今天咱们来介绍chat g p t里面的code interpreter,我们来看看它是什么啊。这个首先呢它是一个我最近看到给我提供的新功能,因为现在啊它是在一个灰度当中,说白了啊就是先给一部分用户来试用啊,如果大家反响不错,并且也做了一定的改进,它就再继续的把这东西推而广之给更多的用户。那么我前两天看到哎,这个出现了叫做code interpreter or我这个我这个选单里面啊现在好几个了啊,我我看着很开心啊,还是阿尔法状态,就是一个最初的测试版本。那么我当时一看它啊code interpreter,我当时想到的是什么呢?我就犯了一个错误,我顾名思义或者叫做文生意啊,就是想到哎这东西呢既然是这么写呢,一定是什么呢?它就是代码的解释啊,代码解释我用得着你吗?对吧?因为什么呢?拆g p t就能干。啊,而且干的还不错。我这个代码让他给我看,这里都每一句是做什么用的。

他一般来讲给我们解释的也是非常靠谱,所以我就没当回事儿啊,实际上大错代码为什么?因为这个东西绝不是你放一段代码,它给你解释啊,然后给你返回这个解释结果,绝对不是啊。他是干什么的呢?它是这样啊,它是代码的执行器,就是它可以执行代码。以前呢你用chat g p t或者g b t四给你写了代码之后,哎,然后这个代码怎么用呢?你得把它拷贝到你的环境当中,对吧?现在不需要了啊,它甚至允许你上传文件作为输入。大家都知道我们做很多的这个编程啊,都需要有输入的文件,输入的数据,对吧?它允许你上传文件作为输入,然后他就在自己的环境当中给你做这个代码的处理,不需要你把它拷贝到什么video。有啊朱碧ter notebook呀,或者是在线的运行环境当中去运行代码看结果了,直接都在这做了一站式的包圆完成啊。而且它不仅可以给你直接显示结果,包括结果的绘图数字这些东西,甚至它可以给你提供一个结果的下载链接。
