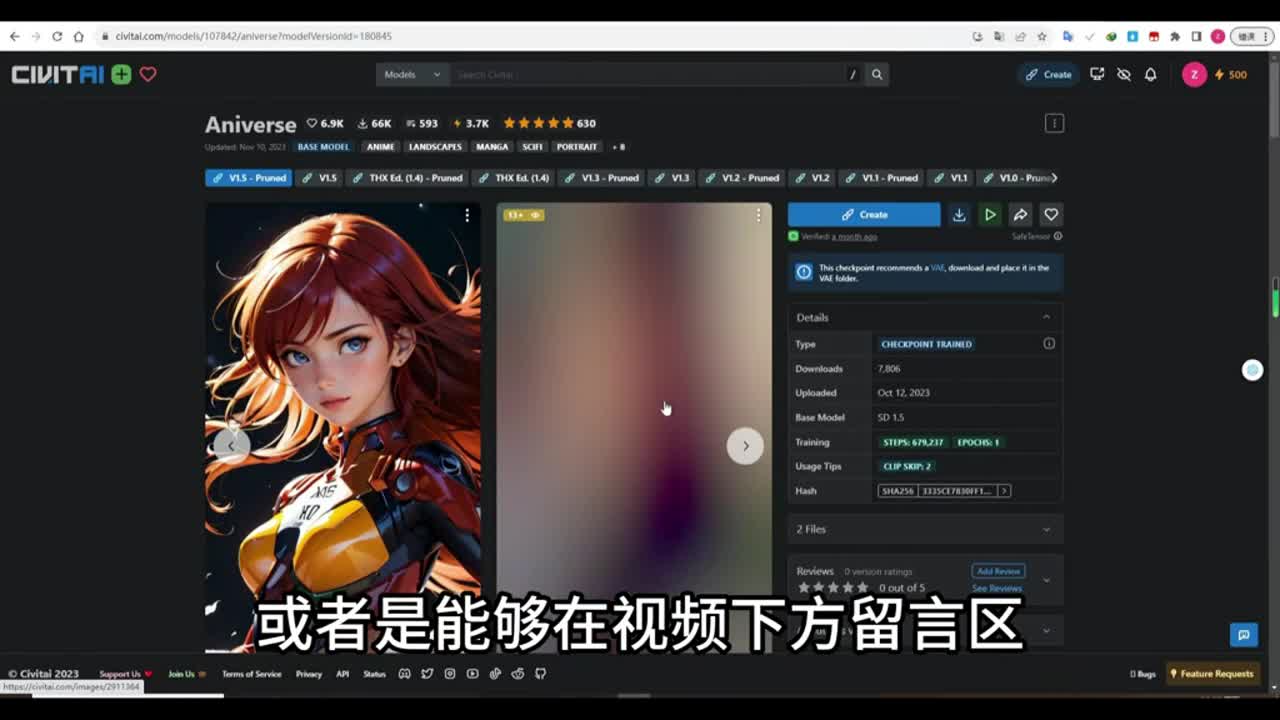
今天呢将带着大家来体验并测试一下enemy deef加conney t加actor这一套组合生成视频动画的这个流程呢,给大家做详细的介绍和测试。我们是使用stable diffusion来生成这些动画。那么如果你会使用check point u i,你也可以用同样的道理使用这一套流程来用coffee u i生成动画。首先呢今天我使用的是这个模型,我会把这些模型的链接都会分享在我的v里面,或者是能够在视频下方留言区备注的地方。凡是能够允许放链接的平台呢,我也会在下方留言区去放这些链接。首先在左上角check code的模型,我们选择好这个,今天我用来测试这个模型,然后呢进入这个样例图片,我们去复制一下它的这个参数和提示词的数据,粘贴到stable defusing里面,我们直接导入。导入好之后,我们需要设置一下它的这个宽度和高度。
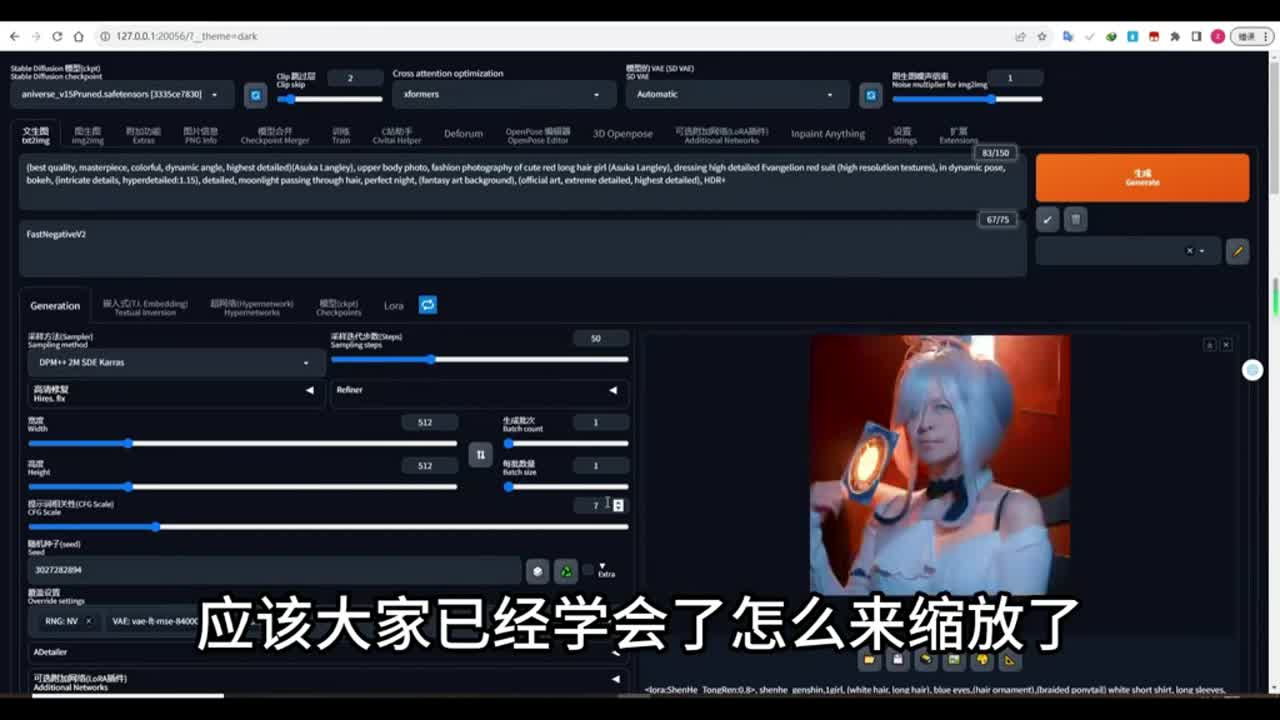
在测试阶段呢我用的是五幺二乘五幺二。这样的话能够生成动画以最快的速度。如果你要高分辨率的话,你可以在生成动画之后呢,用缩放插件对整个动画呢进行缩放。那么今天呢呃我将不讲这个缩放这个操作。