
哎,就在刚刚我用d b c问了个问题,他思考了快一分钟才给我答案。这个响应速度我就秒切其他ai工具了,毕竟谁都不想等太久嘛。于是我们的二零二五a i工具大横屏模型对话流畅度片它来了。看看ai工具在实际应用中的表现如何吧。

咱们这次评测呢专门设置了一个评分标准,生成速度测试。我还专门用a i工具写了一个浏览器脚本插件来进行辅助,让我们现在开始吧。想必你也用过不少a i工具了,今天咱们就来聊聊模型对话能力的那些事儿。从deep sak开源到各大平台接入dep sak,再到国内各大模型纷纷普及,能不能把天聊好是考验模型的关键所在,更是要看看它在长时间对话中能不能保持逻辑清晰,不丢信息,还能玩出点新花样。

我花了整整一周时间,把市面上十款主流国产a i模型,从豆包、kimi到文馨妍、deep sik挨个拎出来。军训测试方向我们主要分为五个,长时间,对话、回归、宕机、懂不懂个性化交互、角色扮演、专业不专业,以及响应速度和突发性的类型。以上问题直接关系到了咱们用a i工具时的体验,靠谱不靠谱就全看今天了。下面直接上干货。
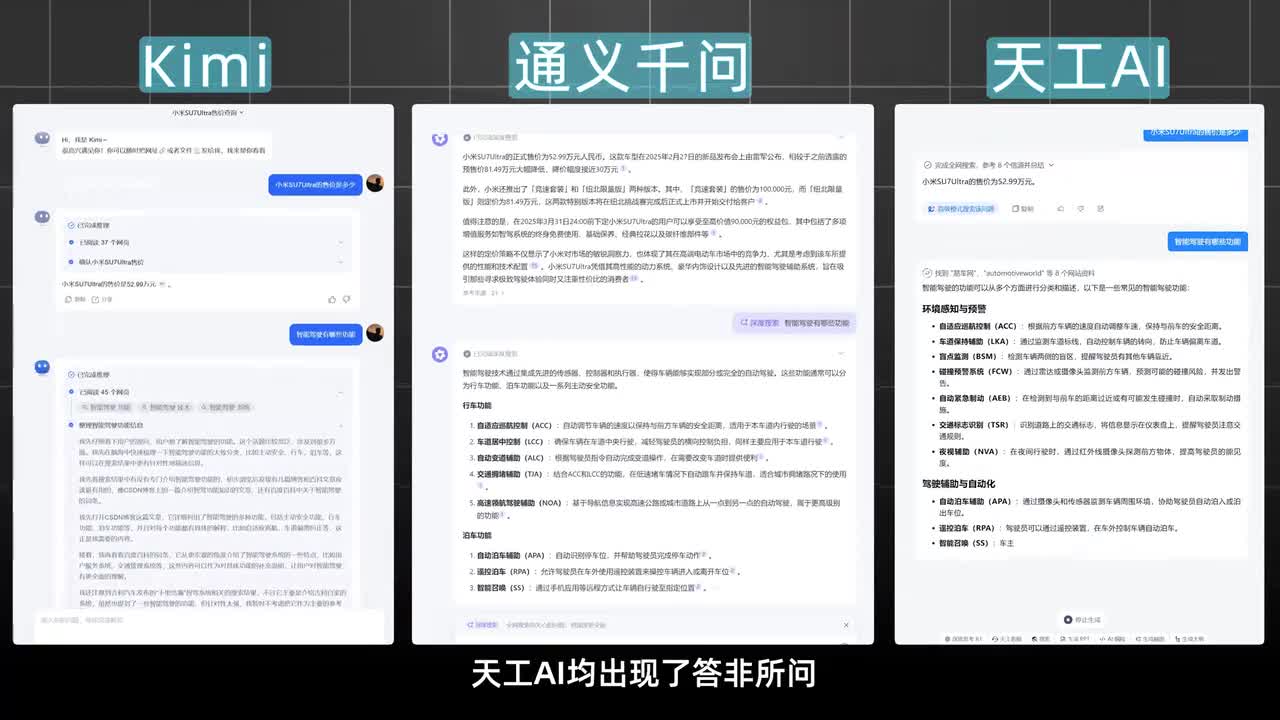
在第一轮基础测试中,我们测试了前后语境响应速度以及多元支持。比如连续提问小米速七四的售价是多少?智能驾驶有哪些功能,最高续航有多远等等。当问到第二个问题时,像kimi碰一千问天空a i均出现了答非所问。原本只是想了解当前车辆的相关信息,他们则开启了智能驾驶的功能介绍模式,稳定的前后语境理解这个指标可是关乎到ai助手能不能像我们人类一样理解问题的来龙去脉,给出准确有稳定的答案。

