
今天给大家介绍一款小白也能轻松上手的ai绘图神器。那它不像stupid fishing一样需要一台很高配置的电脑啊,也不像没有整理一样需要付费和翻墙。这是一款不翻墙就能免费使用,并且生成高质量图片的ai绘图工具,那就是leo nado点a i为了帮助更多人接触学习a i那最近两周呢我也利用下班时间反复录制并浓缩剪辑成了一份十分钟的leonardo保姆级的新手教程啊,这里免费分享给大家。即使你是一个完全零基础的小白,也可以轻松上手。那欢迎大家一键三连长按,点赞、转发、投币,让这个教程帮助更多对ai绘画有兴趣的人。
首次使用lynda的时候呢,我们要去他们的官网申请这个内测啊,在这里输入你自己的邮箱就可以了。这个内测等待的时间差不多在一周左右,我自己试了好多次,基本上一周都能收到那个邀请码。在收到邀请码之后呢,我们直接点击邮件里面的链接,或者说你点击这个右上角的launch a就可以进到莱昂纳德的后台。在后台里面呢我们可以看到它左边会分为两个区域,这上面是一个feed,下面才是一些真正使用的工具。在community feed里面我们可以看到leona的其他用户生成的一些图片。
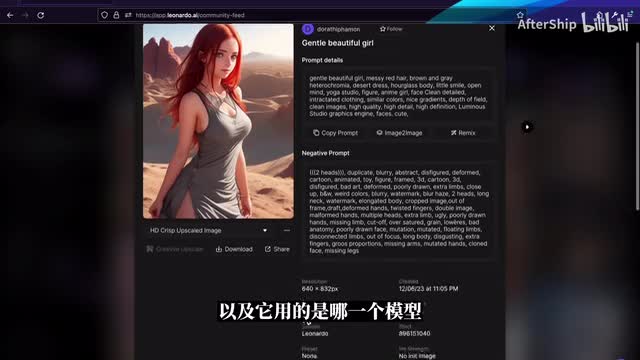
如果你没什么特别的想法的话,同样的feed是一个不错的开始。你可以从任何一个图片的呃详情页去看到它是用什么样的提示词去生成的。它的正向提示词以及反向提示词,以及它用的是哪一个模型。我们可以直接复制这个提示词,然后去尝试自己去生成一个对应的图片。接下来我们尝试着去生成一张图片,在这里我们就进入到那个图片生成工具的界面。
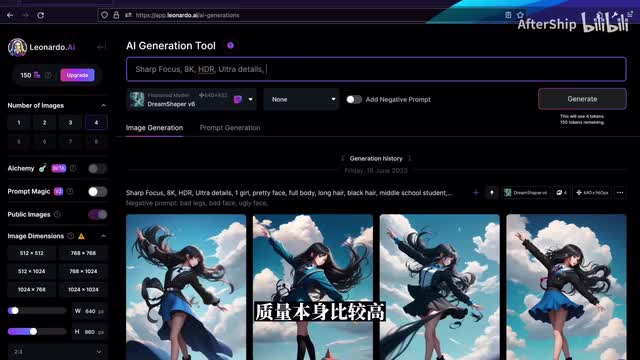
首先我们要去写一个print,通常我们在写一些pro的时候,首先要去写一些优化图片质量的一些关键词。那比方说我们这些是要focus,然后八k h d r or刷details,就通过这些词来让这个图片的质量本身比较高。接下来其实是去写这个图片的主体。比方说我们想要生成一个cap有一只猫的话那我就写one cap然后接下来是去写一些描述这个主体的一些形容词。比如说我们想要它是黑色的毛。
