
二零二三年是人工智能大爆发的一年,大语言模型的发展打破了许多人对于未来五至十年生活状态的一个想象。然而对于二零二四而言,大语言模型肯定就不是发展的终点了,而是一个开始,而承接他们的大概率是多模态模型了吧。对于头部公司而言,多模态大模型应该是他们现阶段发展的目标,基于特定图像或影像的分析,推导出能服务于当下人们需求的ai。

而对于我们普通消费者而言,要么就是使用他们给出来的配套服务,要么就是自己动手丰衣足食。找一些小模型微调,然后就成了自家专属的猫猫小助手了。咱们来看看最近有哪些小模型可以拿来用的吧。
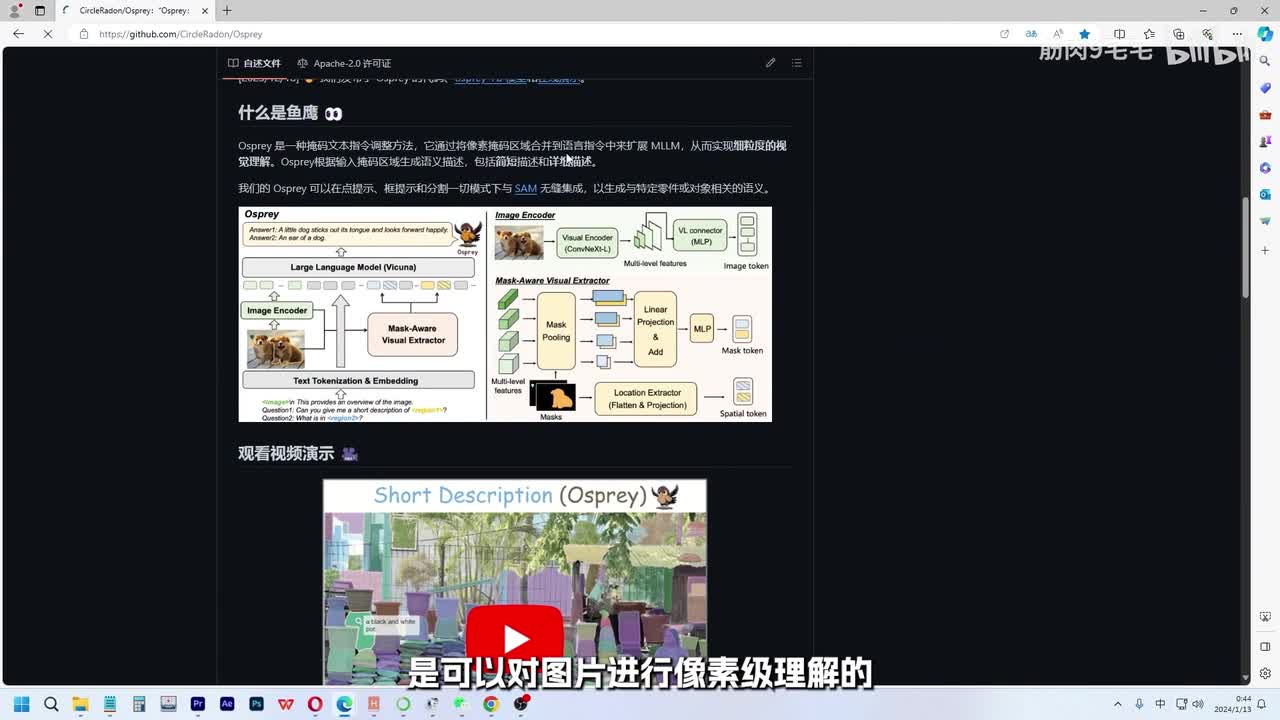