而其他七个a i模型都能稳定发挥。而在生成速度上,有一个选手真的让人又爱又恨的,因为他思考了二十三秒才给出了非常标准的答案,那就是deep sick了。它用时最久,所以在这一环节只能得到零分。豆包和腾讯元宝这些模型响应速度呢是相当的快,几乎可以说是做到了秒答,在反应速度环节上呢得到了最优,而部分模型呢就有点磨蹭了,等半天才给个答案,这可真让人着急啊。
接着咱们来看看多元知识。网上有很多家长呢都是用a i工具来辅导小孩来学小语种的那懂得多种语言的ai助手可就大受欢迎了。咱们这次评测呢也考察了模型,问能不能流畅处理多语言混合的问题。结果发现像文心妍和讯飞星火这些模型就有点力不从心了。

他们只懂中英文,这怎么能行呢?而其他模型多语言的支持那是相当的强,多种语言切换自如。所以在第一轮基础信息的评分中,豆包腾讯元宝获得了s级。前后语义理解以及响应时间都非常优秀。b c如果能提升一些响应速度的话,那就不必垫底了。
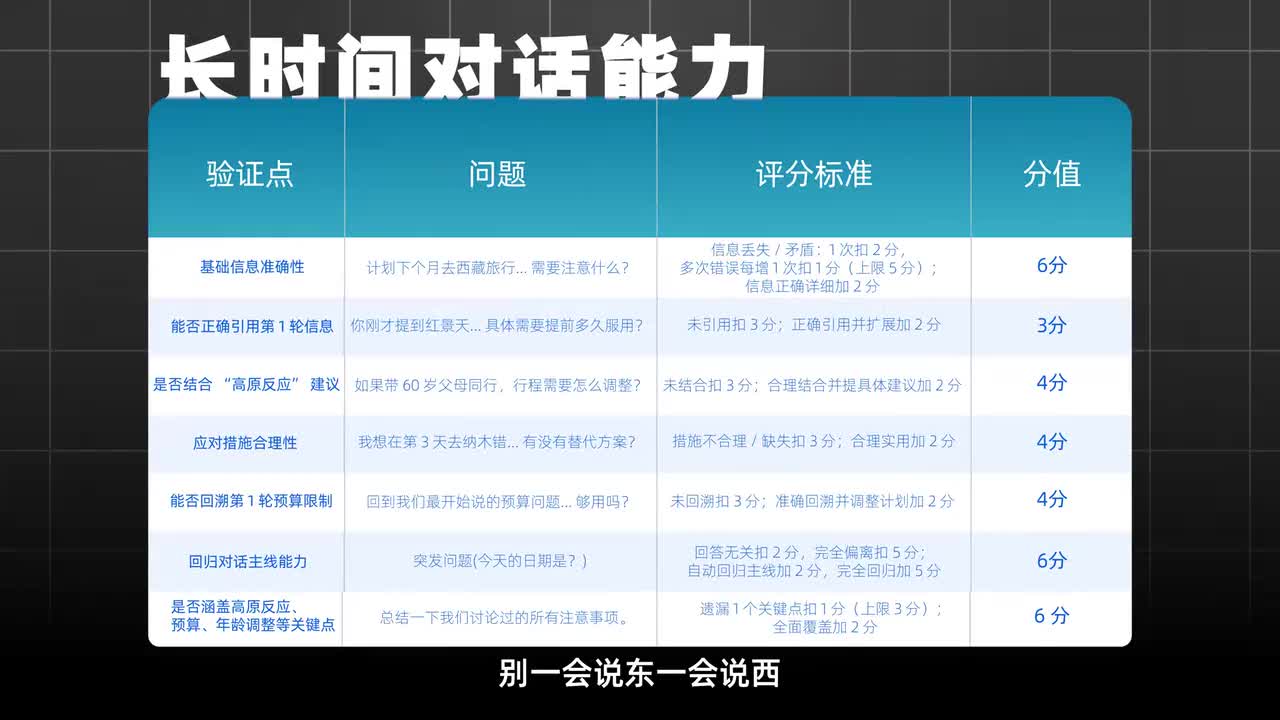
简单了解了基本情况后,咱们来上上强度,让模型带我规划一次西藏旅行,从路线到住宿,从美食到文化,啥都得要,就看模型长时间对话能力能不能hold住全场。别一会儿说东一会儿说西,把咱都给整蒙了。大模型发展到现在啊,大多数模型都是有问有答的。但有的模型在西藏旅行的规划中聊到第八轮已经开始推荐过如何组装一部电脑,本地部署模型等等。