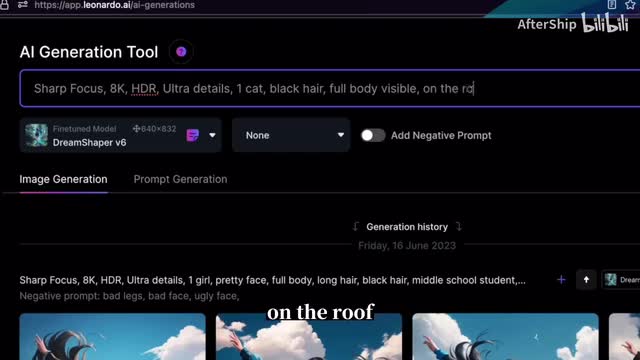
并且我们希望说这个图片它是可以看到整只猫的,我们叫full body visible。然后我们也可以描述一些这个猫的姿势,或者说它所处的环境。比如说他在屋顶上,你这on the room,比方说我们还可以再描述说背景的环境是什么样。比如说有天上有云。还有些鸟写好提示词之后,我们点击这个generate就可以生成图片了。
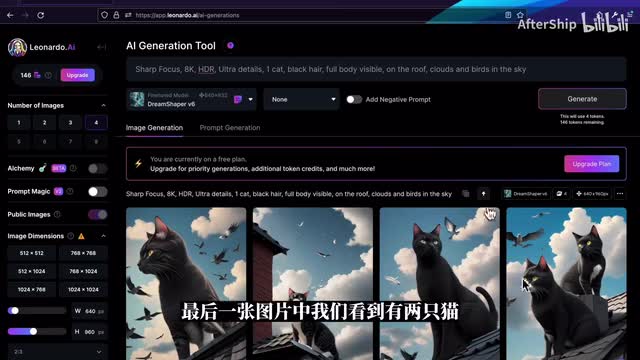
通常等待个十秒钟之后,你就会看到生成的图片。那比如说我们现在已经看到了图片生成了。但有时候图片当中可能有一些你不想要的元素啊,比方说呃最后一张图片中我们看到有两只猫,但其其实只想要一只。那虽然说我们写了one one cat,但有可能还是会出错。那这个时候我们就需要用到那个negative pron,就反向提示词。
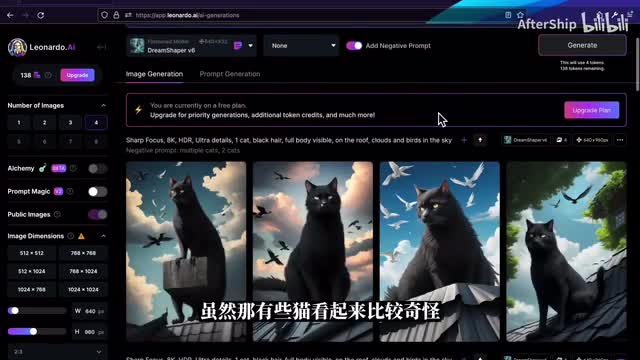
打开反向提示词之后呢,我们就写一些你不想要的元素。比如说我不想要多只猫就写multiple cat,那有时候两只也不太行吧,那我就写to cat和multiple cat。写完之后呢,我们就再点击generates重新生成一次。那新生成的你就看到它就都只有一只猫了。虽然那有些猫看起来比较奇怪,那有时候你可能没什么特别的想法,那我们可以尝试一下这个提示词生成工具,然后呢它提供了一个prompt generation,那在这个工具里面呢我们可以写一个你想要生成的主体,然后莱昂纳德会根据你的主体给出一些他觉得不错的一些提示词。

再比方说我们写one cap。然后在上面我们可以选择说你要生成多少个提示词来,点击这个按钮就可以生成。差不多也是等待十秒钟吧,你就可以看到有四个提示词生成。我们可以选择直接点击这个generate来生成图片。等个差不多十秒钟我们就可以看到生成好的图片了。
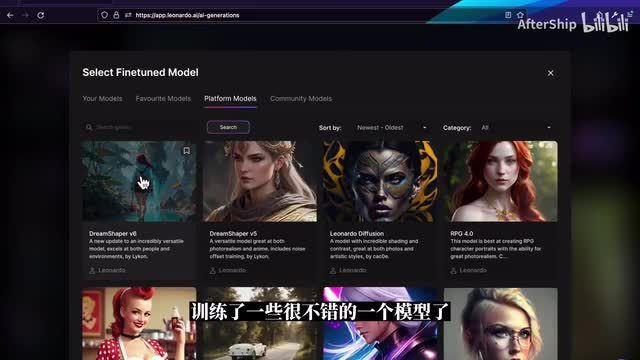
