这个视频挑战十二分钟带你速通所有类型的ai工具。包括a i聊天、ai绘画、a i视频、a i编程、a i智能体,从底层逻辑让你快速掌握,破除a i焦虑症。现在各种ai工具三天两头出一个更新,速度比学的还快,有没有感觉跟不上人麻了。但一旦我们理解各个ai工具的分类、共同点和底层原理,不管它怎么变,你都能轻松跟上。时下流行的ai工具都属于生成式a i这个词可以从字面上去浅显理解,生成式a i就是能够生成内容的a i像人脸识别、内容推荐等等,这些不创作内容的a i都会在我们今天的讨论范围内。那根据内容生产类型的不同,包括文本、图像、视频、代码等等,我们可以把工具划分成对应的分类,带你逐个击破,一通百通,还会带你了解什么是智能体,记得点点收藏。
a i聊天从最简单开始,这绝对是最容易上手的ai工具类型了。只要你知道怎么和另一个人微信聊天,q q聊天,你就应该知道怎么和a i聊天,哪些是这些都是怎么用。每一个a i聊天工具的主页基本都长这样,把你想问的问题或者是你的需求用文字输入进去,回车a i就会返回一串文字来回应你。比如在输入框输入请为我推荐杭州小众旅游景点,回车就能得到答案。嗯,你已经学会了怎么进行用在大多数a i文字创作工具都用的聊天机器人的形式。就因为对话是我们人类最熟悉最自然的交流形式。

但很多时候我们的体验是a i给的答案一般啊,那这个时候不要直接关闭窗口。如果你有一个真人助理,他一次做的不好,你不会直接把它开了,而是会再对它进行一些调教。那我们面对a i也是一样,应该进行下一轮的对话,实现需求表达、反馈、修正的闭环。我们可以指出他做的不好的地方。比如你推荐的景点很热门,我要人少的或者提供更多背景信息,我只能明年冬天去。或者进一步细化要求,需要适合带老人游览的,或者是a i拆分步骤,找出十个必去的杭州旅游景点,然后按游客密度排序,找出其中人最少的三个。
还有如果你要结合网上比较新的信息和问题,一定要打开联网搜索,不然模型知道的信息只会截止到他训练结束的那一天。比如你问今天的金价多少是得不到正确答案的,打开联网搜索后才可能是对的。如果你问的问题需要深入分析。反思一定要打开深度思考,也叫推理模式。模型会先自己碎碎念一大段,三思而后答,给你准确率更高的回复。比如你直接问一个公考逻辑题的选项,答案回答可能是错的,打开深度思考后就是对的。
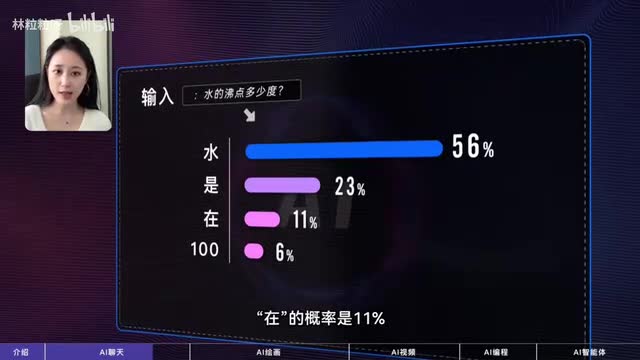
原理是啥?a i聊天工具的原理可以浅显理解为是在做文字接龙。也就是根据你输入的文字以及可能还有对话前面的上下文,去接触下一个出现概率高的字。比如当你问水的沸点是多少度,哎,模型可能计算出来下一个接水的概率是百分之五十六,皆是的概率是百分之二十,三接载的概率是百分之十一点一零的概率是百分之六等等。于是它可能会往下接水,然后以此类推,它继续接龙的沸点在标准大气压下围等等。但这不代表说a i下一个接的字一定是计算出来概率最高的。因为模型会计算出一个概率分布,然后像摇骰子一样选择。