我输入一个文件,处理完了形成一个新的文件,这个文件它可以在这给我个链接,我一点就可以把它下载。哎呀,这个东西我当我明白是怎么回事的时候啊,我这个大惊失色啊。其实就是这个这个你你你单单的时候,这边儿上给你解释啊,我连看都没看。哎,我觉得这就是一种无知吧。这个来耽误我好几天来使用啊。不过没关系,我把这个话告诉了你,哎,你就不会再因为这种错误的判断耽误时间了啊。

那么下面我给你演示一下,有了这样的一个功能,那你可以做什么啊?我们来看看,首先我们先找一个数据集,这数据。急呢我就不找那种太复杂的,我找了一个简单的就是一个这个结构化的表格数据。这是我上课的时候用的啊,叫做loan star c s v。在之前的文章当中我也介绍过它,不过那是好几年前的事儿了啊,我估计你可能忘了啊。然后来看一下,就是这里面呢每一行是一个记录,代表着一笔贷款。然后呢,这里面的每一列啊代表着相关的特征。
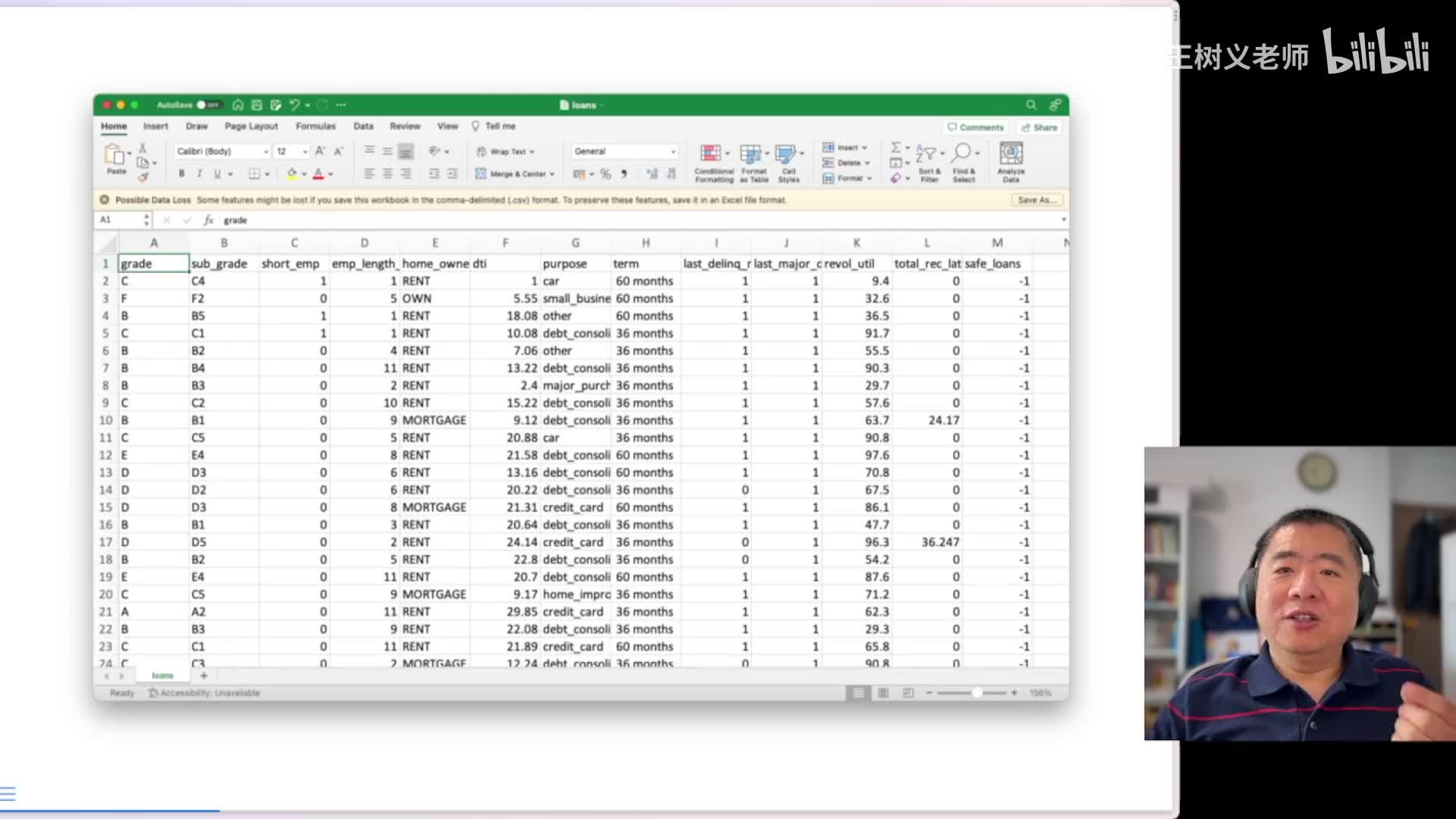
你好,比如说从第一列是贷款的等级啊,然后呢这里还有他是不是啊拥有自己的房屋,你是房子是你自己的,你租的还是抵押贷款啊。然后最后一列非常重要啊,就是说这是一些历史数据嘛,就是这笔贷款最后到底是不是成功的贷款,也就是它是不是安全。对于这个贷款人来说,那么这里头啊负一代表哎,这笔贷款,然后然后这个收不回来了啊,这个就是一个。呃,不安全的或者叫不良的贷款。哎,如果是一,那就是最后哎连本带息都收回来。非常好啊,是这样的一个数据集。