那这个时候如果说你对生成的结果不是很满意的话,我们可以尝试去换一个模型。比如说点击这里,我们就可以选择另外一个模型。leonardo本身已经训练了一些很不错的一个模型了。比如说前两个模型它是针对于人像是做了很多的优化的这一个它就是比较适合去生成一些照片。那我们拿这个jim shark v五再来试一下,ok这个时候图片就生成了。
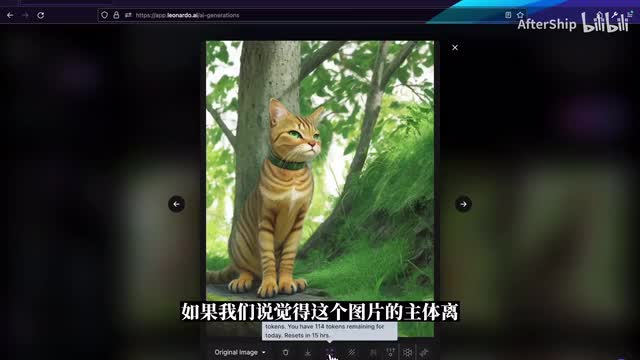
这时候如果你发现一张图片觉得还不错,我们可以对于这个图片做进一步的优化。leod本身提供了一系列的工具来帮助我们去优化图片。如果我们说觉得这个图片的主体离画面比较近,我们可以使用这个on zoom工具来把图片拉远一点。当zoom完成之后,在左边的这个下拉框我们可以看到这个image。对,你可以明显的看到说画面被拉远了。
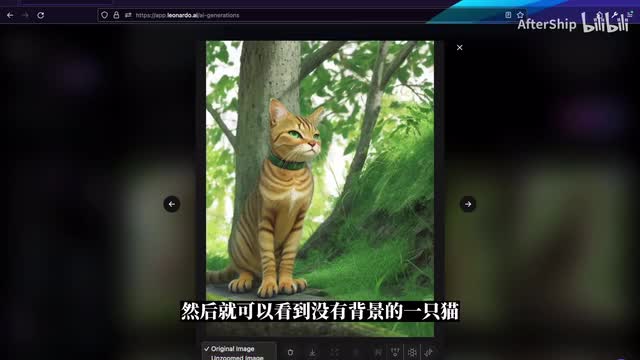
接下来这个是背景移除工具。如果我们不想要图片的背景,只是想要这只猫,我们可以用这个工具。那背景移除成功之后呢,我们可以点击左侧的下拉框,然后就可以看到没有背景的一只猫。右边这三个功能都是跟放大一点,如果一个功能它是只针对付费用户开放。所以免费用户只能用后面这几个。
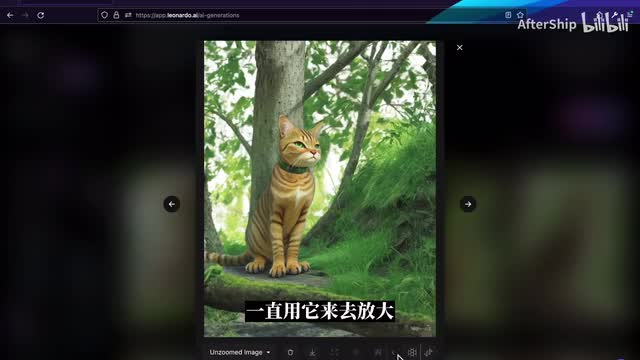
刚开始尝试的时候呢,我建议说你可以三个都试一下。不过说每一次放大图片,它要消耗差不多五个token。所以你在试过几次之后,找到一个不错的,就可以一直用它来去放大。那我们这里是三种都已经生成好了,这个是alternative,我是chris的。不是smooth,那我个人感觉chris的效果会比较好一点。
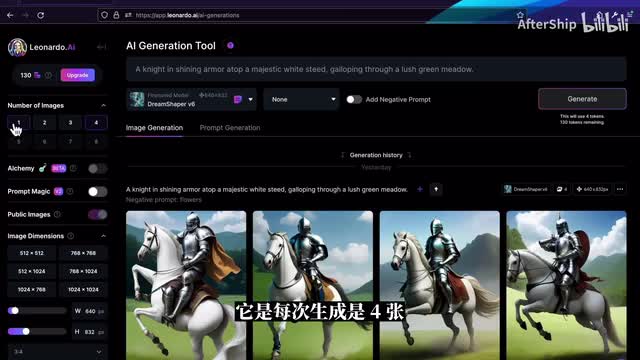
smooth的它会比较柔光的效果吧,聚焦不是特别明显。我们再来看一下图片生成左侧栏的这些工具吧,就最上面是剩余的token数量,免费用户的话每天会有一百五十个token可以领取。然后第二栏是每一次生成图片的张数,通常来说是默认它是每次生成是四张,但你可以选择生成更少。我每一张图片,如果你没有什么其他的设置的话,每一张图片会消耗一个token。第三个是alchemy,这个是leona的最近出的一个新的功能啊,但这个功能目前只面向付费用户,它提供了比如说高分辨率以及类似于h d r的这些效果。