虽然概率高的词更可能被摇到的,概率低的词也有被选择的机会。所以我们问相同问题时啊,模型的回答每次都会不一样。那这个原理。我没给你带来一个警示,也很容易说出看似很对但其实不对的话来蒙骗我们。因为他只会一直猜什么样的回答是正确概率高的,但他不知道自己不知道。对深入的技术原理感兴趣的话,可以看我之前出的a i大模型科普合集a i绘画。

a i可以通过生成一个个文字来创作文本,也能通过生成一个像素来创作图片,当然背后的模型技术稍有区别啊,但我们要做的同样是表达需求,用文字描述出想要的图片内容。哪些是ai绘画工具,最开始以海外的为主,主流的有这些,但各有各的麻烦点,比如m journ和达理,国内用不了的defusing,本地部署配置要求高。mid journey和stable division支持的提示词主要是英文。但好在国内的绘画工具也陆续涌现了,比如克林a i积木、ai文心一格、通义万象等等。怎么用国内ai绘画工具的主页基本都长这样。把你想要的画面用文字输入进去,回车ai就会返回对应的图像。

比如在文生图的输入框,我们输入一个纹玫瑰花的老虎,回车,然后等待画图完成。嗯,你已经学会了怎么进阶,用一张图片上能够包含的远远不止主体,我们还可以在提示词里覆盖场景、风格、光线、材质、色彩、构图、视角、氛围这些成分。比如通过覆盖更多画面成分,我们可以把老虎从这样变成这样。但每次都要想这些很累。我们大部分人都不是学艺术的,描述不出来这些啊。而且有些时候,提示词需要细化到这个程度,才能匹配心里所想的图片,太难了。
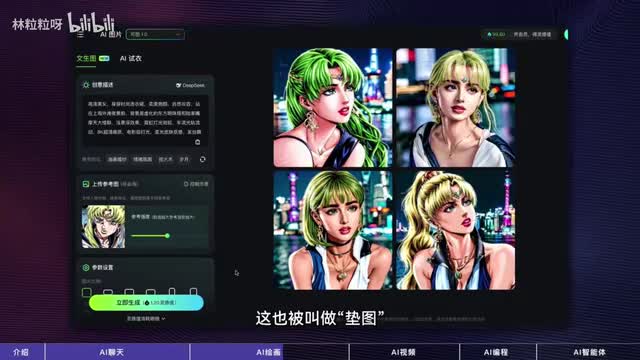
但还有两个方法,第一是让ai聊天工具帮我们出提示词。我们可以先让他根据需求出一版提示词,直接给到绘画工具,如果出来的图片自己不满意,我没办法和绘画工具对话,但可以和聊天工具对话,让它根据反馈修改和提升提示词,再拿新版的提示词让绘画工具出图第二是上传参考图给绘画工具,有些时候我们面对聊天工具也表达不出来想要的,但意图胜千言。可以上传一张图给绘画工具作为参考或起点,让他理解里面的风格或者是主体特征,这也被叫做电图。原理是啥?ai聊天工具做的是文字接龙,那ai绘画工具做的是像素教吗?并不是。一张幺零二四乘以幺零二四的图片上有一百零五万个像素,要知道整部水浒传才九十六万字,你愿意花deep sik生成一本书的时间来等一张图吗?所以图片上的像素不能按顺序生成,而是不同位置上的像素并行生成。a模型生成图片的时候会先从纯噪声,也就是从随便涂一团乱色开始,然后基于你提供的提示词,预测这个图片上要符合描述的话,上面哪些造点应该保留,哪些应该么除。

比如老虎的毛发纹理要留下,背景的杂乱色块要白白。用这种方式生成图片的模型被叫做扩散模型,那通过很多人迭代,不符合的部分被一步步擦除后,就能得到符合描述的清晰图像了。a i视频。电影一般是二十四帧,也就是一秒钟的视频,由二十四张图片组成。ai已经能生成好的图片,但要生成好的视频也不容易,又要同时处理空间和时间维度,但使用上对我们来说没差了,我们要做的还是表达需求,用文字描述出想要的视频内容,哪些是a i视频生成?最开始是open i d a带货的,虽然此前必看方位等已经能生成视频了,但ai生成视频的长度迟迟没法突破二十秒,而sara能实现六十秒的一镜到底。现在国内也有很多不错的视频生成模型,可以在可零a i极梦a i等等平台用到。