因为之前看我视频的话,呃,应该大家已经学会了怎么来缩放了。那么这里的负向提示词呢,大家注意你需要在c站呢去下载这个物站提示词的ebenin模型,也就是嵌入模型。下载好之后放入到你的ebenin的文件夹里面,能够看到这个反向提示词的这个模型呢放在这里面,我们直接使用的就是这个反向提示词模型。
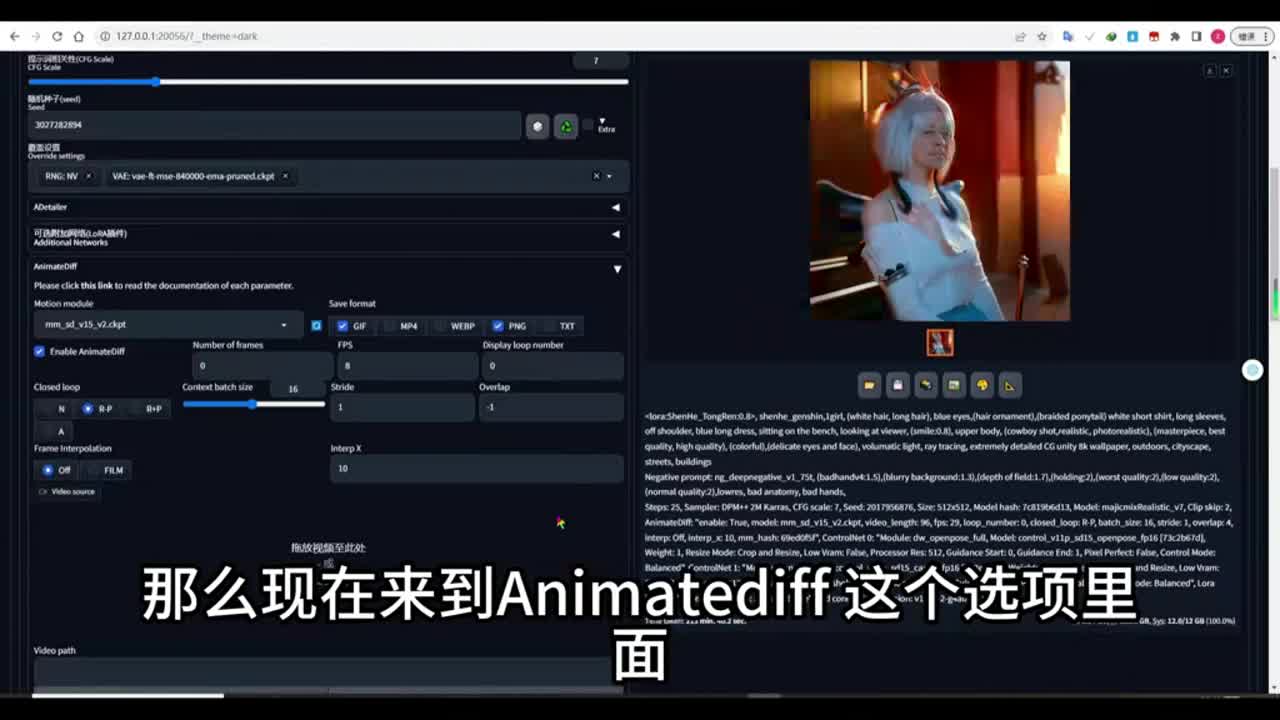
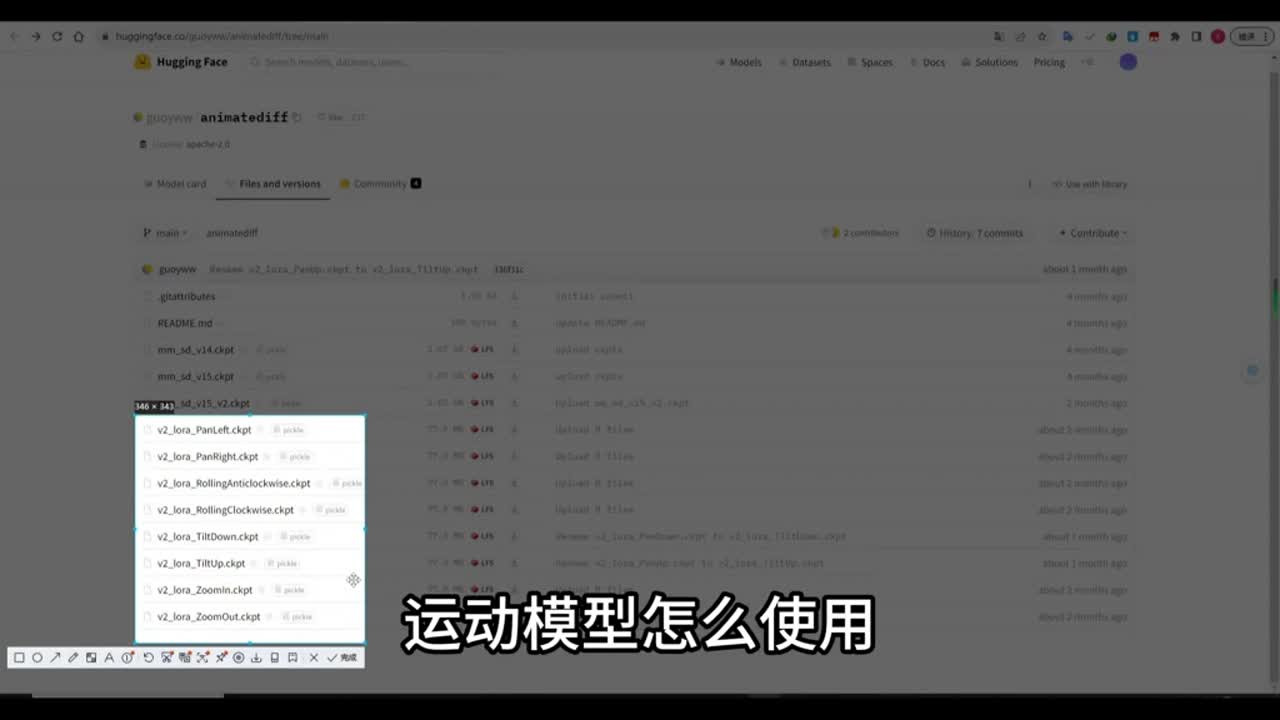
这个模型呢是作者训练好的,能够将图像进行更好的展现。这是一套反向提示词下面的随机种子呢,如果你要保持一致性的话,最好是将这个种子呢给它设置进去。如果你设置为随机种子的话,它不一定能够保持我们人物图像的一致性。那么现在来到enemy dif这个选项里面,点击启用。选择好这个模型,这个还是v r的模型。如果你没有这个模型的话,或者是想下载其他的模型,那么大家可以来到这个hockin face的这个网址里面去下载这个模型。你可以下载v r的,也可以下载其他的。
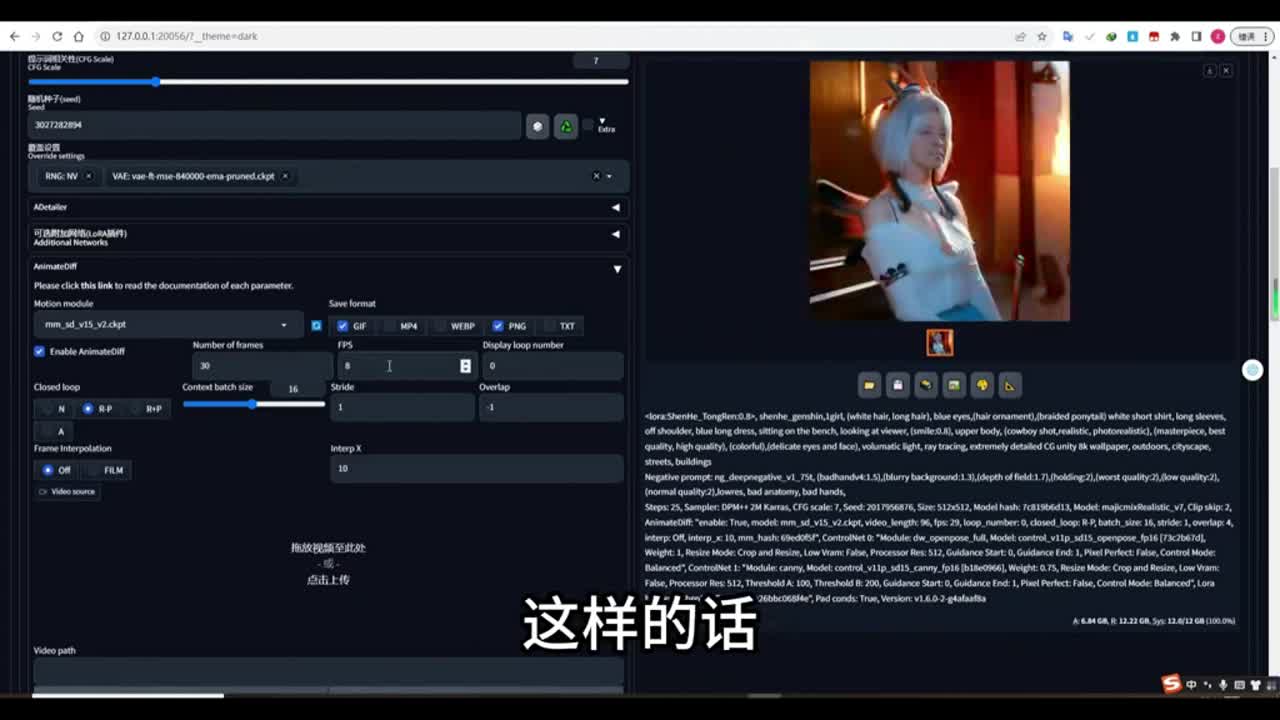