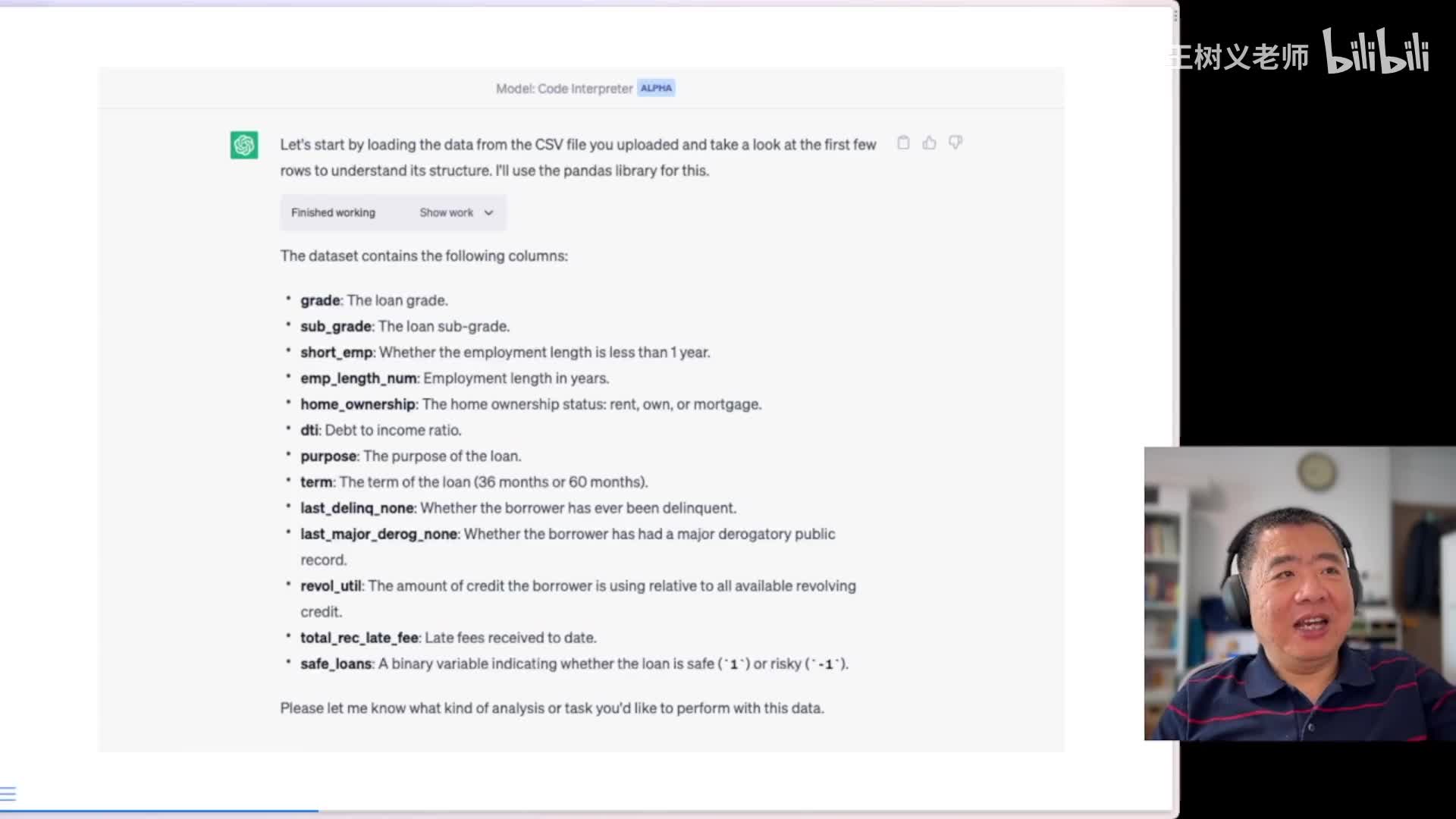
那下面我们就来把这个数据集放到code interpreter当中,看它的效果。呃,首先是上传,上传呢在这个界面当中你会看到一个很不起眼的啊,我这里给你加了一个红框,哎,让它醒目一点。实际上特别呃细小的一个上传的这样的一个结果,你得按一下它这个可以上传文件了,上传之后它会进行分析,这是他给我分析的结果。对于每一列他都给我讲这一列是干什么的啊,讲的是一清二楚。于是呢我就点击这里面有一个show work,就是你看看他究竟在做什么。哎,我一点我发现啊他是怎么做到的呢?它的代码运行是这个样子,他这里头实际上是去读入相关的数据,并且它会看这个结果。
因为他的这个结果,所以他大概能够判断。出这里面都有什么,它是通过这样的一些结果,然后把它反馈给你好了,有了这一步,下面我们开始输入提示语了。第一个我觉得你跟我拿英文对话啊很别扭,可能你给我拿中文说话,所以怎么办呢?我说请用中文翻译上面的内容,并且对于专业术语加以简单明了的解释啊,我们来看看他的反馈结果,这里面把所有列的解释不仅给你翻译成了中文啊,而且如果你对比就会发现,这里头可循环信贷利用率这些原先是没有具体解释的。而这里面会给你介绍它是一种什么样的信贷形式,然后反复借款和偿还都会给你列出来。哎,这就证明确实他是按照我们的要求,遇到专业术语,那就给我们加以解释。在最后他提出来,请告诉我,您希望用这些数据进行何种分析或任务。

