
陪你下盘棋。这一集我们来讲机器博弈。

弈就是棋,机器博弈就是机器下棋。下棋是人类想到的能够体现机器智能最早的方式之一,它代表的是一类决策技能。

a i要做的是在多种可能性中选择最好的那一个。二零一六年,阿尔法狗先后战胜世界围棋冠军李世石和柯洁,轰动世界围棋,曾被称为人类智力的圣杯,以至于当时棋坛上一片绝望之声。
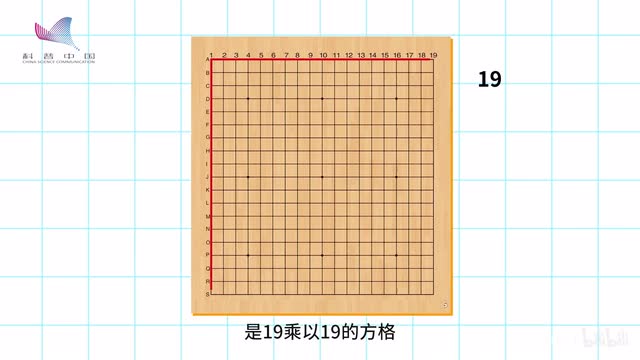
那这么难的任务,alpha go是怎么做到的呢?你想到的可能是暴力搜索,也就是穷举所有可能,找到最好的那一步。但围棋的棋盘是十九乘以十九的方格,每一格可以下白子、黑子以及五子,加起来复杂度达到了三的三百六十一次方,这个数目约等于十的一百七十二次方。

要知道我们宇宙中所有原子的总数也才十的八十次方,所以穷举搜索是不可能的那怎么办呢?我们首要就是想办法缩小搜索的范围。想一想我们人类怎么下棋的吧,我们并不会考虑所有可能情况,而只会根据棋感在脑海里想最好的那几种走法。
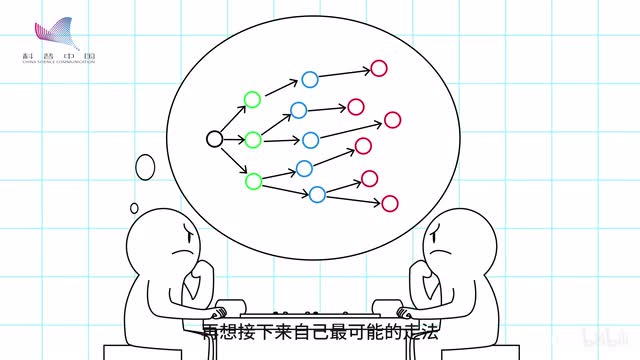
然后再想这之后对手最可能的走法,再想揭下来自己最可能的走法,如此几步,大致做出判断。阿尔法go的思考方式也和这差不多。
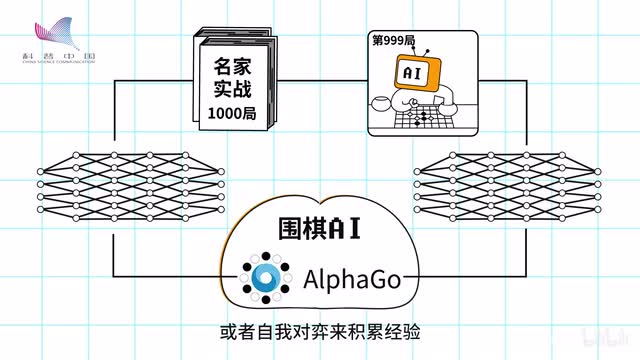
他使用两个深度神经网络来充当自己的大脑,每个神经网络都可以通过学习人类棋谱或者自我对弈来积累经验。其中一个被称为策略网络的大脑,主要思考下一步走什么。

他会凭借学到的经验给出当前棋局下在每一个点落子的概率,那些概率低的点会被他忽略,概率高的点则被纳入考虑范围。而另一个被称为评价网络的大脑,则会根据经验评估在每一步落子之后黑棋或白棋赢棋的机会。
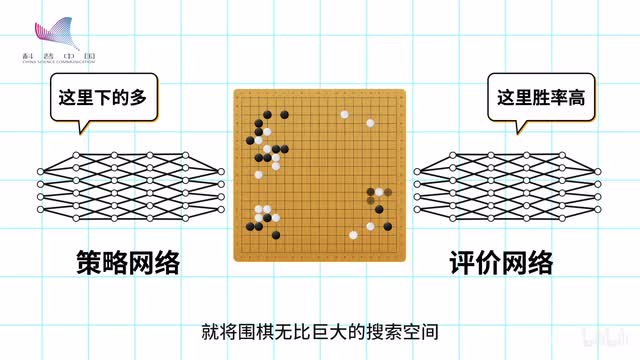
他不关心过程,只关心最后结果,那些评价低的棋局同样也会被丢弃。这样的两个大脑相互配合,就将围棋无比巨大的搜索空间压缩到了可控的程度,alpha go也就此成为一个既能把握全局又能推演局部的围棋大师。
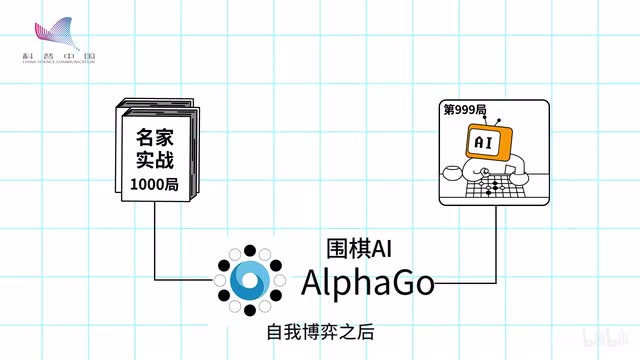
最有意思的是,一开始科学家们使用人类大师的棋谱来给阿尔法狗积累经验,但后来证明加入了随机走子自我博弈之后,阿尔法狗变得更聪明了。这说明人类的认知是有限的,但ai却可以凭借超快的自我探索能力突破这种局限。

最厉害的是阿尔法狗的升级版阿尔法狗zero完全摒弃人类经验,仅通过三天的自我博弈训练,就以一百比零的战绩完败了它的前辈。如果说围棋宇宙有一位上帝,那人工智能无疑是离他更近的那一位。