那么这里呢另外要说一点,你可以下载下面的这些动画模型。那么这个v r开头的这个动画模型呢,后面带有laura是什么意思呢?那么后面我会给大家讲到格式,这里面我设置了让它生成g f和p n g的格式,你也可以让它生成m p四的格式。在测试阶段呢,我这里是给它设置为总帧数为三十帧,帧率呢设置为八。这样的话它就能大概生成应该是三十二除以八,也就是四秒的视频,用来测试四秒就够了。那么后面这个选项就是显示闭环号码,这个是什么意思呢?如果设置为零,那么生成的动画呢将可以生成循环播放,就是无限循环的为你播放。如果你设置为一,那么它只播放一次。如果设置为其他。
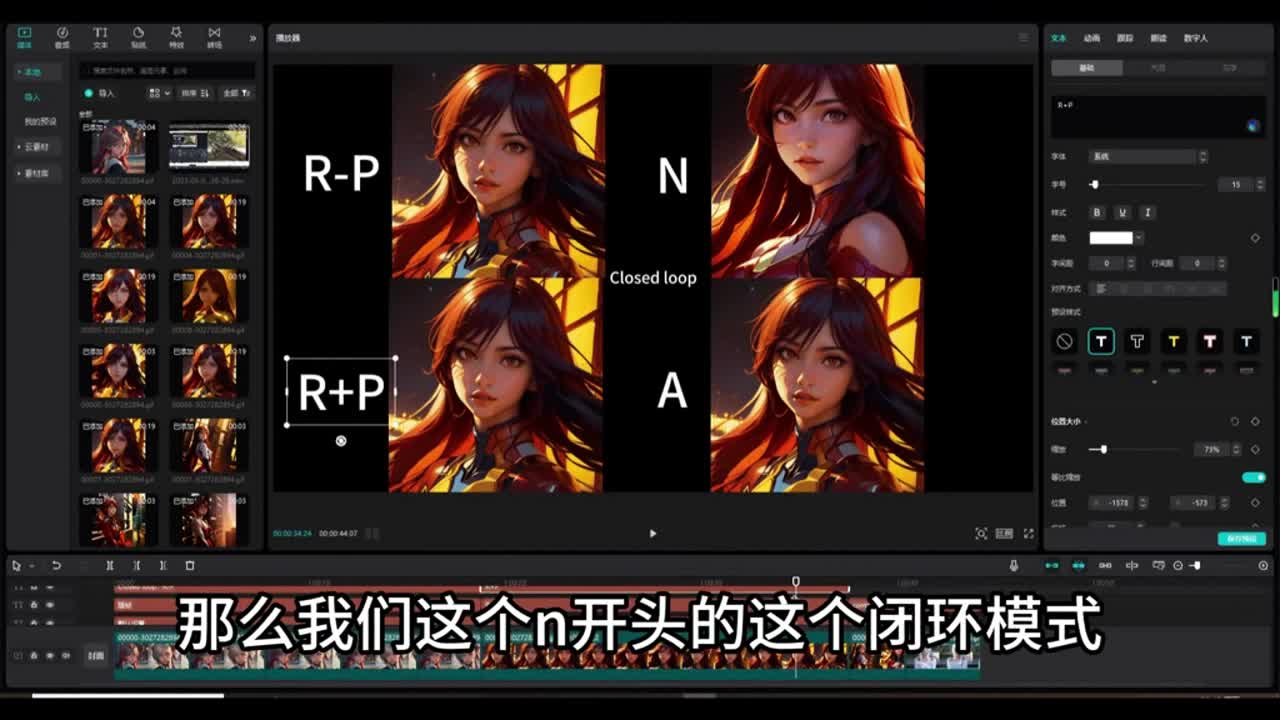
数值呢比如说设置为八,那么它会将循环八次无限循环设置为零就可以了。那么这一块闭环选项什么意思呢?那么我这里为大家测试了这四种闭环的这个模式呢,测试结果给大家展示一下。那么我们这个n开头的这个闭环模式,那么它从第一帧到最后一帧呢将不会保持我们人物的这个一致性。而且呢第一帧和最后一帧因为不一致的情况,所以说我们的人物呢产生一个比较大的一个变化。你可以看到这个动画里面的人物的服装已经发生了改变。而你仔细观看其他的三种模式,看的几乎是一模一样,像同一张图片一样。而且呢其他三种模式都能够保持人物的一致性,而且第一帧和最后一帧呢能够进行一个循环,能够衔接上。

