
聆听你的声音。今天我们要讲的是语音识别。
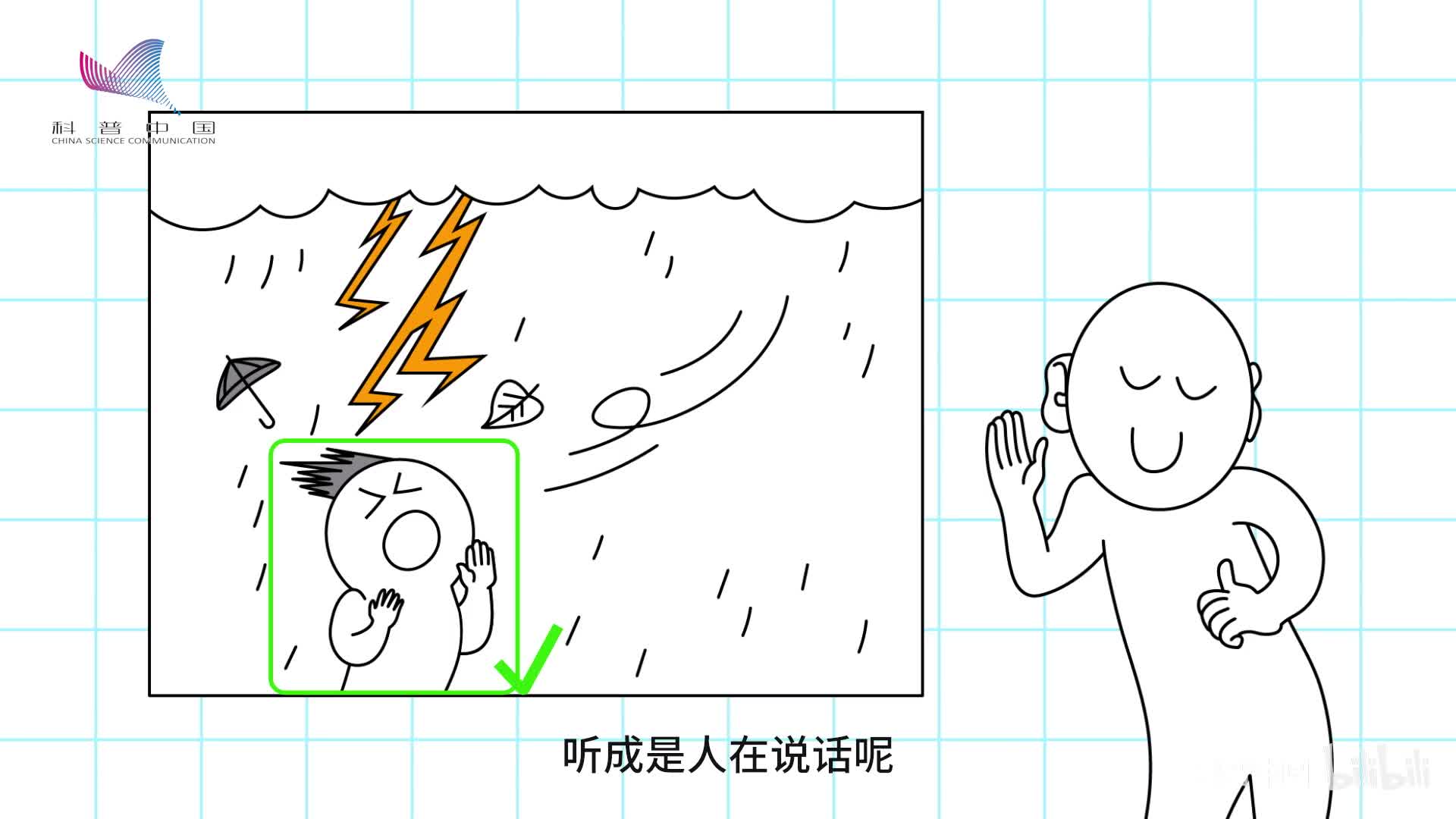
自然界的声音丰富多样,我们为什么不会将下雨声、刮风声、打雷声听成是人在说话呢?因为不同的声音有区别。语音识别的第一步就是将特定的声音区分出来。
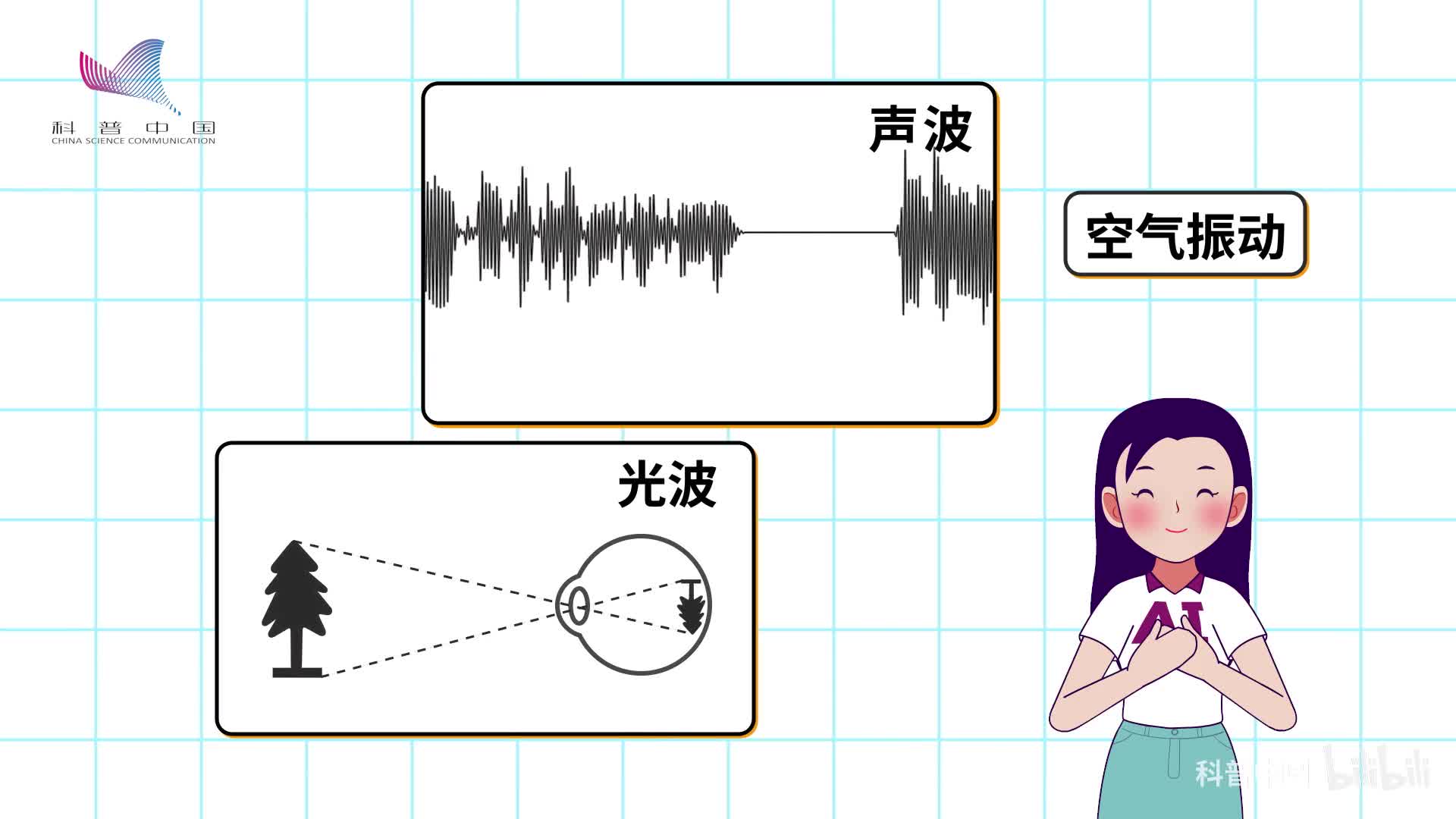
那么,声音的特征如何分辨呢?声音在空气中的传播称为声波,它是由空气振动产生的,就像我们眼睛所见的画面都是由光波产生的。