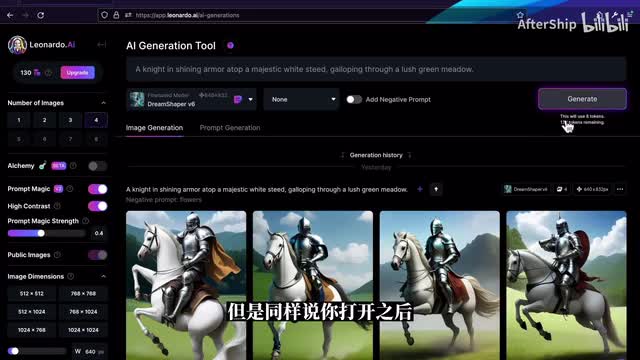
然后往下面是一个program magic,它的意思是你打开之后呢,就是生成的图片会更贴近于你的那些描述词。但是同样是你打开之后,它那个token的花费。会翻倍。就原来生成一张图片是一个token,打开这个pond magic之后呢,每张图片的消耗掉两个token。接下来这个选项是public image。

那他的意思就是说如果你打开的话,你生成的所有图片都是在community defeat里面,是可以被其他人看得到的。但免费用户其实是关不了这个选项的。那如果说你要生成一些见不得人的东西的时候,那还是付费吧。接下来是图片的尺寸,这里有一些预设的尺寸,通常这些尺寸都是一些正方形。如果你想要生成一些,比如说风景你可能需要十六比九,或者说人像可能是三比四。
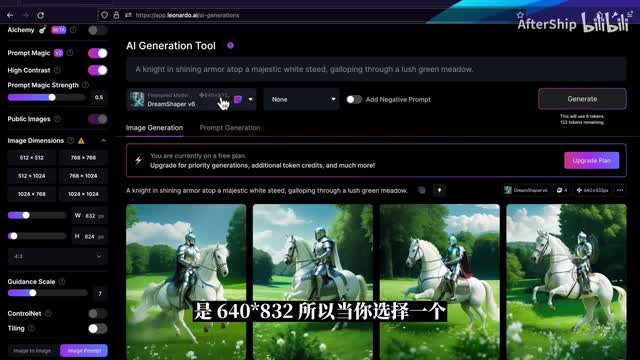
你也可以在下面直接选择一些快速选择一些常用的一些比例。但其实比例会跟训练的基本模型是有关系的。我们在模型的这里你可以看到这个模型的训练参数是六四零乘八三二。所以当你选择一个非常不一样的比例的时候,它这里会提示你这个比例可能会出现一些问题。guide scale的意思是说你的提示词对于生成的结果有多大的影响。
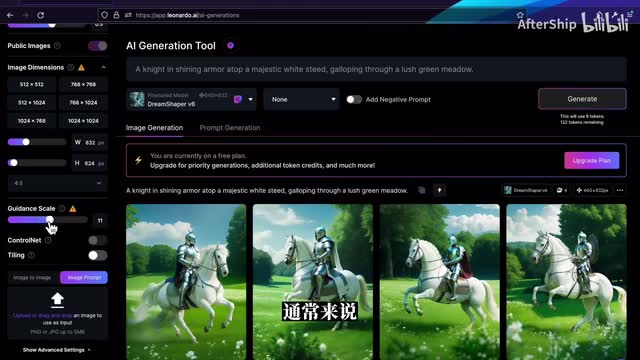
当这个拉到最高的时候,你的提示词是会它会完全按照你的意思去生成。当这个词比较低的时候呢,a i会加入自己的一些创作出来,所以这个图片会完全不一样。通常来说我们就保持在七左右就会比较好。当你拉的比较高的时候,连到的也会告诉。你说你的参数可能会设置的比较高,所以通常来说我们都是在六到十左右会比较好。
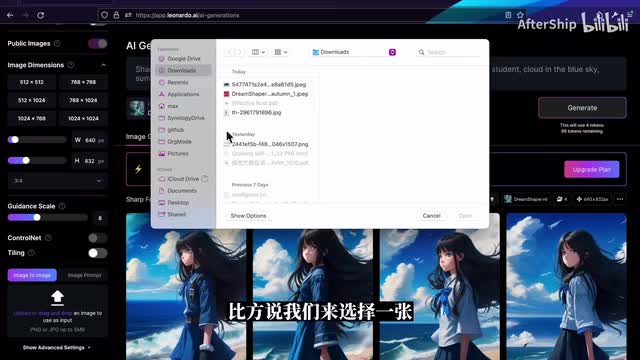