这时候你就可以要求他,好比你给我做一个什么样的分析。比如说某一个变量啊,你给我画一个它的统计图啊,看一下它的分布,这些都可以。但是啊但是那就没劲了嘛,对吧?这个每一步都需要我人工参与,为什么还需要你这个a i呢?所以我的办法是这样的啊,你自己哎ai啊你能否根据目前的数据集思考它可以做哪些分析?请一步步思考,并且给我你有信心的答案。啊,这个我我这样要求完了以后,这是结果。他把可能分析的类型在这里给我们列出来,第一个可以做描述性的分析啊,这样就是一些基本的数量分布等等。第二步做相关性分析,把一些变量之间的关联进行相关的总结。
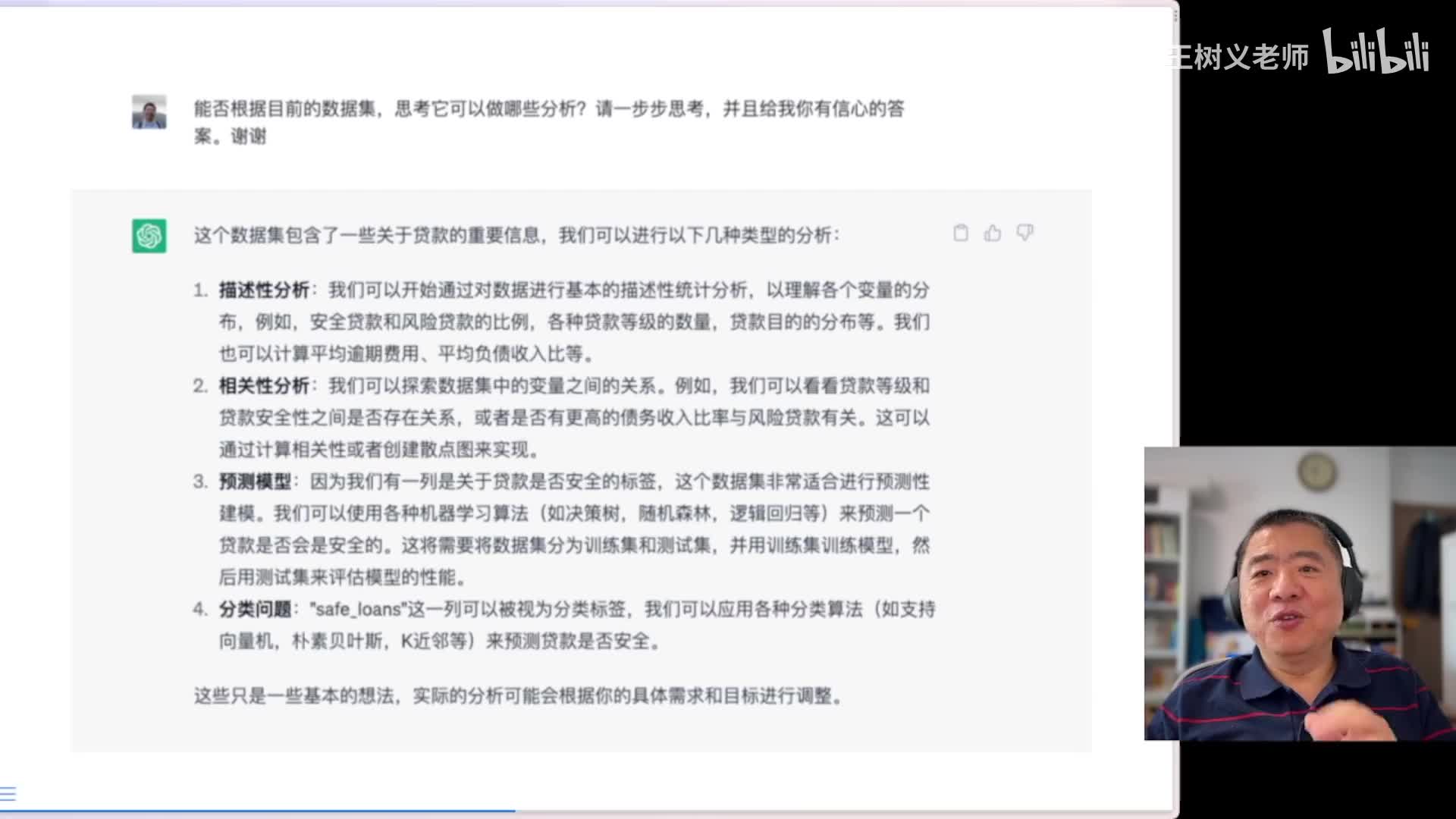
第三个他要构建预测模型,这里提到了决策树、随机森林、逻辑回归等等等等。而且还说啊要分为训练集和测试集,非常好啊非常好。这个有时候我需要都记不住这事。他们直接训练集验证集啊就上了啊,这个他知道哎用测试集来评估这个相关的性能,我觉得非常好。前三个都很好,第四个我觉得有点问题,因为他说的还是贷款是否安全的标签,而且他说用分类算法预测是否安全。这里他说的虽然和前面使用的不一样,比如说这里提到了支持向量机s v m啊,朴素贝叶斯。
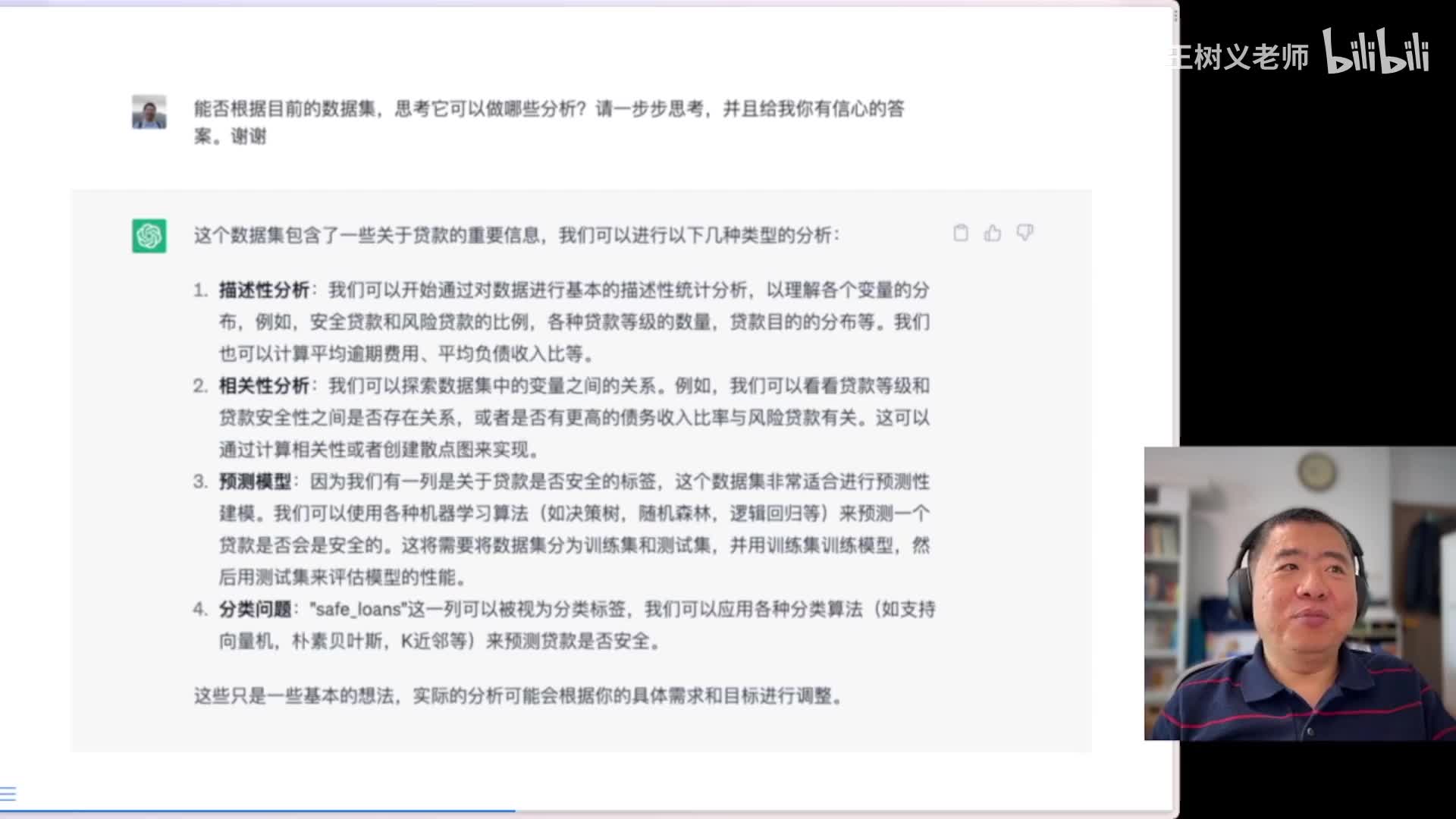
但是但是虽然你用的这些模型不一样,但你要做的事儿实际上是一样。所以我觉得在这里面四和三是重复了。但是咱们是拿a i当助手,又不是拿它当枪手,对吧?你你写的不对,我告诉你啊,第四就不用做了,咱们来把前三个做一做。这里为了展示的方便呢,我一次只让他做一个。下面是给你看看啊做的这个效果提示语。请先做第一步,就是描述性分析。
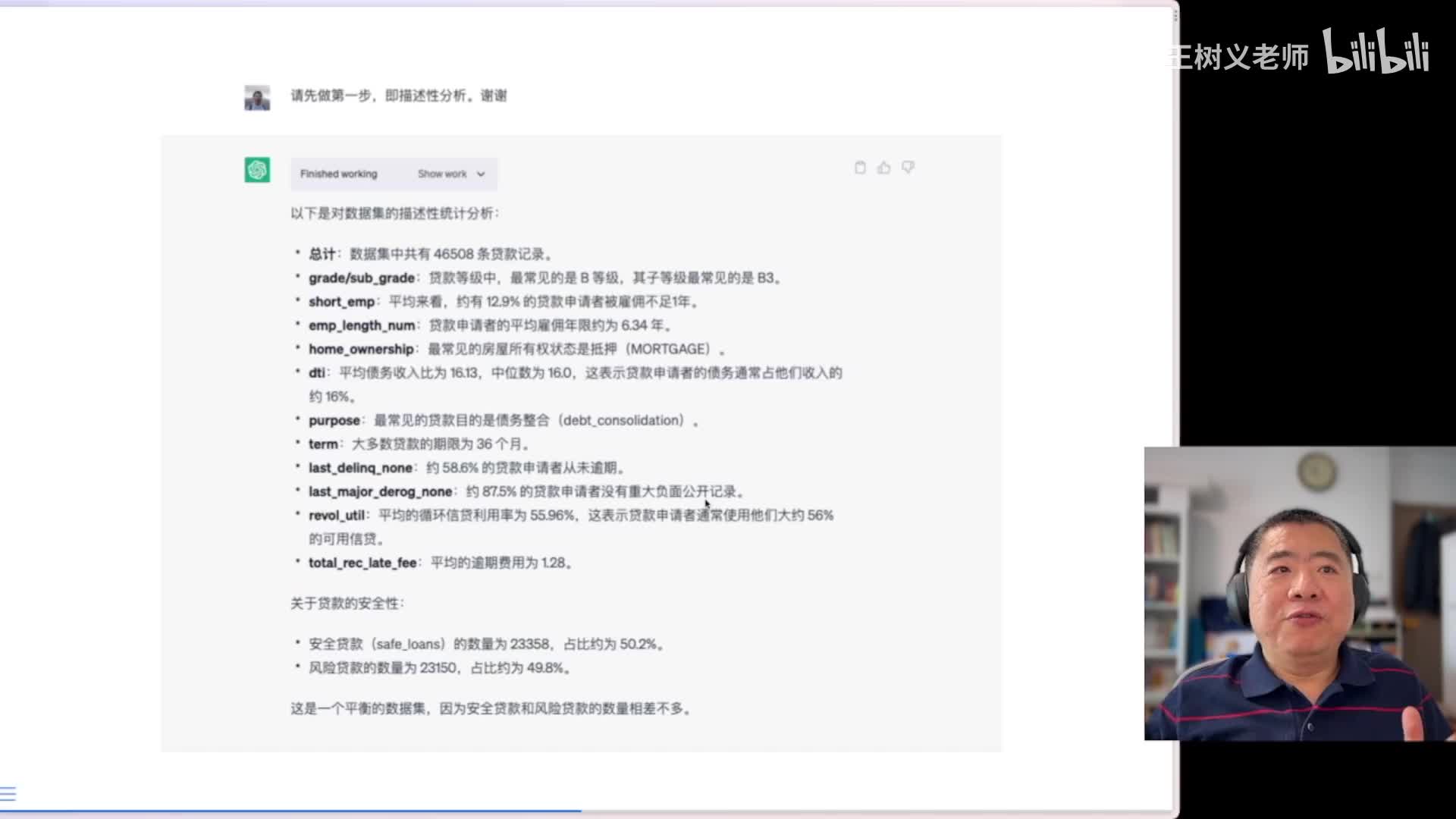