但是计算机不认识什么光波和声波,它只认数字,所以我们的录音设备就要将空气的震动用数字记录下来,这被称为波形图。

波形图上面的每一个点都用一个数字来表示当前时刻下的空气压力,这就是计算机听到的声音。而计算机的大脑还会将它们进行简单变换,变成频谱图,你可以理解为是声音里高低音的分布。
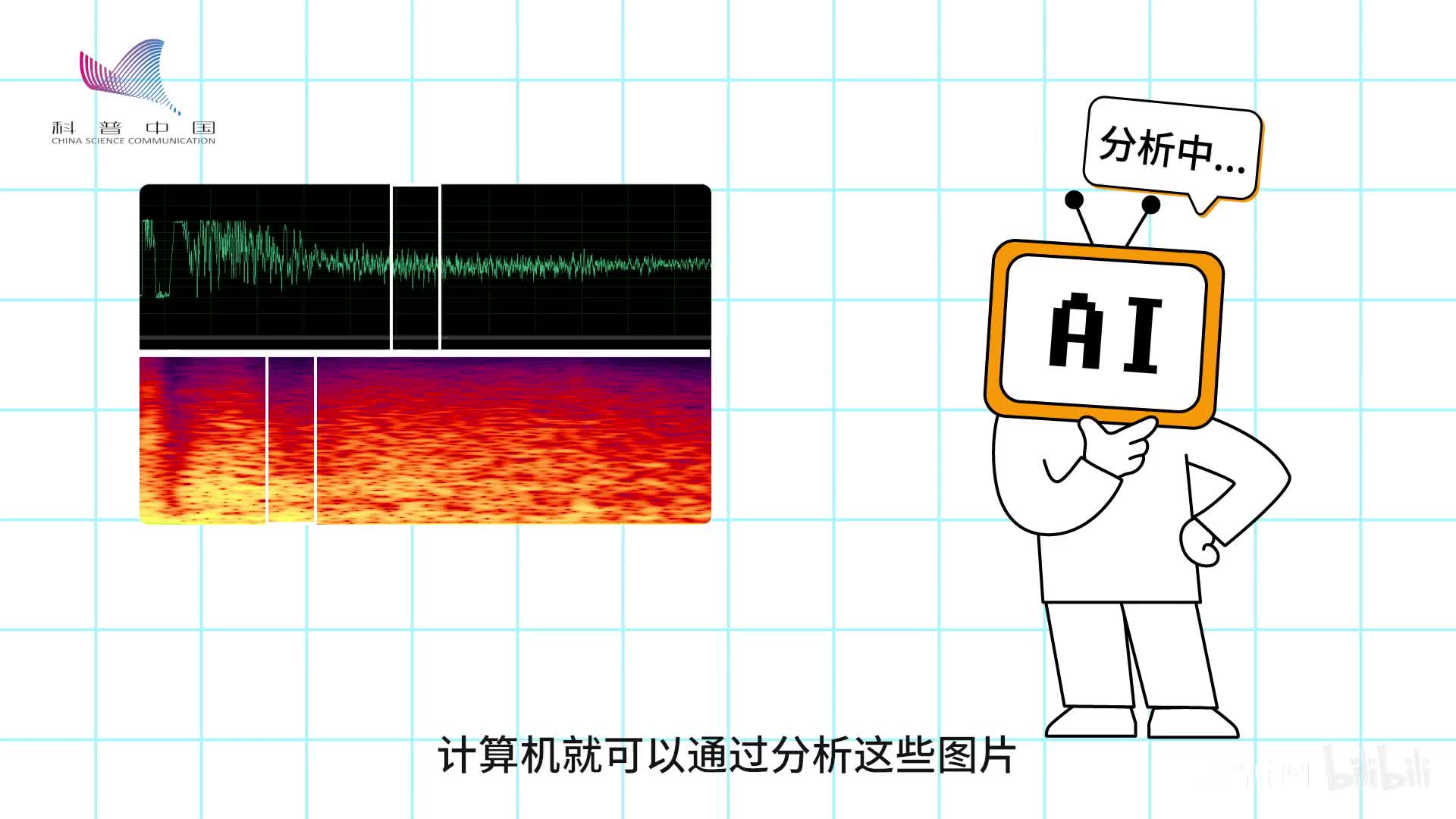
通过这样的处理,声音变成了一种特殊的图片。计算机就可以通过分析这些图片来总结其中的特征,将不同的声音区分出来。