接下来我们来介绍c t r l e t t插件。t r l net在stable diffusion里面是一个非常强大的存在。我们可以上传一张图片,control net会根据这个图片里面的信息来控制我们输出的内容。比方说我们来选择一张这样的图片,当我们打开control net之后呢,我们这里其实有三个选项。比如说post to image,这个意思就是说它会根据图片里面的人物的姿势来重新生成图片。
我们来试一下,这样我们就生成好的图片。可以看到说图片里面的人物的姿势就跟。我们上传的图片的当中呢,其实是保持一样。然后我们来介绍一下这个a i画板啊,a i画板在聊天呢也是一个非常强大的一个功能,我们可以从电脑上随便上传一张图片。调整到跟他那个输入框差不多的一个大小。
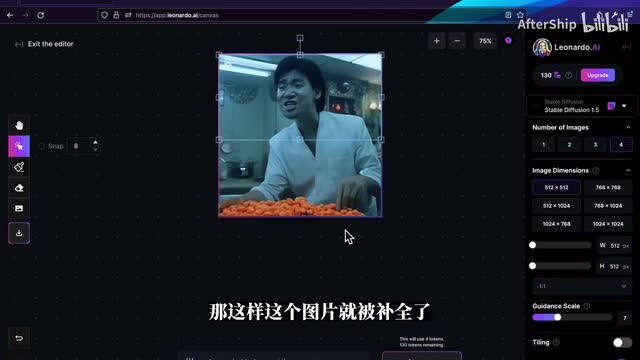
然后我们可以在下面输入一些提示词。那这个时候leonardo就会帮我们补全图片空白的那些区域。你可以在右侧的编辑框里面选择你要生成多少张,那默认它会生成四个方案,你可以选择左右去选择几个你觉得不错的一个方案,那这样这个图片就被补全了。那最后我想讨论一下mu、journey、leonarda以及stability diffusion这三个应该怎么去选?首先你只是想要去尝试一下ai生成图画的能力的话,那嘹亮的我觉得是一个很不错的入门选择。首先它其实是一个云版的一个stability fusion。

那另外就是它免费免费用户有一百五十个tok基本上也是够用的。那另外就是如果你是开发者,你想要把呃a i生成图片这种能力集成到自己的产品里面,然后它的也提供a p i,所以是一个不错的选择。但如果说你想要在移动端使用,或者说对于proud呃没有太多的研究,但是想要生成的效果还不错,也不想要去管什么模型啊什么的,那个journey肯定是最好的。如果说你本身有一台很高性能的c然后你又喜欢折腾的想要去把控很多细节,那svd diffusion肯定是最好的选择。以上就是我们今天视频的全部内容了。

如果你有什么问题呢,欢迎在视频下方留言。如果你觉得本期视频对你有所帮助,也欢迎长按点赞,一键三连支持我们。那我们下期再见,拜拜。




