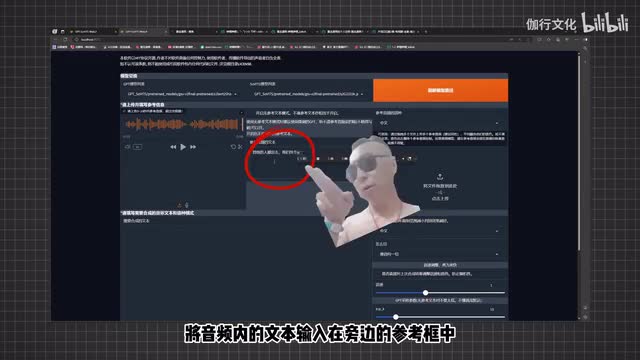
接下来我们就进入到了一个新的界面,在这里我们就可以来正式的生成音频了。我们首先在这里放入一段老爹的参考音频,其他的人都出去,我们找个地方过夜吧。将音频内的文本输入在旁边的参考框中,在旁边我们还可以放入另一段音频作为额外的参考。再向下看,在这里我们想让ai生成什么话,我们就在这里输入什么文本就好。全部准备完成之后,我们就可以来直接点击合成语音。

那么稍等一下,我们就合成完成了啊。一起来听一下成龙小玉去哪里了。哎,这个声音确实是有点一言难尽啊,节奏语气完全不一样啊,音色倒是有那么一点像,但是完全不能用啊。那么该如何让这个合成的语音更上一步呢?那么接下来我们就来学习第二种方法。训练语音模型所需要的音频素材就肯定不止是三到十秒了。
这里我们起码需要一分钟以上的音频素材。我们还是来先找音频素材,将视频内老爹说话的部分单独截取出来。然后我们可以用音频编辑工具将老爹的语音进行合并,合成成一长段的语音。这段语音的时长起码要在一分钟或者两分钟以上。更长一点当然更好,但是也不用太长,五六分钟以内就好。

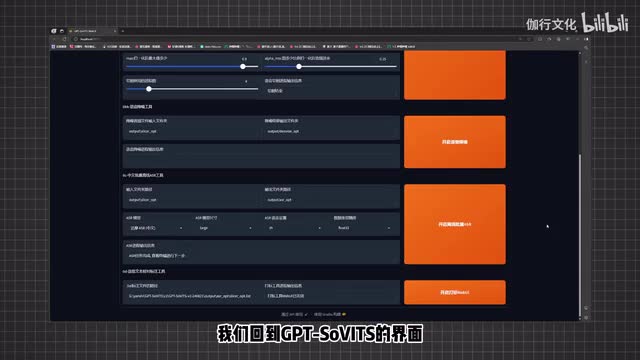
音频过长会导致我们后续调整切割音频或者是文本打标时过于麻烦,而提升效果其实也不算明显。我们这里准备了一个两分半的老爹语音文件,至此前期的准备工作就完成了。接下来我们就可以来打开g p t service,来正式的进行语音模型的炼制了。总流程一共分为人声分离切分、批量打标、校对、预训练、微调训练。我们还是回到g p t service的操作界面中来,点击前置数据集获取工具。
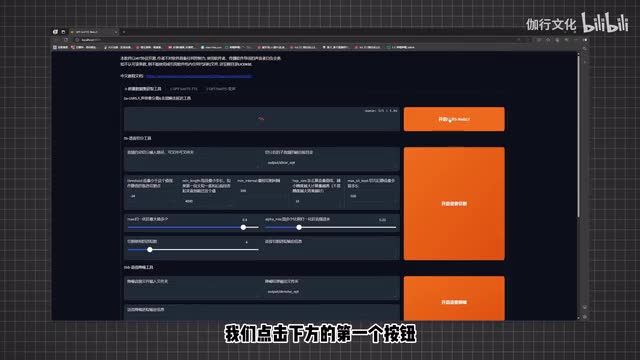
首先我们需要对音频进行一些前期的处理,我们录制的音频往往带有一些环境噪音、配乐等其他声音。我们首先就是要把这些不需要的声音给去除掉。我们点击下方的第一个按钮,开启u v r五web u i,稍等一会儿就会出现一个全新的界面。在上方有一些作者大大给的讲解,我们在这里可以选择降噪模型。这里就按照上面推荐的最干净的方案来做。