但是从最后一帧到第一帧进行回环,也就是闭环动画的这个时候呢,那有可能你会看见看见那么一点点卡卡顿一下的这个感觉。那么其他三种模式它完全一模一样吗?那么就我个人感觉呢,最后这个选项,也就是a这个选项,这个模式比前面这两种呢感觉上好那么一点点。那么我们平时在默认模式使用的就是这个r杠p的这个模式。其实用。默认的这个也没什么问题,它也可以达到动画的一致性,而且最后一帧到第一帧进行了一个衔接。那么我们来看这个选项,这个选项是上下文批处理大小,这个你可以设置为三种,可以设置为八十六或者是三十二。我们来看设置不同参数的结果,这些呢是生成的测试结果。
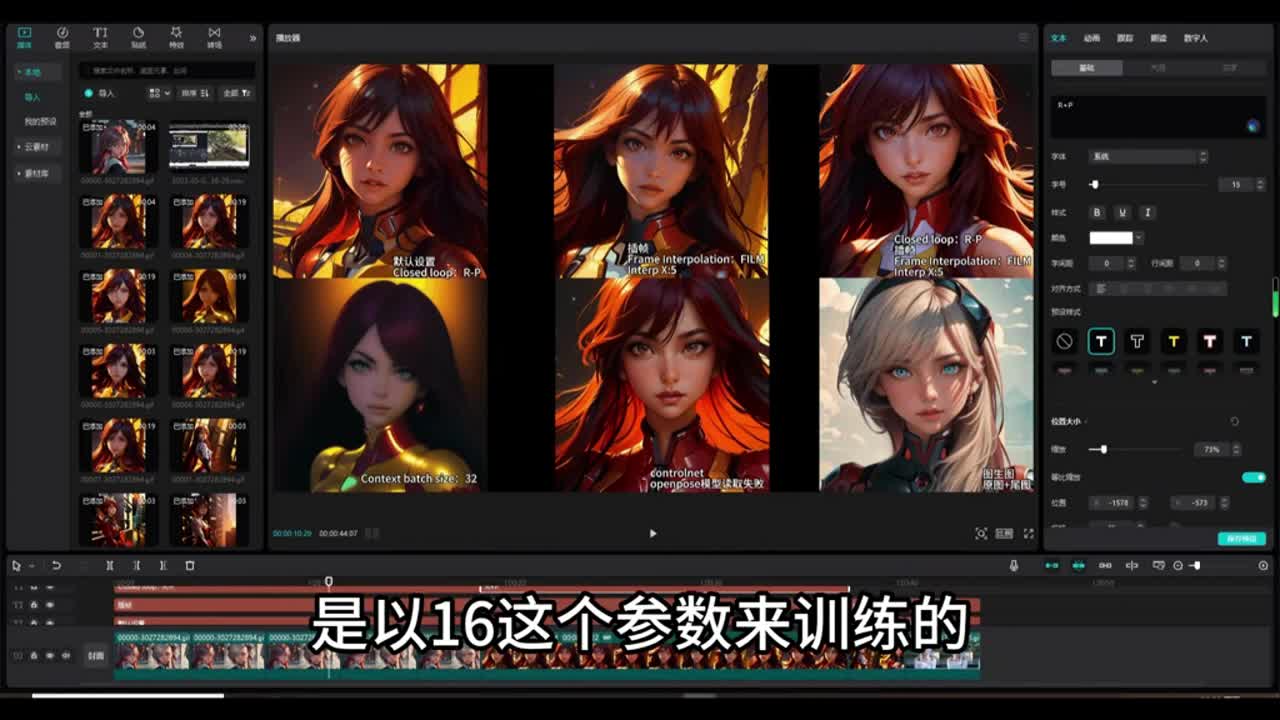
我们可以看到这个生成结果呢就是上下文批处理大小为八。它的处理结果它的处理结果呢就是我们的人物变化比较大,很难保持一致性。那么我们其他的这些测试结果呢,还包括这个测试结果,那么都是参数设置为十六,那么这个一般最好呢已经设置为十六,因为官方训练是以十六的这个参数来训练的。那么如果我们设置为三十二的话,那么就是这个动画结果来给大家再重复看一下。那么设置为三十二的这个结果呢,人物基本上就保持不动,非常的静止。它的动作非常的微小,和静止的慢动作差不多是一个样子。那么来到后面这个选项,这个选项呢也就是跳帧的意思。