呃,甚至还有详细的配置告诉我要花多少钱。甚至还有更离谱的,他开始推荐我去西安兵马俑、桂林山水游山玩水。这根本就是答非所问了,而在长时间测试的过程中,咱们可是严格扣分的。像文心妍和mini max在基础信息评分上正常发挥,拿到了a这次他们的对话中表现稳定,信息关联性较强,预算计算也准确,基本上没有什么扣分的。

天空a i kimi紧随其后,虽然在行程上面没有明细项,但给出的注意事项也足够完善,这四个大模型都可以拿到s不过啊也有的模型在对话中出现了不合理的情况,比如在推荐景点的时候,当我要求低海拔的时候,他们连续两轮都推荐了海拔差不多的地方,甚至还推荐了海拔更高的地方,这实在是有点说不过去了吧。文,熙妍x一在对话中不仅信息关联度更强,而且预算计算的非常准确,推荐的旅行路线也非常合理,再加上附带温馨提示和更加人性化的备选方案,看起来这个模型在长时间对话方面可是有着独特优势的。以上长对话中,kimi文馨妍x一mini max和天空a i都以优秀的逻辑能力赢得了s级。天空a i获得了三十二分,现在已经排到了第三名。

大模型一开始出现,相信很多人都用它来预测未来。当然了,这些回答只能功于娱乐,但究竟能玩出多少新花样?我们接着上片段,看看各家模型是怎样根据我的个人信息生成有趣内容的,能不能像个魔术师一样把咱们给惊喜到?我们给模型出了个难题,让ai根据用户特征来生成创意内容。首先呢我伪装成了一个养猫的科幻插画师,让a i工具用星空猫尾巴探索这三个元素,给我起一个微信昵称并且设计个签名。但只有三个模型能同时把这些元素融进签名,其他的完全就是关键词硬凑。

像豆包mini max和星火在个性化互动评分上都可以拿到s级,他们生成的昵称和签名既有创意又契合用户特征。文心也仅落后一分,获得十九分。而质朴青年和天空a i强堆关键词,并且回答的内容也过于单一了,只能拿到c了解了模型的基本信息和对话能力后,咱们让模型各自玩起了角色扮演。客服、心理咨询师、健身教练,各家模型每个角色都能拿捏得恰到好处,切换自如,像deep sik在角色扮演中的评分可是达到了s级。

