大家好久不见,我有两个月没更新视频了,因为最近两个月的主要精力都在搞这个新玩意儿。曾经我开源过一个收集十分钟语音素材即可训练的变声器,主打训练素材时长要求低,门槛低。但是十分钟的语音素材仍然不能覆盖到很多素材比较缺乏的人物。于是我定下了个小目标,看看能不能把音色克隆。十分钟的训练门槛进一步降低到一分钟。隐藏任务有两个。一个是五秒极限克隆。第二个是用a语言训练。支持生成b语言的语音。

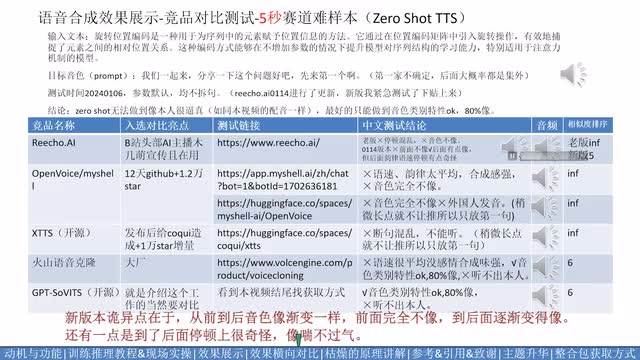
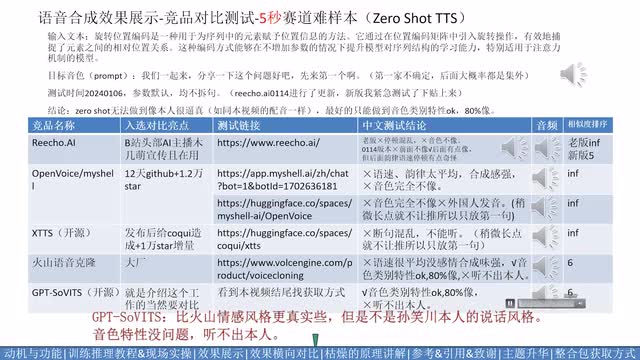
也就是黑键的核心技术,视频结构。接下来的进度条。你们可以根据需求自行挑进度。软件包的获取方式在视频结尾。先说一下这个模型实现了哪些功能。这五秒参考音频推理这个赛道上。它的实现映射下。情感上有像的,还有那么点不像的。不太像的案例主要体现在特质,体现在说话方式和口癖而非音色的说话人上,比如孙笑川,但多数案例还是能做到百分之九十像的。

第二个赛道是文本转语音,少量素材微调。一分钟素材足够微调,得到逼近真人的效果。第三个功能是跨语言的文本转语音推理及训练。素材和用来合成语音的文本来自不同语言。这里目前测试了中文,微调训练即是成功的。外文训练集还没测试。最后两个是变声功能。这个已经实现了。泛化性还在测试中,会在下个视频里进行公布。

有的人可能会问。我看到过很多宣称三秒音频就能克隆的技术。你一分钟的音频并没有什么优势啊。第一,实际上我的语音时长进行宣称是偏保守的。要比较通用的结论才会进行宣传。比如训练必然档案爱丽丝的音频。一分钟素材也能训练的很像。但是这要求音色非常有特质。因此,我当然不能宣称一分钟。