然后呢这是他给我的结果,非常快啊非常快。然后在这里。他告诉我多少条的记录是吧?最常见的等级贷款等级唉,平均来看有多少的贷款申请者被雇佣不足一年。然后这个平均雇佣年限啊,平均债务收入啊,贷款的期限的最多的数量,然后呢是哎有没有重大负面公开记录,所有这些东西咵一下就给你列出来。哎,如果你感兴趣的话,还可以在这里点击首work,你看看他究竟是怎么给你做出来的啊,这里咱就不展示了,因为这比较简单,我们来做第二步。第二步是我让你给我做相关性分析,你看看现在他做的结果啊,这里面short e m p和e m p lung number之间存在负相关性。
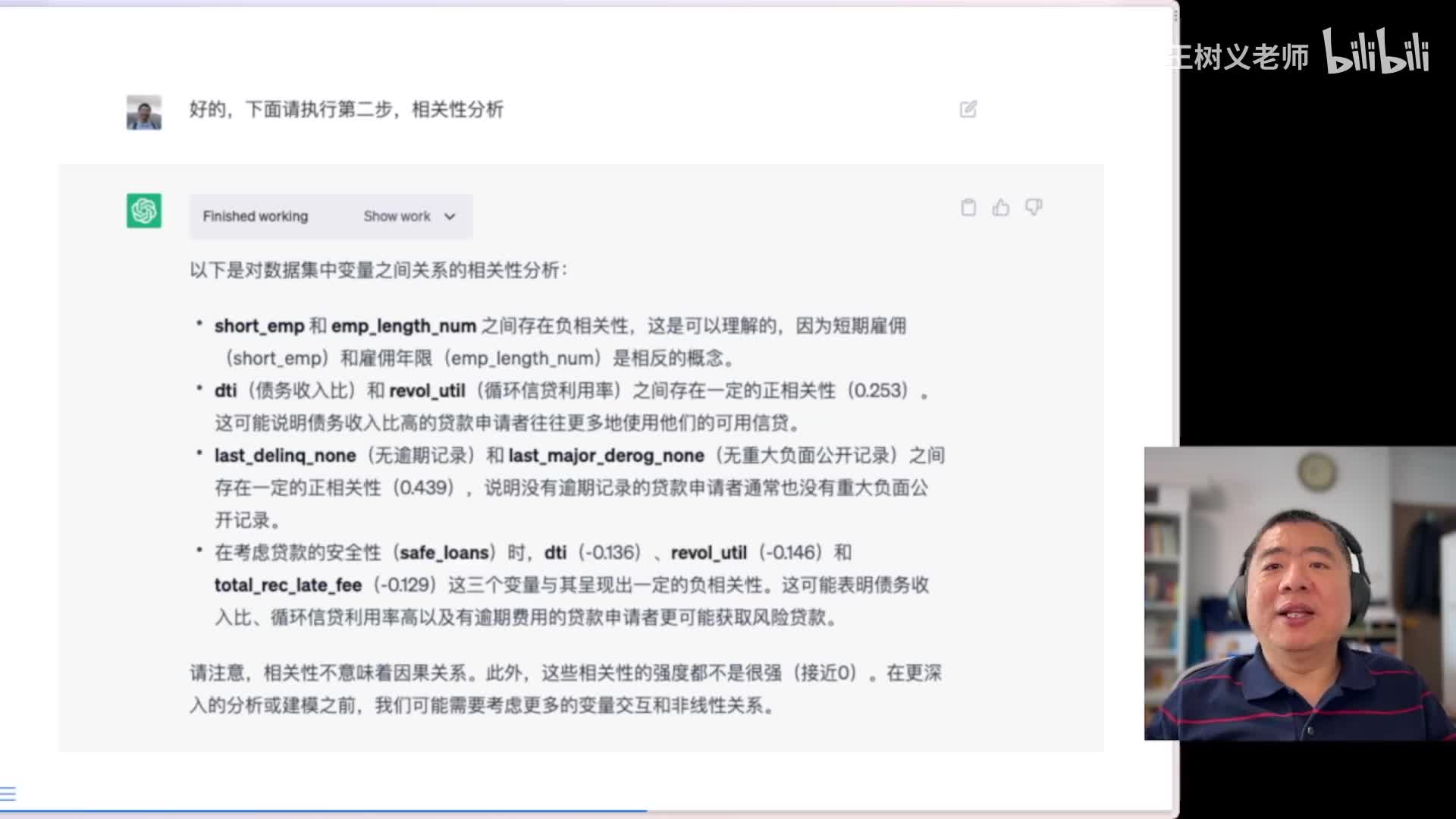
因为短期雇佣和雇佣年限是相反的,概念非常好。哎,d t i和revel until之间存在正相关。债债务收入高的贷款申请者往往会使用这种相当于循环的这个信贷啊,然后呢哎这我就不一一的给你。你念了啊,但是在这里说唉,safe loans和以下的这几个变量呈现一定的负相关性啊。就是说那些哎债务收入比比较高,然后呢这些人可能你贷款给他就不是很安全,对吧?但是这里尤其我喜欢最后这个相关性不意味着英国非常好非常好啊,这个这个我我希望我的学生也能理解这一点,这些相关性的强度都不是很强,因此我们要考虑更多的变量交互和非线性关非常棒啊,这个就属于知其然也要知其所以然,我觉得很好。那么他执行的代码我打开看了一看,实际上就是做了一个相关性的检验啊,如此而已。

但是通过这些他就可以给我们解读出很多有用、有趣、有价值的内容。那下一步提示与自然就是要能够做第三步了,预测模型这里呢为了让他能够做的更加谨慎,我说一步步思考与展示你有信心的结果。你看看啊哎这是他的。结果这里面首先他要做数据预处理,然后选择模型,第三步训练,第四步评估。很好啊。那么他在这里面选择模型是直接的,已经做出一个最终的选择,就是要做一个啊随机森林。