他在不同角色间的表现都非常出色,来上片段看看模型是如何在不同角色间游刃有余的,居然秒变专业演员,把每一个角色都能演得活灵活现。当我打通售后电话时,最怕的就是遇到流水账式的问答,我都来找客服了,当然是希望第一时间寻求解决问题,如果你第一时间解决不了,安慰安慰我的情绪总是可以的吧。唯独天宫也不走寻常路,一开始就踢皮球,让我去找别的客服解决问题。另外呢,kimi也开启了躲迷藏的模式,让我挨个地方查找。
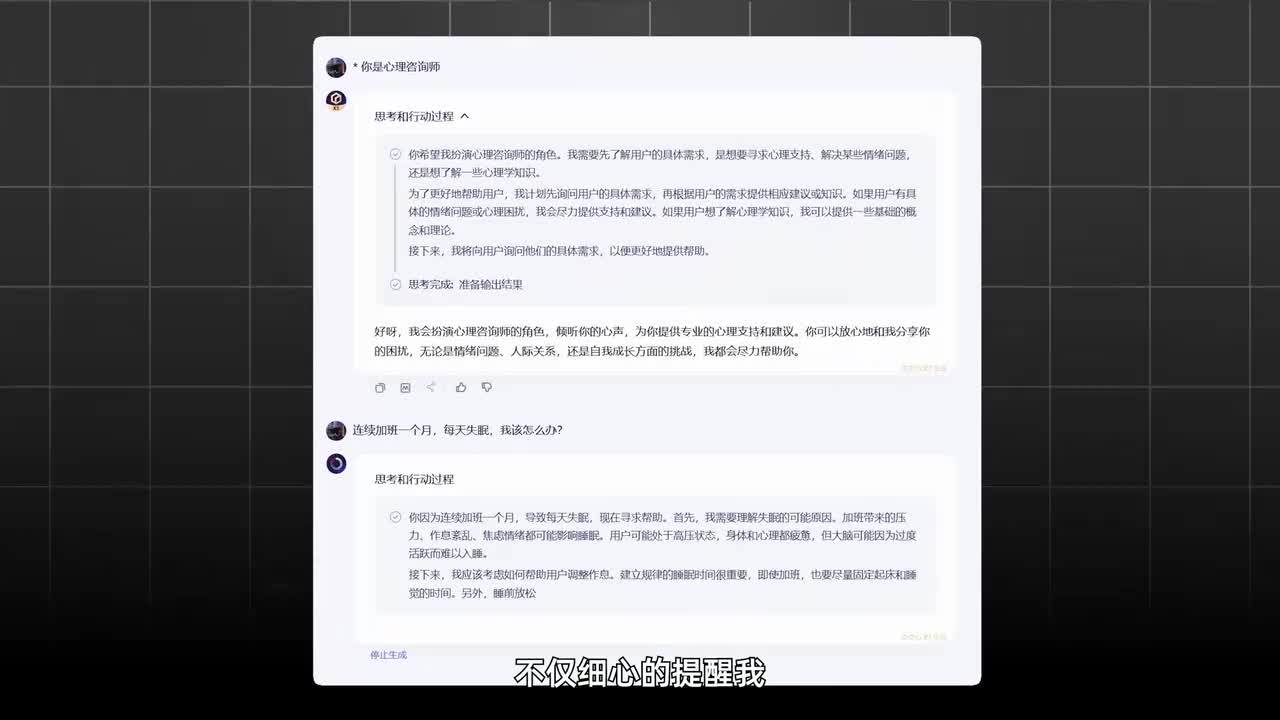
所以天空a和kimi首轮角色大摸底就只得到三分,扮演客服垫底。第二轮的心理咨询中令我最感到意外的是x一模型。不仅细心的提醒我短期和长期的两种方案,还像一个有温度的工具一样,特别提醒了我一些注意事项。其他大模型这一环节的表现几乎差不多。
而在健身教练的扮演上,豆包、文心一言、讯飞、星火mini max以及deep sak等大多数模型都可以满足我居家减脂计划的定制。但是你看,志不轻言的回答就很死板了。他提供的信息在任何一款健身app上都可以轻松获取,而且他也没有提供更有效的激励监督。另外呢我也要批评一下天空a我明明已经告诉过他,我膝盖受过伤了,需要调整动作,他还是给我提供了很多抬腿的姿势。

经过了上面这么多轮测试之后,我们回过头来看看大模型的角色扮演获得了多少综合分。豆包、文昕言和mini max稳居前排,就看最后一轮测试谁能摘得桂冠了。另外当红的p c k也在这一环节拿到了s级。讲到这里呢,我又想批评一下天空a i了,他不仅没有做好前面的士兵调整,当再次调整为工作日计划时,竟然也没有联系前后思考,提供了一份让我自行判断膝盖是否能适应锻炼的计划。