怎么用ai生成视频?可以是纹声视频,也可以是图生视频。纹身视频的主页基本上都长这样,还是熟悉的输入框,把你想要的视频用文字输入进去,回车ai就会返回对应的视频。比如在纹身视频的输入框里输入两个宇航员在月球表面漫步,背景是宇宙,回车,然后等待视频完成生成。嗯,你已经学会了图生视频的区别,就是你可以多上传一张图,然后结合文字对视频画面和动作的描述,可以让静态图片动起来。比如给图生视频上传一张美女图,然后输入女生撩头发、转身面向镜头微笑、回车,然后等待图片变成视频。嗯,你已经学会了怎么进阶,用在前面的ai绘画部分,你已经知道可以在提示词里描述主体场景、光线、风格、构图、视角等等成分。

在针对视频,我们可以再增加一方面的描述,那就是运镜,比如镜头可以是环怡、跟随、固定、聚焦、手持、拉远、推进、上扬、酱油等等。记不住这些词的话可以收藏一下,但总之,如果你不知道怎么写,就让ai聊天工具帮你写。原理是啥?前面说了,生成视频不仅需要处理每张图片上的空间关系,也需要处理每张图片之间的时间关系,因为处理不好的话,就会有吹不灭的蜡烛,莫名其妙起飞的玻璃杯,里面每帧静止的图片都没问题,连在一起就变灵异了。所以视频生成ai会用时空扩散模型在图片过。在模型的基础上增加时空注意力机制,换句话说就是对于视频里的任意部分模型,要注意它在图片上的空间位置,也要注意它在视频里的时间位置。a i编程现在都说有了ai人人都能当程序员了,而且a i编程我们不用专门学,因为代码本质上也是文本,直接和ai聊天工具提编程需求就能得到相应的代码。
但如果你是以写代码为生的,掌握专门的ai编程工具可以大大提效。但我们要做的还是表达需求,用文字描述出想要的代码内容。哪些是。这些都是,但a i编程工具现在可以进一步分类成两类,a i插件和a i原生i d怎么用?a i插件要安装在已有的代码编辑器里,原生i d可以直接下载使用,但它们的基本用法都是把你的代码生成需求用注释写在编辑器里。等a i自动生成代码ok的话直接采用,或者也可以让a i自己根据上文续写代码ok的话直接采用。嗯,你已经学会了怎么进阶用。
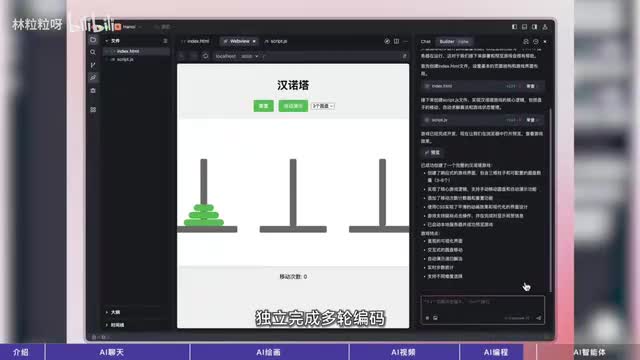
当然代码不全只是编程工具的其中一个功能,我们还可以让它修复当前文件里的bug,解释某段代码自动生成测试只用在工具的对话窗口里提对应的需求就行。ai原生i d可解析全项目的代码架构,而不仅仅是当前文件,更关键的是在某些模式下,比如curse a的a模式,trade的builder模式,可以让ai自己去拆解复杂任务,独立完成多轮编码。那我们提的需求就可以不仅针对一段代码或单个方法了,甚至可以针对整个项目。让它从零开始直接生成最终结果,原理是啥?这些工具本质上做的还是文本生成,所以原理上来说和a i聊天工具没太大差了。a i智能体前一阵爆火的manus淡火了ai智能体这个概念。它除了可以像a i聊天工具那样和我们对话,还可以调用工具来完成某些事情。
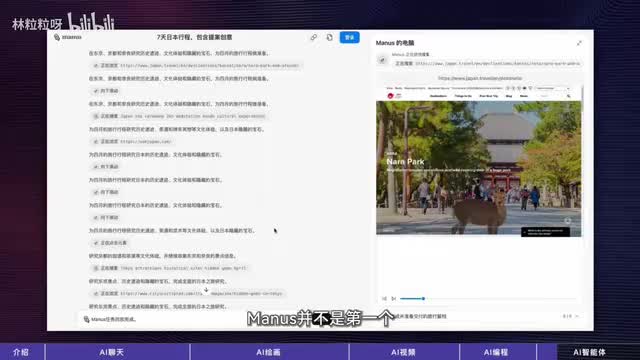
比如订餐厅、网上买菜、填表格。那作为用户要做的还是表达需求。但我们不仅可以让智能体生成内容,还让他实际做事。所以我们可以直接告诉智能体一个最终要达成的目标,哪些是manus,并不是第一个能操作浏览器和电脑的智能体。比如open ai的operator可以和浏览器互动,anthropic的computer use可以和电脑互动。但menus的demo对外展示了一堆多样性和复杂性更高的任务,所以还是更吸睛一些。