经过一番努力的网上冲浪后,搜索到一个看起来还不错的多模态模型aspray。这个模型是可以对图片进行像素级理解的多模态模型,看起来不错。这里还有展示网页,咱们打开看看。
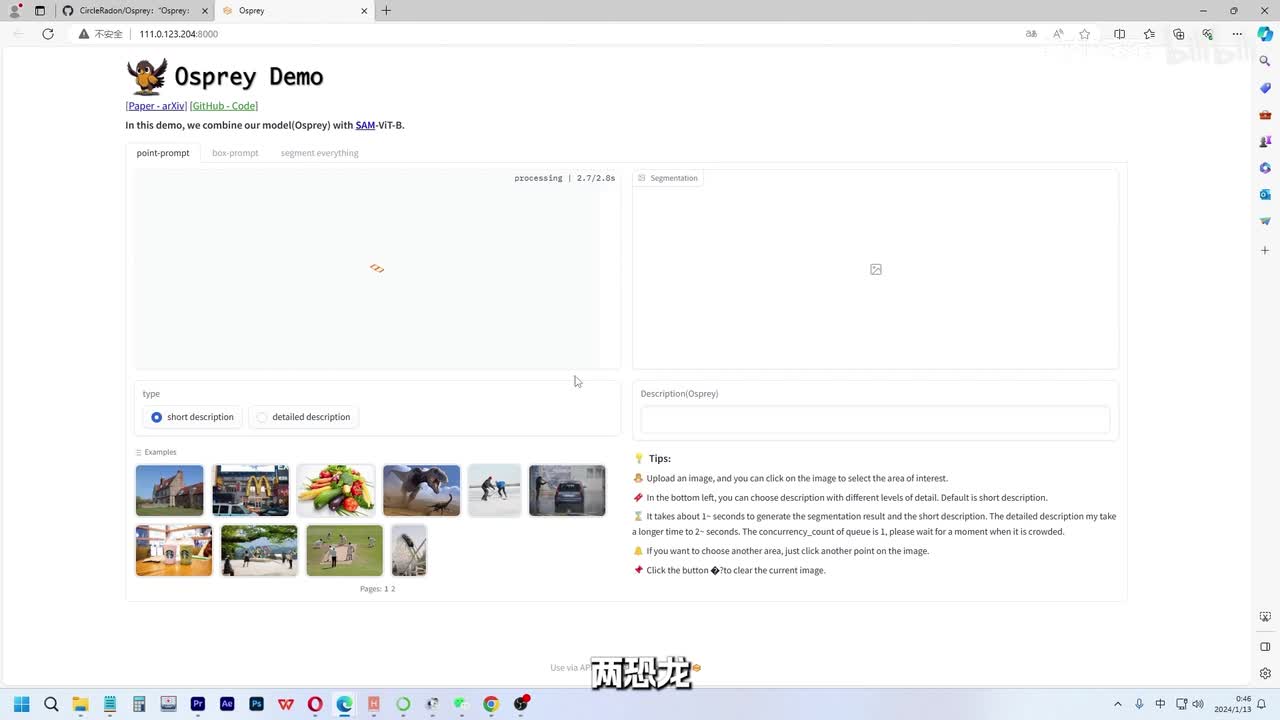
先输入默认的账号密码,片刻等待。咱们先看看他们展示的默认的样例。就他了两恐龙还带点模糊,我点了恐龙头的位置,稍作等待看看结果,结果还挺好啊,再试试小恐龙。
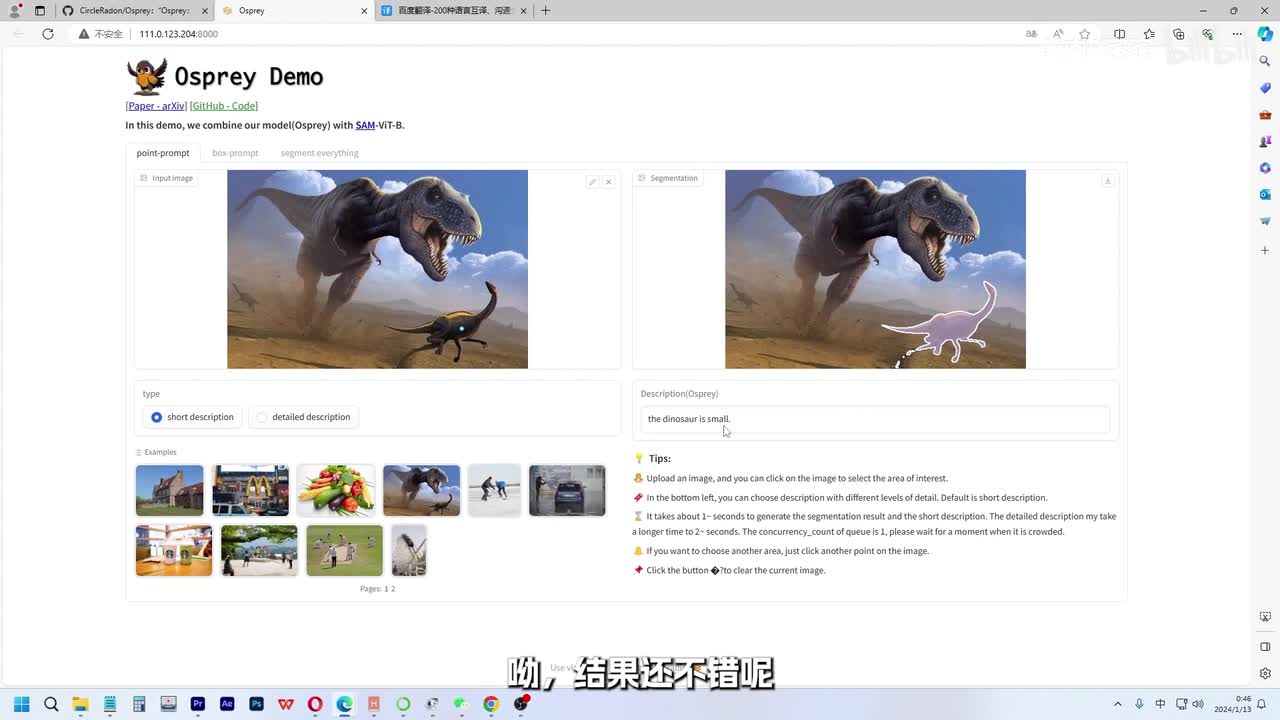
稍等片刻儿。哟结果还不错呢。咱们再来看看生成较长语句的结果吧。
再次等待片刻,这结果看来他对图片整体的描述就相对不太准确了。不过他还是很厉害的,所以兄弟们把代码嘎嘎克隆下来跑起来。