因此呢天空a i在这轮只能垫底,获得了c级的评级。为了再次验证大模型的可用性啊,我们这次还搞了一些脑筋急转弯的测试。没想到模型不仅回答准确,还能提供不同的选项,并且再次回归到主题中,看来这些a i模型在应对突发问题时还是有不错表现的。腾讯元宝凭借着自身强大的搜索引擎,在这一举动闻胜一筹,回答迅速并且有详细的细分方案。
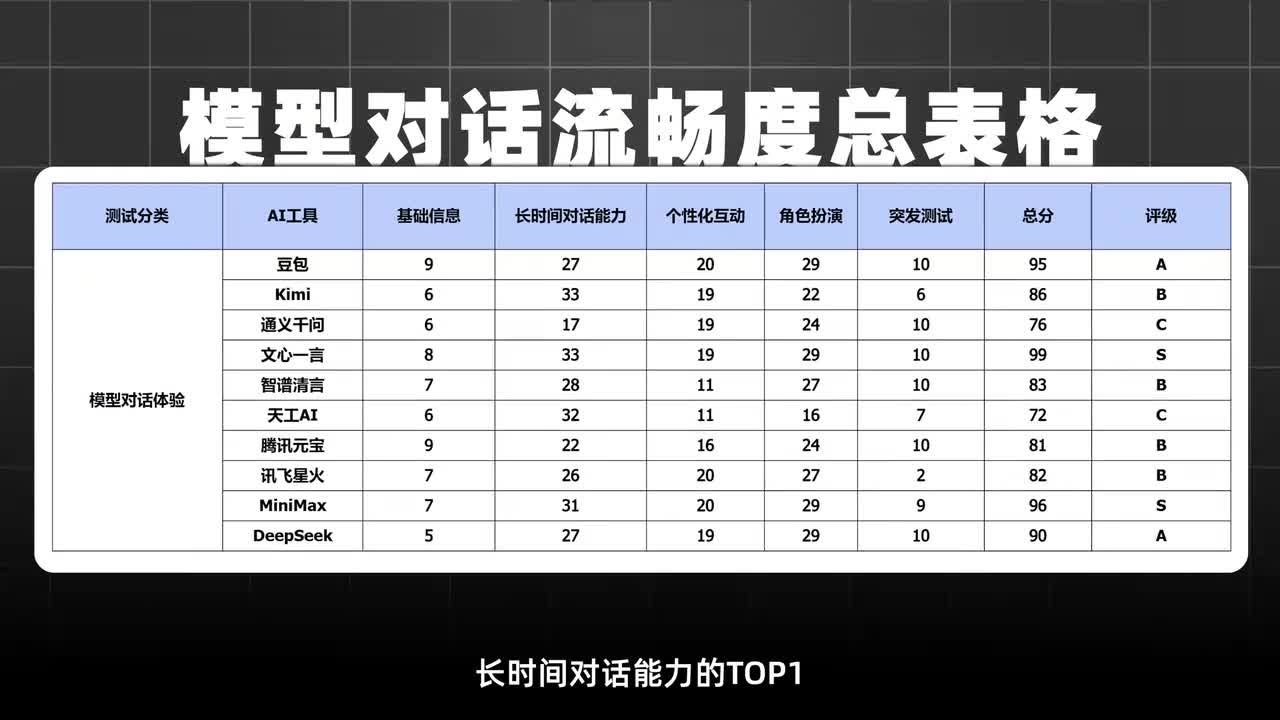
对于live sak,我只能说尽快扩充服务器吧。前面回答的好好的,关键时刻总是差那么点意思。实测下来长时间对话能力的top一是kimi和文心一言。角色扮演里最专业的是豆包mini max文心一言和deep thick。

但在个性化创意这块呢嗯有一个冷门选手竟然用星帮会这种蛇i d惊到了,我不知道大家喜欢不喜欢呢?完整评测数据我们已经整理成了表格,仅供参考。总体来说现在的a i模型就像一个偏科生,有的严谨逻辑适合工作,有的脑洞大开适合玩耿。所有的a i模型在长时间对话、个性化互动和角色扮演等领域都表现出了强大的能力。虽然还有改进的空间,比如deep sik响应时间,特定领域的创意生成等。

但我相信通过不断的进化和迭代,模型在对话能力方面肯定会有更大的提升。咱们也期待a i迭代可以带来更好的体验。好了,以上就是本期视频的全部内容了,实用又好玩的评测,我们下一期继续,欢迎继续关注我们。