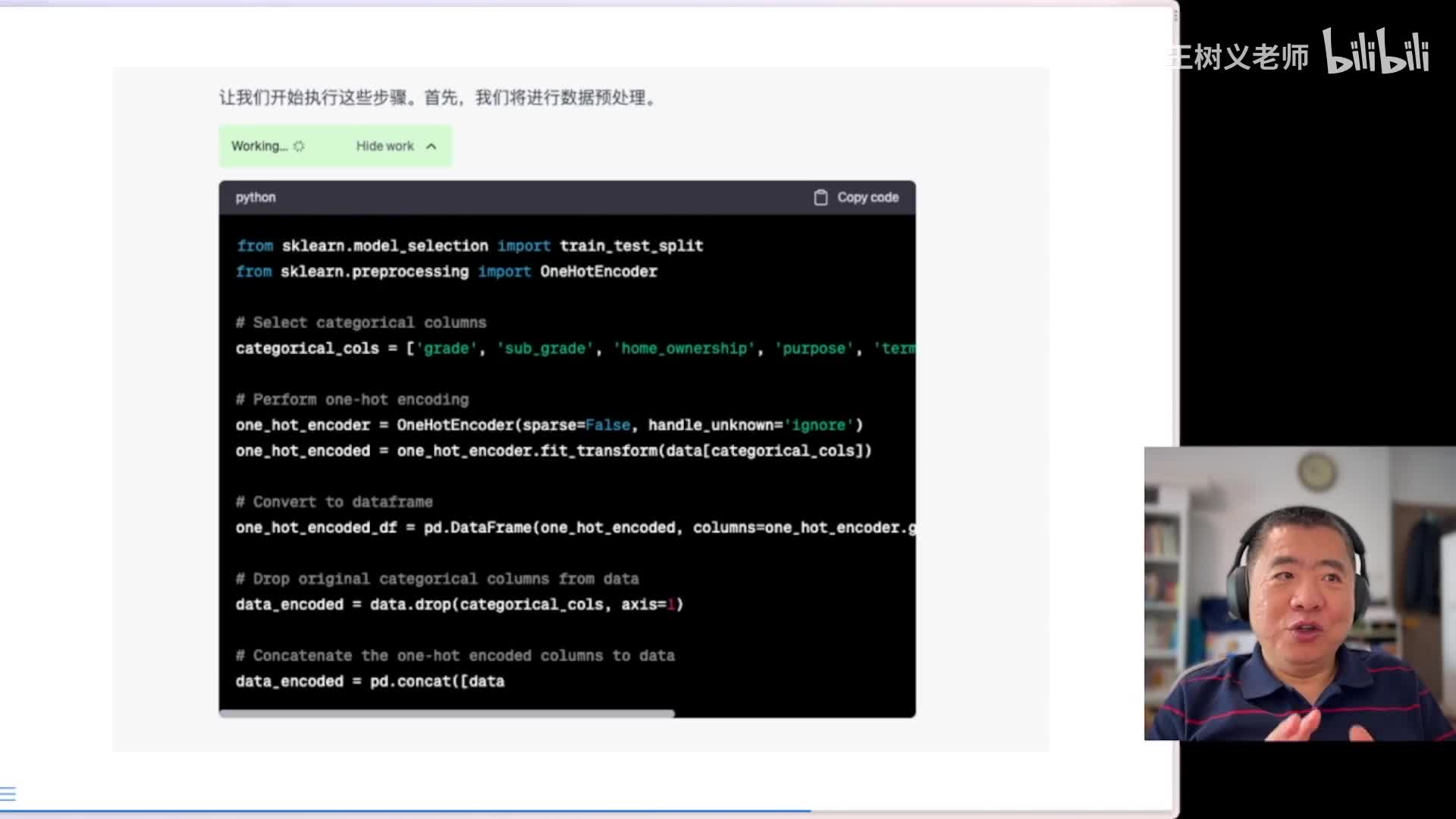
因为他说在各种问题上,我这里主要指的应该是这样的数据规模不是很大,几万条实在算不上大数据啊,而且是结构化的这样的表格数据确实随机森林一般表现出非常好的效果。然后呢他就开始陷入参考啊,其实这个不是一个思考的过程,是一个编程的过程。啊,在这里他在编制程序,它编制程序是这个样子,就是真的是在对数据集进行处理,包括读者编码,one hot coding等等等等啊啊我觉得他他做的严谨性啊,在我的这个机器学习课上啊,这是可以通过的啊。下面呢他告诉我们说这些步骤哎,预处理完成了,那么现在。他把所有的这个分类变量啊都已经做数字化的处理。那么训练集有多少?测试集有多少?这个我们可以看到基本上是按照四比一来划分的。

然后随机森林模型再下一步,这时候模型训练就都已经做完了。然后他说下一步我们要用测试集来评估性能,但是我不放心啊,我想看一看你的模型怎么训练的对吧?我让他给我看一下,其实就是哎random forest classifier,然后在这里来进行这个相关的训练处理,我觉得哎做的中规中矩也就没问题了。这是结果,结果都在这里给我们展示了出来。测试集上的准确率百分之六十一点七,高不高?嗯,不高,确实不高,对吧?这个也就是说有接近百分之四十的可能性预测为错误。但是他这里解读了说比随机预测百分之五十要好一些,仍有提升空间。然后他告诉我几个可能的改进策略,我看了一下啊哎其他模型。