先用这个模型转换一遍,然后我们再用这个模型再转换一遍,接着我们就得到了这样一个很干净的人声,我们来对比一下。不准搬回来,成龙不准搬回来。哎,好的,这样人声分离就结束了。我们将u v r五web u i的界面关掉,回到g p service界面中来。接下来我们来对降噪好的音频进行切分,切分是为了更方便的对每段进行编辑,方便后续的打标流程。
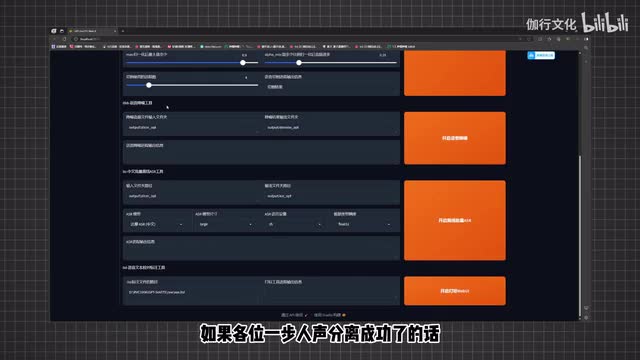
我们来直接点击开启语音切割就好。我们可以看到下方还有一个降噪的选项。如果各位第一步的人声分离成功了的话,这步可以直接跳过。我们来看下方的中文批量离线a s r工具,直接来点击开启离线批量a s r。这一步是为了给我们上一步分割的音频全部加上语音标注,也就是我们所谓的打标。
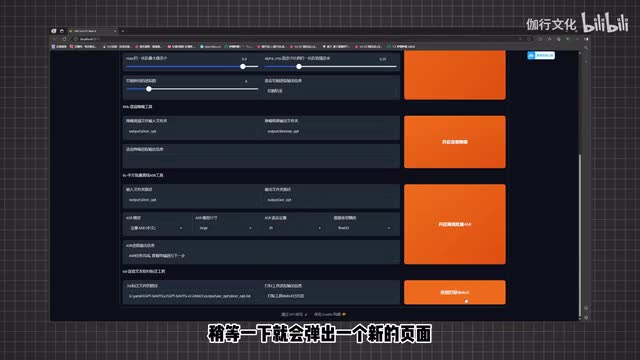
但是这个自动标注并不是很准确,所以说需要我们手动的调整。那么接下来我们来向下看这里的语言文本校对标注工具,就是来让我们方便快捷的修改标注用的。我们来点击开启打标web u i,稍等一下就会弹出一个新的界面,这里就是校对标注的地方,在这里我们可以听到音频来校对边上的文字标注,对不对?不对的话,我们就手动的修改一下,修改之后我们就可以点击上方的。summe test来保存我们的修改。我们两分钟的音频一共切割了二十多段,但是我们可以看到这里只有十多段。
哎,这明显不对啊。这其实是因为这一页只能显示十条,我们来到页面上方这两个按钮就是用来切换上下页的。当我们全部修改好后,点击save food来保存一下,我们就可以直接来关掉这个界面了。我们回到g p t service的界面,此时我们的前置数据集获取工具界面所需的步骤就已经全部完成了。我们来到g p t service t t s的界面,在这里我们可以设定模型的名字与训练的版本。

首先我们需要对训练集进行一些预训练,我们需要将标注文件的地址复制过来放到这里,标注的文件在output的a s r o p t文件夹下。然后我们将训练集音频文件的目录放在这里。如果你和我一样没有进行过降噪处理,那么音频文件就在output的s i l c e r o p t文件夹下啊。如果你进行了降噪处理,那么这个音频文件就在d o o i s o p t文件夹下。将地址填写好后,我们直接来到最下面,点击开始一键三连。
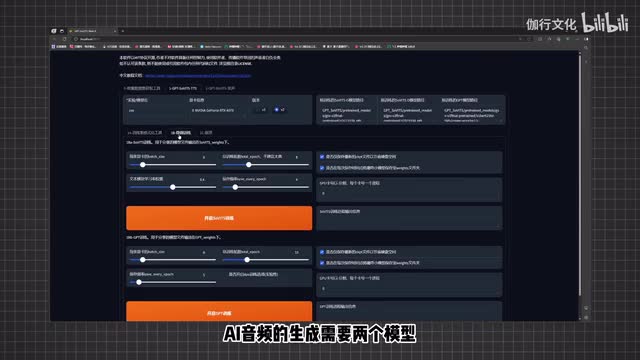
稍等一下,等这里出现一。三连进程结束,我们的预训练就完成了。那么接下来我们就可以开始正式的训练了,我们在上面找到微调训练。我们上面也讲过,a i音频的生成需要两个模型,所以我们这里也需要训练两个模型,其他的参数保持默认。我们来直接点击开启所谓训练,等待一会儿,当旁边出现训练完成就好了。
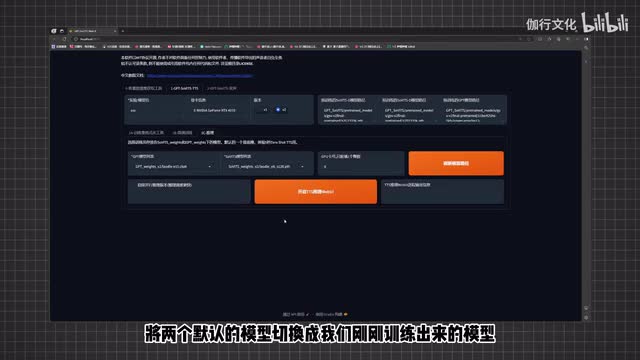
接下来我们来点击g p t训练,再等待一会儿,同样旁边出现训练完成后就代表训练好了。那么好的,接下来我们就可以来使用这两个模型了。在上面找到推理页面,刷新一下模型的路径,将两个默认的模型切换成我们刚刚训练出来的模型。接下来的操作就是最开始一样了,进入t t s推理web u i,放入参考音频,添加参考文本,还可以放一个额外的参考音频。那么接下来我们就可以在上面直接输入文字来进行a i语音的生成了。

我们现在再来听一下成龙教育去哪里了呀唉这个语气、节奏、声线、音色已经非常的接近了,这样我们的a i语音就生成好了。其实g p t service那可调整参数还有很多,我们讲的只是基础操作。单的为大家介绍一下流程,更细致的操作就需要各位来自行探索了。那么好的各位,本期视频到这里就要结束了。感谢各位的观看,别忘了一键三连,谢谢。

我们也会持续分享一些新奇好玩的技术。那么好的朋友们,我们下期再见。