枪声、婴儿哭声、说话声,在计算机的眼里都是很不一样的。就算同样是人类说话的声音,不同的发音内容对应的声音图片也很不相同。

比如人类发啊和一的声音频谱图就很不一样,这是计算机进行语音识别的基础。现代语音识别系统一般都是通过复杂的统计模型,也就是在大量语音数据中找规律来识别语音中的内容。

它们不仅要识别不同的因素,如r o a等,还要将这些因素组合起来变成可能的词和句子。为了达到比较高的准确率,语音识别系统要考虑发音上的各种变异,处理发音之间的关联,还要借助语言知识对识别结果进行约束,来解决同音字的问题。
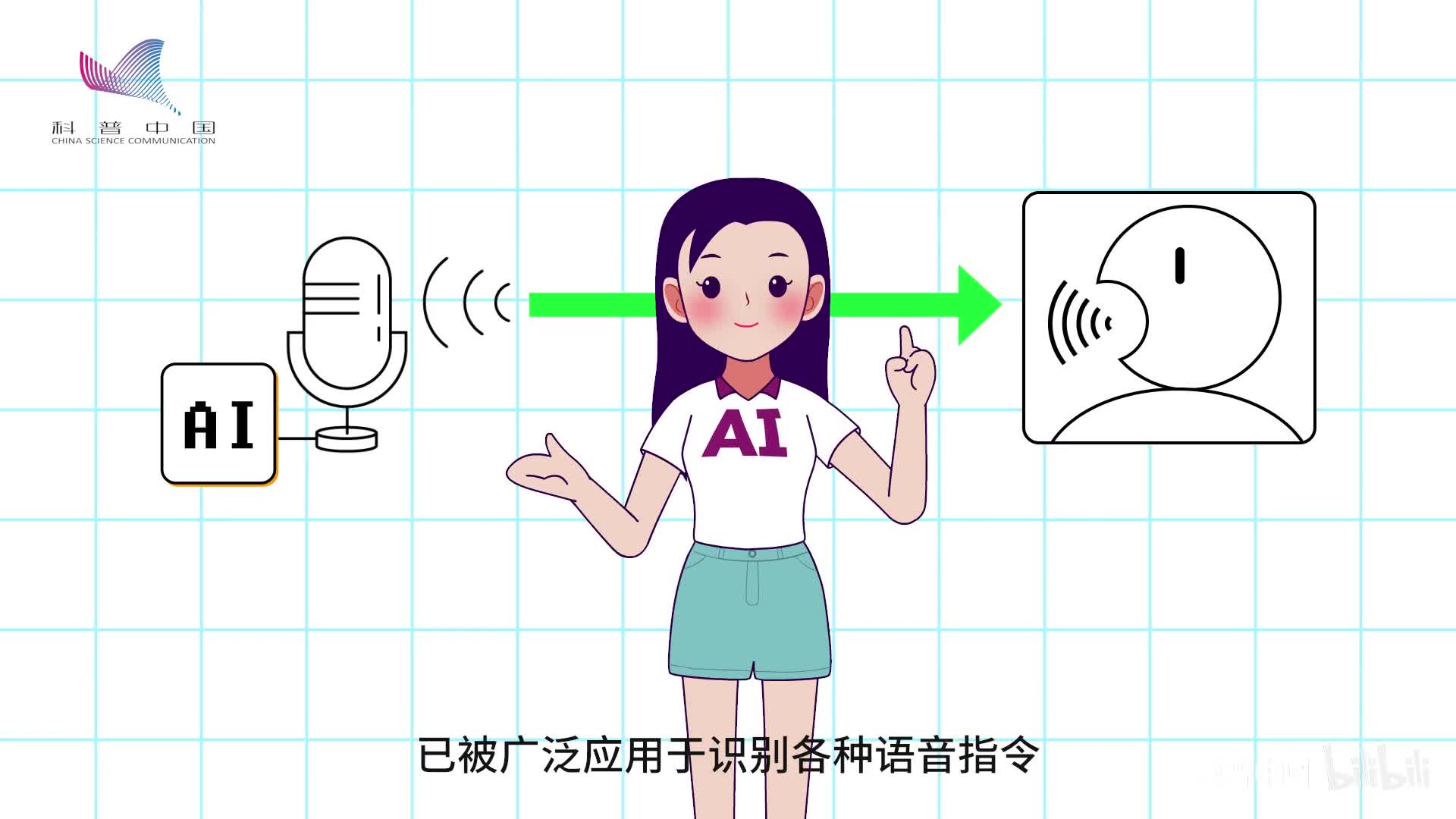
比如我被鱼刺卡了,就比我被鱼刺卡了更有可能性。目前,语音识别技术已被广泛应用于识别各种语音指令,它让我们不用手、只用声音就能向手机、智能家居、车载设备等发布命令,不仅便捷,还能免除不少危险。
除了识别发音内容,机器还可以通过声音验证我们的身份,判断我们的位置,辨别我们的情绪。结合语音合成技术,机器还能模仿人的发音。

有了这些做基础,机器真的成为一位能听会说的好朋友了。