那么我们设置为一,也就是它会按照一二三四五六的顺序进行一帧一帧的播放。那么我们设置为二的话,它就是二四六八这种跳帧的动画。如果设置为三的话,那就是三六九。我们来看后面这个选项,这个选项呢一般我们是不用动它的,这个选项的意思是叠加。一般我们也用不到,我们来看下面这个选项,下面这个选项呢是插值帧,也就是在我们的动画里面呢再插进真。一般我们这个选项是关掉的,你也可以为它打开。比如说现在我们是帧率是八,如果我们给它打开就是选项选到第二项,那么后面呢我们要给它设置参数。
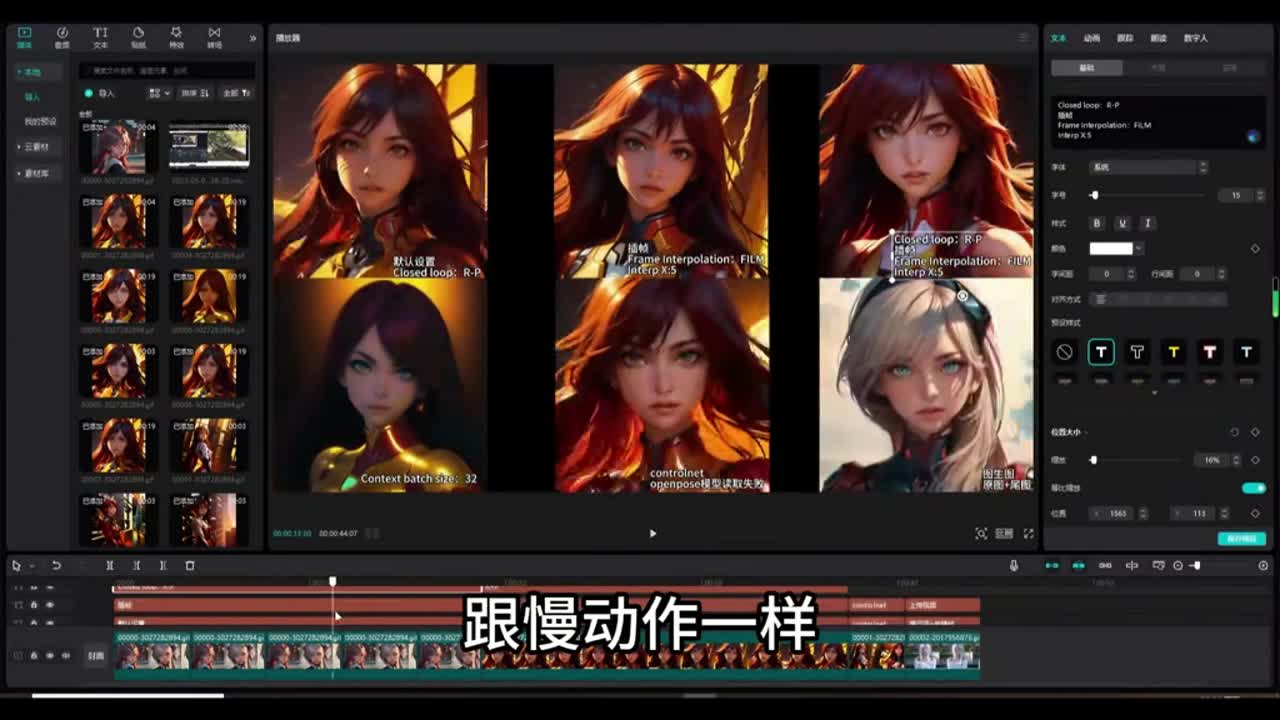
比如说我们设置为五,那么就是五乘以八,也就是在我们帧率为八的情况下乘以五,那么得到四十,也就是将我们的帧率八变成了帧率四十,那么我们的动画呢将变得非常柔和,将变得非常项。我们可以看看一下生成的结果。如果你看到这个动作非常的缓慢,跟慢动作一样。像这样的几个动画呢就是进行了插针。就比如说后面这两个,那么还有这个都进行了插针,所以说它的这个动画动作呢就非常的缓慢。而其他你看起来动作比较快的这种一般的动画,那就是没有进行插针。插针呢会让动作非常的柔和。