再比如训练集见过类似的因素啊。和训练集没见过。结论差的非常远。这就给展示也带来了很大的可操作空间。第二。只存在于展示页的模型。和敢把它开源,通过广大沙雕网友考验的模型完全是两个概念。几秒克隆的工作我见太多了,大部分分为两类,一类是只存在于展示业的学术数据集中,第二类是进行了开源,但是对各种沙雕网友能收集到的张素材完全没法用。这里对前者我不做点名了,但如果是后者,无论效果怎样,只要你敢开源,给大家体验你的成果。
我都会给你点赞。回到正题,总之我设定的目标是一分钟素材能训练出来推理音色下,那就是成功的。很想了解原理的可以跳进度条,你们也可以自行跳到效果对比部分。下面进入训练全流程实操环节。因为是现场实操我找到了一个前几天在a p p上刷到的直播间,来克隆他的低层音响音色。首先听一下原始音频,看看是否有背景音乐。离了吧。双击b a t文件,打开网页界面。因为原素材有轻微背景音乐,所以打开伴奏分离工具先把它去除掉。
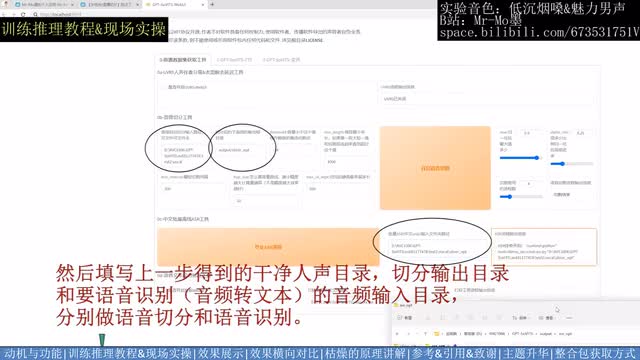
填写音频所在目录,程序会对目录下所有音频文件批量处理输出。在蓝框目录下轻微去除b g m,使用第一个模型即可把分离工具的勾关掉,可以适当分离工具占用的显存,然后填写上一步得到的干净人声目录、切分输出目录和要语音识别的音频输入目录,分别做语音切分和语音识别。语音识别的结果默认在这个目录下能找到。接下来把语音识别的结果文件路径。作为标注工具的输入。开启标注工具进行文本校对。大部分识别的中文都是准的。成本不大。标点位置要修复到和停顿位置一致,听不清的、语速太快的、有杂音的、文本太少的,建议删除。
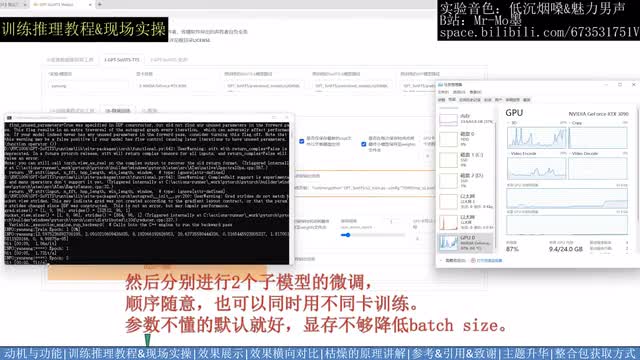
找到标注文件后,我们来到第二个type,先做训练集格式化填写三个打星号的实验名,干涉目录和标注文件路径。然后点击一键三连,等待右下角提示跑完全程,可以看到这个目录下出现二三四五六几个路径。然后分别进行两个子模型的微调,顺序随意,也可以同时用不同卡训练参数不懂的默认就好。显存不够降低bad size显存没什么要求,六g显存大概率就能玩了。推荐大于等于二零系列n卡。训练完来到推理界面刷新模型路径,然后可以下拉选择训练完的两个子模型。选完模型后点击开启推理网页界面。推理前需要先上传一个目标音色的参考音频。并填写对应的文本和语种。

你为什么要一次一次的伤我的心啊?需要合成的文本如果太长,需要进行切分,每行一个子句。这里提供了三个切分方式,你也可以手动切分或不切分,填完需要合成的文本的语种后,点击合成语音等待输出即可。我三零九零的卡大概每秒可以合成四秒长度。比传统语音模型慢一点,比很多新时代的语音大模型要快很多。当然。不同问题之间错综复杂。对应的结论也有冲突。所以我想要的是平衡。也就是在所有问题中找到一个最优解。

后面我换了一个更烟更低层的来扩大测试规模,选的都是比较难的案例。这里看一下效果来说,他就是对我不感兴趣。幸运的是,此次事故并未造成人员伤亡,但两辆车均受到了不同程度的损伤。事故发生后,许多网友对这名女子驾驶行为表示了强烈的不解和担忧,同时也有网友表示,这种行为不仅危害了自己和他人的生命安全,还可能对其他道路使用者造成恐慌和困扰。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。这种编码方式能够在不增加参数的情况下提升模型对序列结构的学习能力,特别适用于注意力机制的模型。先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。

it's more兴奋的海天。so那你搞的话。里啊里面开始侪勿来。i like playing tension. can you tell me how much the shirt is? yes, it's nine fifteen. 后面两页是分两个赛道和竞品的对比测试。个人结论贴在表格里不再念了,这里只放各个竞品的音频供大家对比,表中结论仅代表个人观点。目前各家的效果都是有办法免费体验到的,大家应自己去尝试得出结论,结果最终还将交由后人。比如说我们一起来分享一下这些问题,好吧?先来第一个啊。旋转位置编码是一种用于位序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。