对吧呃模型的参数网格搜索特征工程啊很重要对吧?然后更多的数据这个这个就算了,因为我们现在就是这点数据啊,哎然后后面还有这这句话,我觉得写的非常好,不仅仅提高准确率,还要考虑解释性来训练和预测的时间。哎呀,我觉得这个回答的我我我继续学习这门课的教师的角度来看啊,这个是是学生对我我能达成这样啊,我该多开心的对吧?那么下面我这个提示语你猜是什么?哎,是不是说我选定其中某一种方式,然后让他来照着这个方向来做?答案是不是这样啊?既然你给我画了道,那我才不走的对吧?我让你来做,我说你能否实施改进策略啊,并且在同样的测试集上进行测试。你看这句话是干什么?这句话是既然你有提议好,就由你来执行。那么他给我直接的来说他要做什么。首先他使用梯度提升树模型啊。然后简单的超参数调优啊,把这个n estimators这个参数以三种不同取值来进行测试。

同时他告诉我们,如果是实际操作,我们应该考虑更复杂的策略,例如网格搜索对吧?但是呢说那花更多计算资源,说白了就是他不愿意花很多钱帮我干这事儿啊,这个计算资源就是钱啊,这这话没说错啊,所以他就开始来干了。这次他把原来的百分之六十一点七的准确率,就是原始的随机森林模型,现在已经提升到了百分之六十四点九。不仅如此,还有给我提示啊,哎现在有一些改进,但是还有其他可能的改进策略啊。另外就是要考虑相关的一些其他指标,特别是类别不平衡的情况下,要是只看准确率是不对的。我觉得说的非常好非常好好,那么这个演示给你做完了,我给你谈谈我的感受啊,我的感受是这样经验。真是惊艳的。

因为以前啊这个中间的搬运代码出了问题,再去找他,这这太麻烦了,对吧?咱是懒人就不乐意干这些麻烦事儿,但是现在这些都不用,你就跟他对话,并且给他布置任务,甚至你让他自己思考自己该做什么任务啊,然后他给你干,并且哎分析得当,执行流畅,这这是我给他的评语啊,我觉得这个非常好。