我们在测试阶段呢一般是用不到这个插帧,因为它生成的图像比较多,所以我们要关掉它。好,那么来到下面,如果我们没有上传视频的这个情况,只按照提示词我们去为它生成动画。那么它生成的动画呢就会像我们的图片一样进行的随机运动和动画,没有任何的目标和方向,我们来为它上传视频,那上传了一个三秒的一个视频。如果我们仅仅是上传了视频,而没有进行control net的一个控制。这样的话趣味的生成,那么这样生成的动画结果呢,就类似于这张动画。这张动画呢它会类似于我们的视频,因为它没有受到任何的控制,所以说它也是根据我们上传的视频呢进行了一个随机的运动。它只是类似的运动。
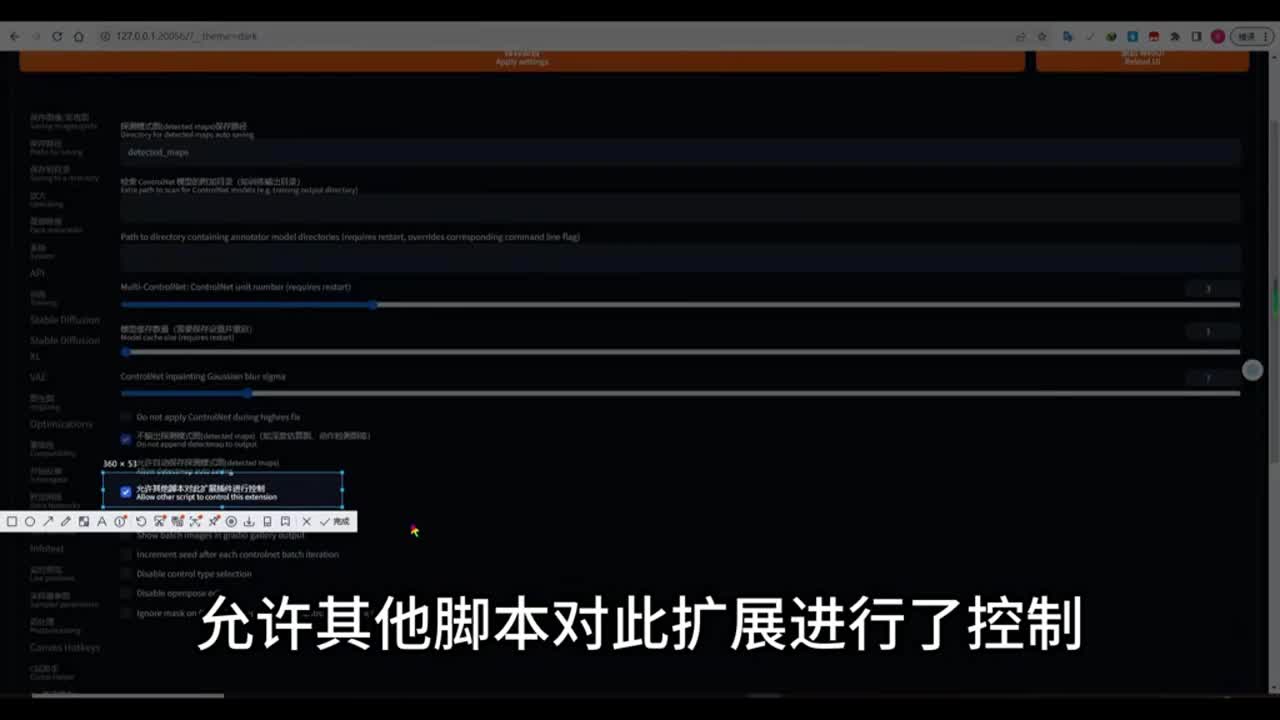
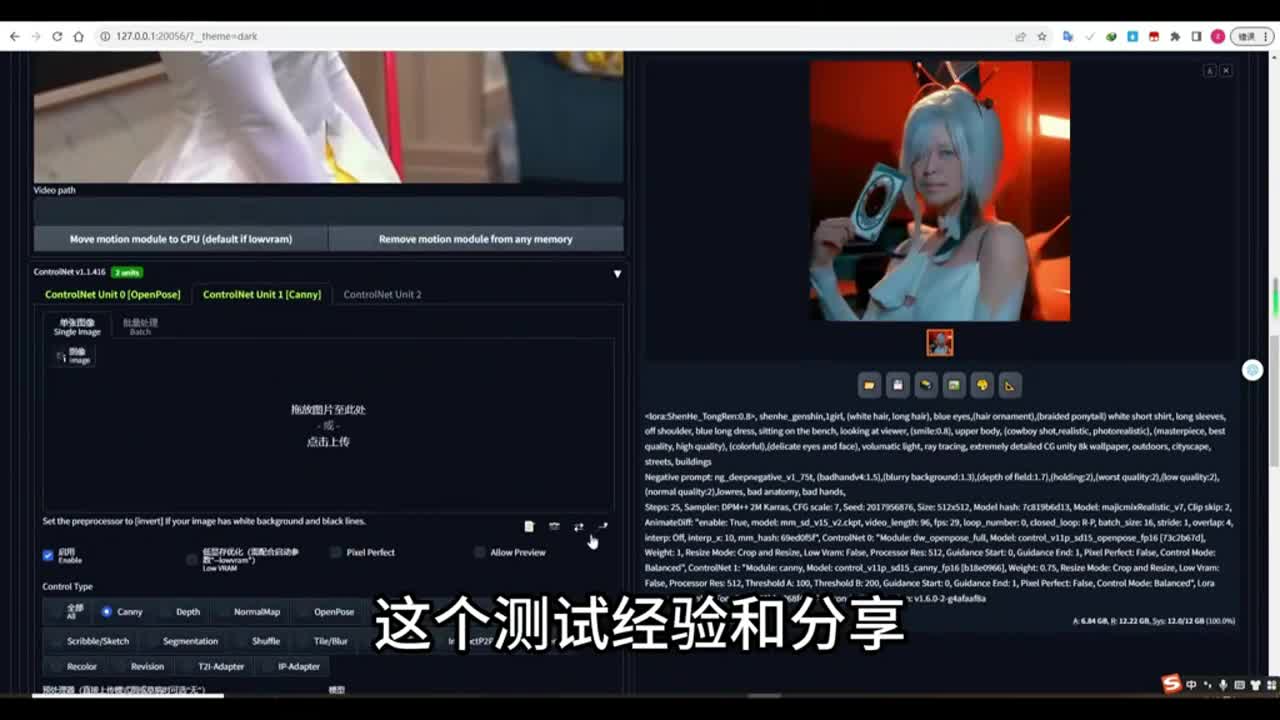
如果在下方呢你使用了count net来辅助帮助我们的动画,结果呢按照视频的画面来为。的生成动画。那么这样的话,你的这个conon net呢可能会报一个错误,会报什么错呢?就是你在终端会报错,错误就是说没有检测到你上传的图像。因为你没有conon net上传任何图像嘛,那么你需要设置里面去检查,找到你的conon net选项里面看这一项,允许其他脚本对此扩展进行了控制。