但注意,智能体的主要判断标准不是能否操作电脑,而是它是否采取感知、推理、行动的循环。比如一个能操作浏览器的智能体,我们会先给他一个目标,比如发送文件、订机票等等。在感知步骤,它会通过取。的截图来了解目前屏幕上发生的事情。然后再推理步骤,根据现状和上下文思考下一步的操作。接下来在行动步骤里执行具体操作,比如单击往下滚动输入内容等等。
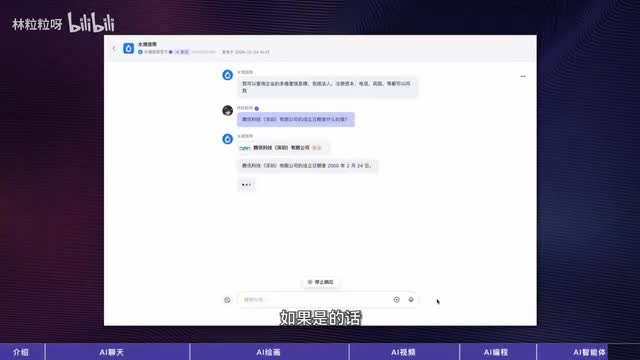
然后再次回到感知步骤,了解这个动作执行后的新现状,如此循环直到目标达成。那操作浏览器只是行动的其中一类,像扣子里别人定义的这些也都是智能体。比如这个查企业信息的智能体会,推理用户问的问题是否涉及到企业信息。如果是的话,行动步骤会调用获取企业信息的a p i,然后在感知步骤阅读从外部获取到的最新信息。所以智能体可以自行分解目标,在需要的时候调用工具,根据外部环境进行推理和行动,更加具备主动性。怎么样使用智能体比理解和创造智能体容易多了。

把你想要达成的目标用文字输入进去,回车,依然会围绕这个目标采取一系列的步骤。比如在输入框里输入帮我搜索香港的旅游资讯,做成一个美食地图,然后发布到公网上面,然后等待智能体干货完成。嗯,你已经学会了怎么进阶,用光是使用智能体的话,不需要掌握什么进阶用法。因为智能体自己就能拆分任务,就能代替人类去感知环境和执行操作。但是当然不同智能体能够调用的工具不同,能力范围自然也不同。找到正确的智能体去完成对应的任务很重要。

所以要进阶的话不如学习如何创造智能体。那这个视频是讲不完了,想学的话可以评论留言。原理是啥?这在前面我们已经了解完了,智能体的运作遵循感知、思考、行动循环,也叫react框架。react代表reason加action。比如针对定机票这个简单的小任务,智能体所经历的感知、推理、行动可能会包含这些。那以上这些a i工具的用法你都学会了吗?其实这样看下来有没有觉得一点都不难,我们要做的都是表达需求,用文字描述出想要的内容。
希望在这个a i工具乱花渐欲迷人眼的时代,能帮你稍微减轻一点a i焦虑。那如果这个视频对你有帮助,也欢迎分享给更多人,我们下个视频见。




