
如今不管是lp还是机器视觉的ai顶会,如果你不跟大模型沾边重搞想都别想。强如和凯明大神都折戟,今年的c v p二三天投稿统统被拒。当然,我们也可以说在座的所有审稿人都是垃圾。但想众鼎会是离不开大模型的。

然而众所周知,如今大模型对高校极其不友好。动作几千张a一百几十亿美金的训练。根本不是高校玩得起的,都不用说国内高校。就连斯坦福的李飞飞在近日的采访中都提到没卡训练模型。

这位视觉领域一姐有的没的扯了很多,例如大模型的早期创新都起源在高校a i会导致世界不公平等等。不过核心一句话,没卡再不给老子钱买卡就要饿死了。up的一个top two博士学长,每天为了几张三零九零跟组里的同学打的头破血流。别我,我只好扁你。

最后直接下死手,专门写了个程序在组里抢卡。有一个小船立刻就翻了。这还是top two,其他学校还三零九零,就问你一句,幺零八零钛你有吗?这里跟大家讲讲博士科研如何自救。不管是n l p还是视觉领域,如今大模型的主流范式是retraining加s f t。

retraining顾名思义就是预训练,是对通用和基础知识的学习,所以需要茫茫多的g p u。那么brock都属于预训练模型,即便是七b模型预训练也要五百一十二章a一百跑两周到一个月。大理煤矿的一般不要搞,剩下的只能搞s f t了,而且大有搞头。s f t全称叫做supervised fine tuning,是针对特定任务,基于特定数据的模型微调需要的计算资源很少,比如一百万指令微调数据,七b模型在八张a一百零一到二天就可以跑完,相比于patrick已经非常便宜了。
更重要的是在诸多任务上,比如医疗、教育、电商等,只依靠预训练大模型是不够的,必须基于领域数据的进行微调。因此最近在s f t领域涌现出了非常多的高水平论文。s f t一般包含两个步骤,一数据生成,二模型微调。数据生成又有两种办法,一来是人工标注,当然费时费力。
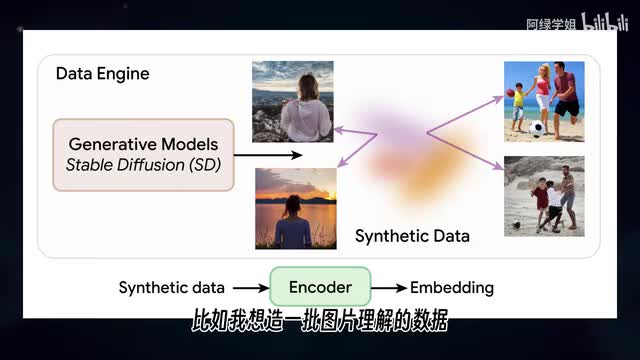
第二种就是调用大模型进行标注。例如使用g p t四o或cloud三点五,不仅速度快而且质量高。比如我想造一批图片理解的数据用于训练图声纹模型。我先找到一批图片数据,然后喂给g p t四,让他替我们生成结果。
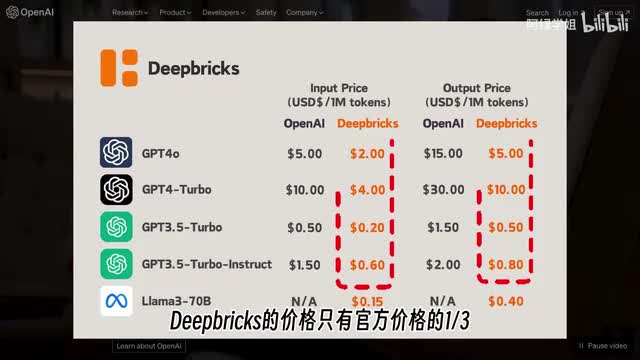
有同学问up说g p t四官方a p i还是太贵了,标注一个问题需要五毛钱甚至一块钱怎么办?这里给大家推荐一个薅open a i和s rapier羊毛的办法,就是最近大火的deep breaks。d bricks的价格只有官方价达到三分之一,效果与官方相同,同时非常稳定。里面包含g p t cloud gale三相关的纹身纹图生文文生图等所有功能。我们用图声纹进行演示。
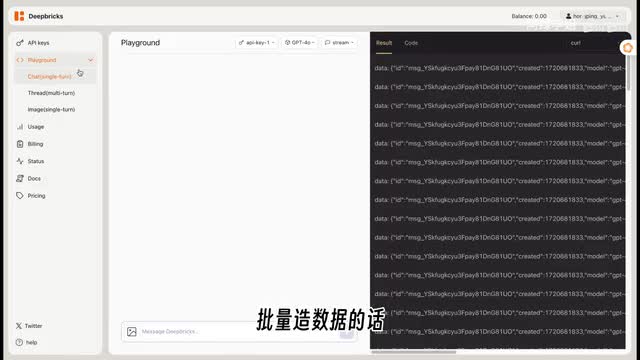
我们先在playground里面上传一张图片,让g p t四o来判断图片中是吉娃娃还是松饼。从结果可以看出一共十六张图片,g p t so每张都准确,识别正确率高达百分之一百。批量造数据的话,我们点playground中的code,选择python open a i模式就可以看到具体调用方式。d bricks同时兼容了open ai的python包,同学们也可以基于之前的项目替换a p i调用地址就可以生成数据了。

详细细节可以看deep breath官方文档和演示视频,生成完数据就可以进行模型微调了。我们这里以拉玛三为例子,介绍一下模型微调的数据代码和脚本,推荐大家直接使用。知名的开源项目lamer factory。这个项目集成了多种大语言模型和微调算法,使用起来非常方便。
首先我们把项目克隆到服务器,然后进行安装之后,确认下微调数据的格式需要和下面的保持一致。下一步对微调过程中的模型参数进行配置,最后在terminal中输入训练指令就可以开始微调了。最后,祝大家今年投保的黑客都能中。