那么我推想一下这意味着什么?有了这样的功能,现在很多小伙伴是什么呢?拿到数据对吧?这个数据显然是因为他要研究某一个题目他搜集来的,拿到数据之后他不知道如何分析。哎,这也是前几年你会看到各个学科的人都跑去学拍方啊的原因。为什么?因为他们觉得学会了python或者学会了二啊,这样就可以让他能够对手头那个数据能够进行合理的分析,并且得出正确的结果。以前呢是坐拥一座金山,但是呢他没。反而去把它用起来,哎,他们希望通过这种方式用起来。

但是要在从前你要想把它用起来,你可能得学一门课,至少你也得买一本相关的书来看,对吧?但是现在你可以把这东西扔给chat interpreter,就是code interpreter。它的这样的一个功能,直接把你的数据扔给它它的分析结果。我搂着说啊,超过入门水平,就是你自己去学到入门ter你不一定能做到这个程度。就是我给这个东西的评价,我想给它证个明啊。这个东西我觉得与其强调它的作用方式,就是我能在这儿行代码,所所以我叫code interpreter。我觉得你更好的一个方式是我强调你能做什么,你的能力能力在哪,我认为它应该叫做data analyzer啊,当然了,你说你这起的就非常的偏颇,对吧?它除了对于你这种数据的分析啊,比如说这个描述统计、统计推断、构建模型这些东西还。

干别的呢?没错没错。但是我觉得要是想把一个功能哎让大家更快的熟知,避免很多人拿到这个功能他都不想去用。啊,例如我开始的这个错误的这个阶段啊,那么我觉得强调一下它的特色能力,其实可能更有这样的传播的力度。啊,这是我给open a i官方的一个小建议啊,不知道他们能不能看见。