可惜经过了几天对豆客的学习操作后,环境搭好了,可是不知道怎么运行起来,最后豆克的环境也没保存成功,酷酷不过还好有位大佬释放出了懒人包,然后下载运行,于是乎蹬蹬蹬蹬,可惜还是没跑起来。
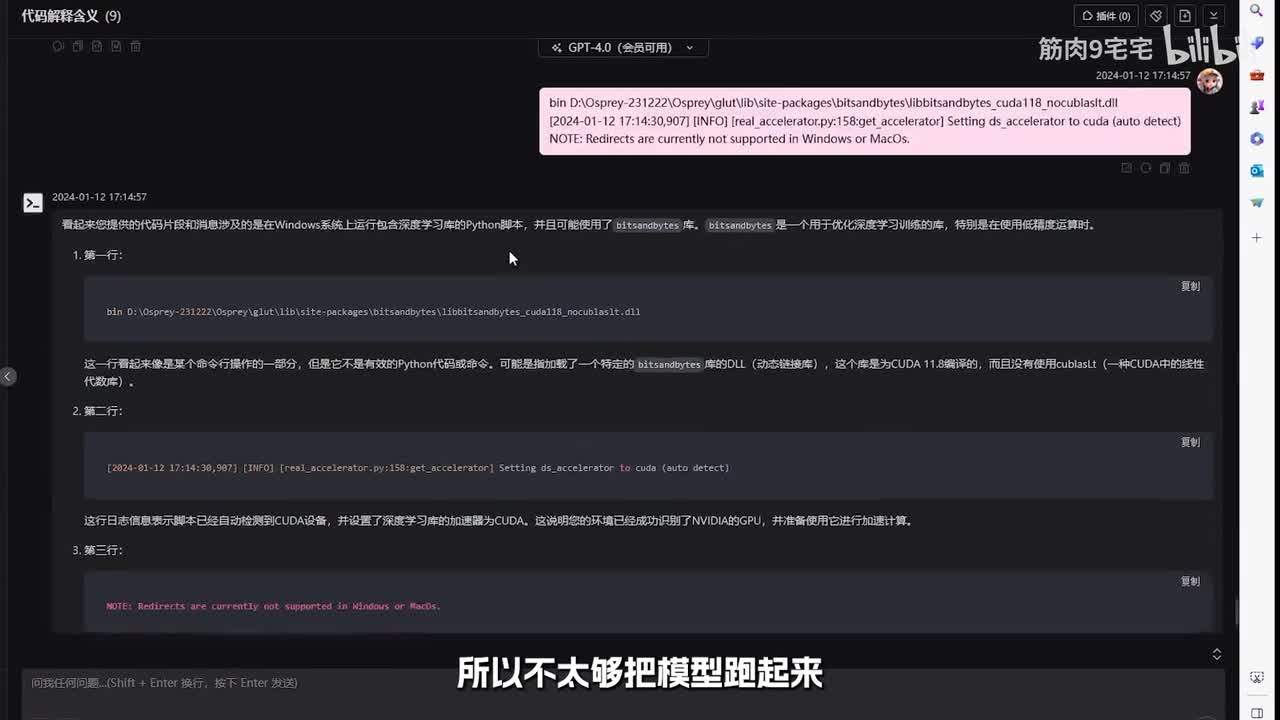
为什么会这样呢?可能因为电脑环境搭载了两个显卡,环境默认可能仅使用了一个显存,所以不太够。把模型跑起来,然后让人工智能帮我看看,并加了两行代码,蹬蹬蹬蹬跑起来了。咱们一起来看看这个恶魔态语言模型的表现吧。
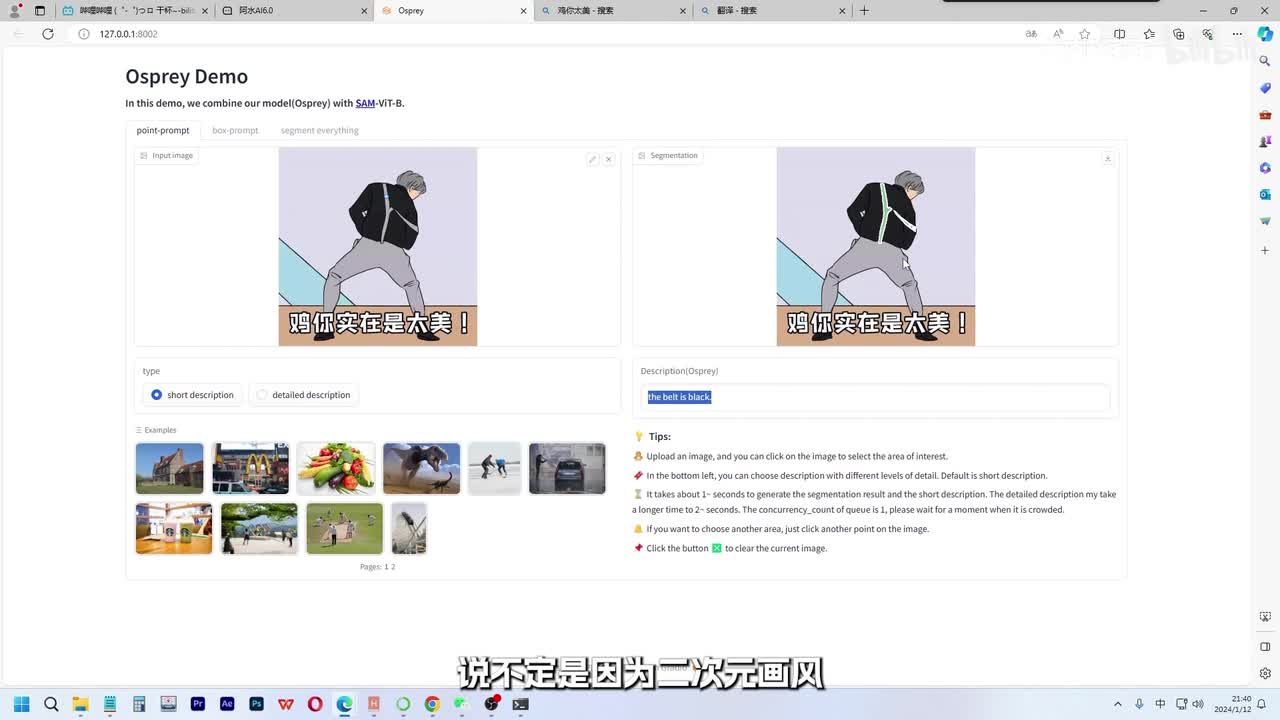
先试试哥哥的图像,看看能不能识别它的标志性的背带。这结果只能说毫无关系了,说不定是因为二次元画风的。导致的识别不准确呢,换一张哥哥的靓照再试试,这结果有点差强人意了,哥们儿。

总的来说,现在多模态还在刚开始发展的阶段,之前灭獭开源的山姆模型还有拉玛模型,都极大的推动了开源模型与开源社区的发展。相比另一家真的感觉灭獭做的挺棒的。相信不久之后还会在开源多模态模型让大佬们魔改的加油灭獭。

而咱们的大厂们都在卷动画领域的模型,比如阿里可能是基于control尼特制作的拥有良好一致性的动画魔改模型,还有字节跳动应该是基于图像分割出基于人类动态部分的画面,然后再进行重绘的模型,这两动画模型看起来都挺不错的,可能都在为数字人主播这个方向铺路。总之,现在还很难预知未来是个什么样的生活,但是关注人工智能赛道总没错啊。