这种编码方式能够在不增加参数的情况下,提升模型对序列结构的学习能力,特别适用于注意力机制的模型。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。这种编码方式能够在不增加参数的情况下提升模型对序列结构的学习能力,特别适用于注意力机制的模型。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。这种编码方式能够在不增加参数的情况下提升模型对序列结构的学习能力,特别适用于注意力机制的模型。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。

这种编码方式能够在不增加参数的情况下提升模型对序列结构的学习能力,特别适用于注意力机制的模型。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。这种编码方式能够在不增加参数的情况下提升模型对序列结构的学习能力,特别是用于注意力机制的模型。可以看到g p t service一分钟和半小时数据训练结果差不多,音质爆破的情况比b v二少些。你们也可以自己尝试训练b v二看。也有可能和训练有关系。孙笑川的数据乔西是有分享的。实际实验室的音色相似度基本是只能和下一页的五秒克隆赛道打了五秒赛道基本上没有人模仿孙笑川的,只有音色相对更像一些的。
这里我放一下测试结果,不太能听的我就不解放了,我们一起来分享一下这些问题,好吧?先来第一个啊。旋转位置编码是一种肉与位序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转位置编码一种用于为序列中的元素赋予位置信息的方法,它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。这种编码方式。能够在不增加参数的。情况下提升模型对虚拟结构的学习能力。特别适用于注意力机制的模型。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法,来相对位置关系提升模型对序列结构的学习能力。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。
旋转为自编码是一种用于为序列中的元素赋予位置信息的方法。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效的捕捉了元素之间的相对位置关系。这种编码方式能够在不增加参数的情况下,提升模型对序列结构的学习能力,特别适用于注意力机制的模型。旋转位置编码是一种用于为序列中的元素赋予位置信息的方法。它通过在位置编码矩阵中引入旋转操作,有效地捕捉了元素之间的相对位置关系。这种编码方式能够在不增加参数的情况下提升模型对序列结构的学习能力,特别适用于注意力机制的模型。听了这么久a r孙笑川的配音,想必大家都听累了。我们请另一个人来接着后续的配音吧。
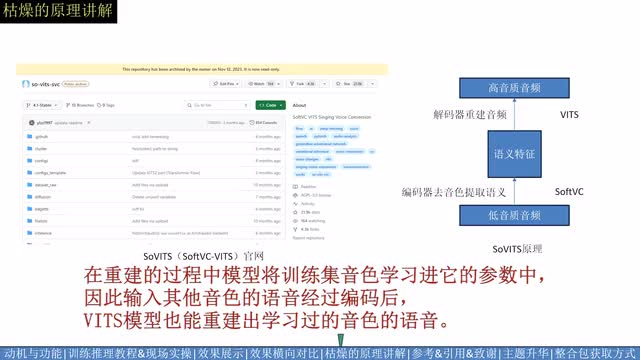
这一部分我将简单介绍g p t service的动机与它的由来。我们从语音转换领域最有名,写上了二零二三年时代周刊前两百大发明的service象棋。service的原理可以很简单的抽象为右图的编码器解码器结构。首先通过soft v c编码器去除音色,然后通过race解码器重建音频。在重建的过程中,模型将训练及音色学习进它的参数中。因此输入其他音色的语音经过编码后,vs模型也能重现出学习过的音色的语音。在这个叙述逻辑中,问题最大的一点在于编码器去音色这一步。事实上目前就没有能完全去除音色的特征,只有去除音色相对强的特征。这也是为什么我们最后会使用content veg代替service名称中的soft v c作为编码器的原因。
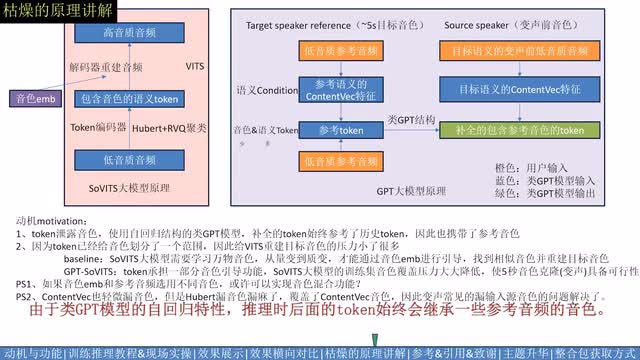
录音色的意思是?你转换转了个寂寞,不太是你想要的那个音色,除了a i的噱头外就没什么太大用途了。但是我们反过来讲,我们完全可以用这个泄露音色很大的语义特征作为音色的引导,来引导目标的音色。于是第一批进入观众席的音色落马的c n robert重新回到了赛场,保留了丰富的音色信息反而成为了它的优势。我们使用u bert和r v q将音频转化为包含音色的语义token,然后使用类g p t模型将它补全。由于类g p t模型的自回归特性,推理时后面的token始终会继承参考音频的音色。又由于token使用的特征漏音色比condition语义特征更大,因此g p t补全的token更多的是包含参考音频的目标音色。在hubert分担一部分音色压力后,剩下的vis的重建目标音色的压力就小很多了。这使得五秒音色克隆终于具备了可行性。这里额外提一个设想,就是参考音频和音色embedding分别承担了一部分音色引导任务。

假如他俩使用不同的音色,是不是可以实现音色混合功能?后面我准备做下实验,看看是什么结论。我们也可以将g p t模型的condition变更为文本。那么g p t service的功能很平滑的从变声切换到了t t s。虽然这次发布的整合包其实是t t s功能的。讲了这么多变声的原理,也是为下次发布变声包埋下伏笔。这里是该项目引用的一些开源仓库,对他们表示诚挚的感谢,特别感谢赛欧大佬在算法层面的灵魂交流,对于该项目技术路线怎么发展,交流碰撞了至少一百次,一起踩过了至少一百个坑。感谢尤里组长在两个月前对我调研语音大模型的帮助。这一页p p t是这个项目后续的工作,上面列举了一些是希望和开源社区的同好一起合作壮大的点,感兴趣的可以暂停观看。下面是我已经有计划和想法的后续研究方向,其中已经完成了模型训练,但是还没有来得及发布的是两个小版本模型,分别是t t s功能和v c功能。

但是还没有来得及融进整合包内,留到下一次发布。前几天刷到一个视频让人感触颇深。这里和大家分享一下这个视频有一个核心观点是开源社区手里有很多实力不亚于资本掌控的a i技术。他们将目前几乎代表人类最先进生产力的a i技术打破资本垄断,免费分享下放给所有人,逐渐让未经过专业训练的普通用户,人人都能享受到最前沿科技发展带来的红利。理想情况下。只要顶尖ai继续保持这种开源的状态,未来的生产关系至少在a i领域就会因为生产力的革新发生巨变。ai的生产力无差别的服务于每个人,类似于共产主义的形态。为什么我对这个视频感触颇深?因为实际上我自己也在做类似的事,团结开源社区一起做出比商业公司更厉害的技术,然后把它以很低的使用门槛开源给所有用户。a i开源共产主义听起来像是一个很久之后的理想形态。
虽然他最后不一定能实现,但我们确实已经能潜移默化地感受到这种潮流带来的影响。就拿b站的a i g c稿件来说,并没有多少是职业搞压的人制作的,也没有多少是专门花钱请技术人员来做的对吧?自己动手使用开源技术已经占据了a i g c的一席之地。a i开源共产主义。不论我有生之年能不能看到他的视线。未来很长一段时间内,我都将持续继续进行开源工作。并不是要图什么,而是一种朴素的个人理想和人生价值。我始终相信,先进的技术被研发出来,就是应该去服务于全人类的。整合包的获取方式,通过关注阿婆主发送关键词后的自动私信获取。你也可以对视频进行一键三连,来加速本项目的研发进度。

我们有缘再见,感谢大家能看到结尾。