这个选项打勾没有如果它打勾了,你仍然是提示那个图像,那么你需要把你的control t t升级最新的,然后呢,你你你你的net dev也是最新版。如果这样还是不行的话,你已经升级到最新版还是不行的话,还是报错。你没有上传任何图像,你就需要在你的stable diffusion根目录里面,将这个v e n v这个文件夹进行删除。
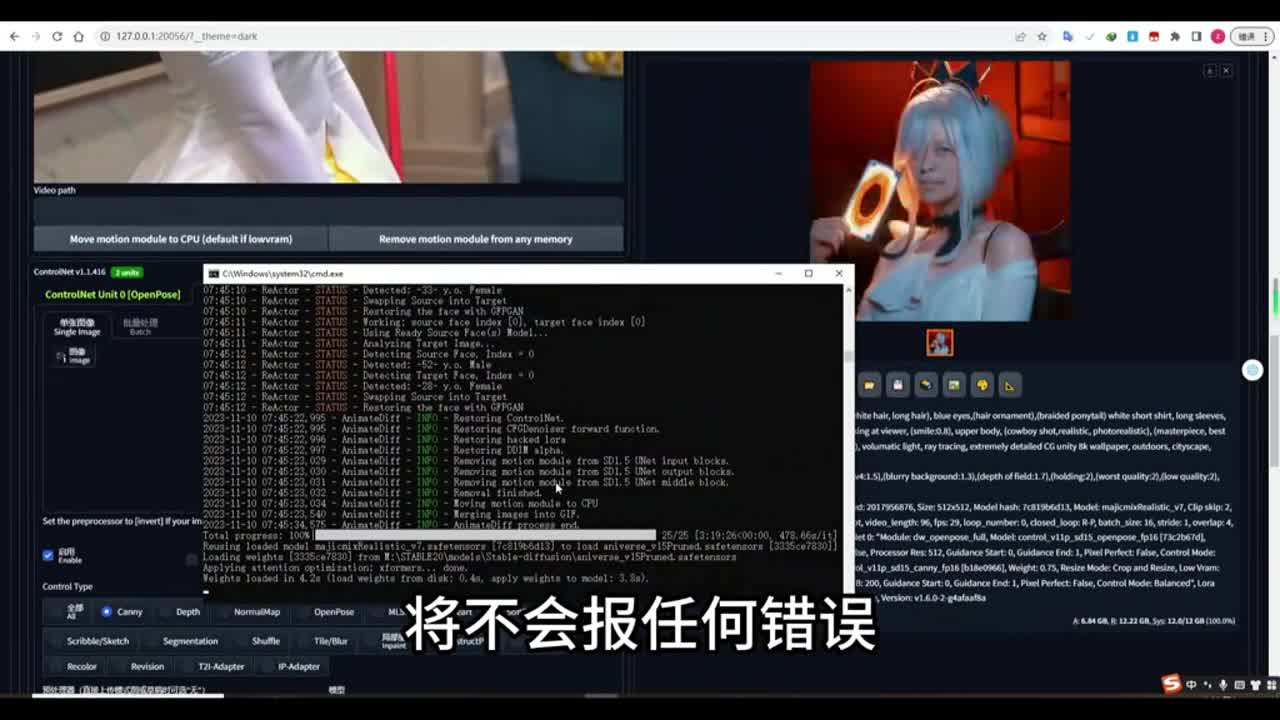
如果你害怕报错的话,可以将它剪切到其他地方,然后呢重新启动我们的stable diffusion启动程序,让让saber direction重新下载这些a i的生成环境,需要为它重新再下载一遍新的东西。当你重新下载了这些v e n v这些。环境包之后能够打开我们的able able delusion的话。那么这个时候呢你使用colon net加这个视频来控制我们的动画,那么终端呢将不会报任何错误,这样的话我们终端就可以通过了。那么现在我们继续使使用open open pose的话,我们使用open pose或者呢你是使用oppose加cn或者是使用open pose加深度模型,也就是depth。你不管是加刊内还是加depth深度模型的话,这个权重呢你可以给它稍微低一点,给到零点七五,这样的效果会更好一些。如果你设置为权重为为一,这样也可以。

只不过测试结果之后呢,你会发现零点七五会比一好一些。那么这里面呢给大家生成了这三种测试结果。第一张呢是单个open pose的控制,中间这张图呢使用open pose加canny或者使用open pose加深度模型。那么我们可以看到最左边的这张图呢,它只有动作,但是没有手上的卡片,是因为没有加刊内我们。加了卡内之后呢,他就可以看到手拿手持的这张卡片了。但是加了龛内之后呢,我们的人物的脸你会发现。人无端的点呢会出现一些变形,这样并不好看。

那么我们就使用了第三种方法,open pose加深度模型。这样的话我们的人物的脸不会进行一个错误变形,而且卡片也能够表现出来人物不会太崩。那么加上colony的控制之后,给它加第三项,也就是reactor人物换脸。那么人物换脸呢我将给它更换checkpoint的模型,我们更换之前使用的麦桔麦桔真人模型,人物模型呢换脸你才能看出来它的变化。那么提示词呢我们更换成这个模型的这个提示词,我们将reactor进行使用。这个选项呢我不认我我们在下面这个选项呢,我们选选择面部修复。因为我们生成的图像是五幺二乘五幺二的比较小。
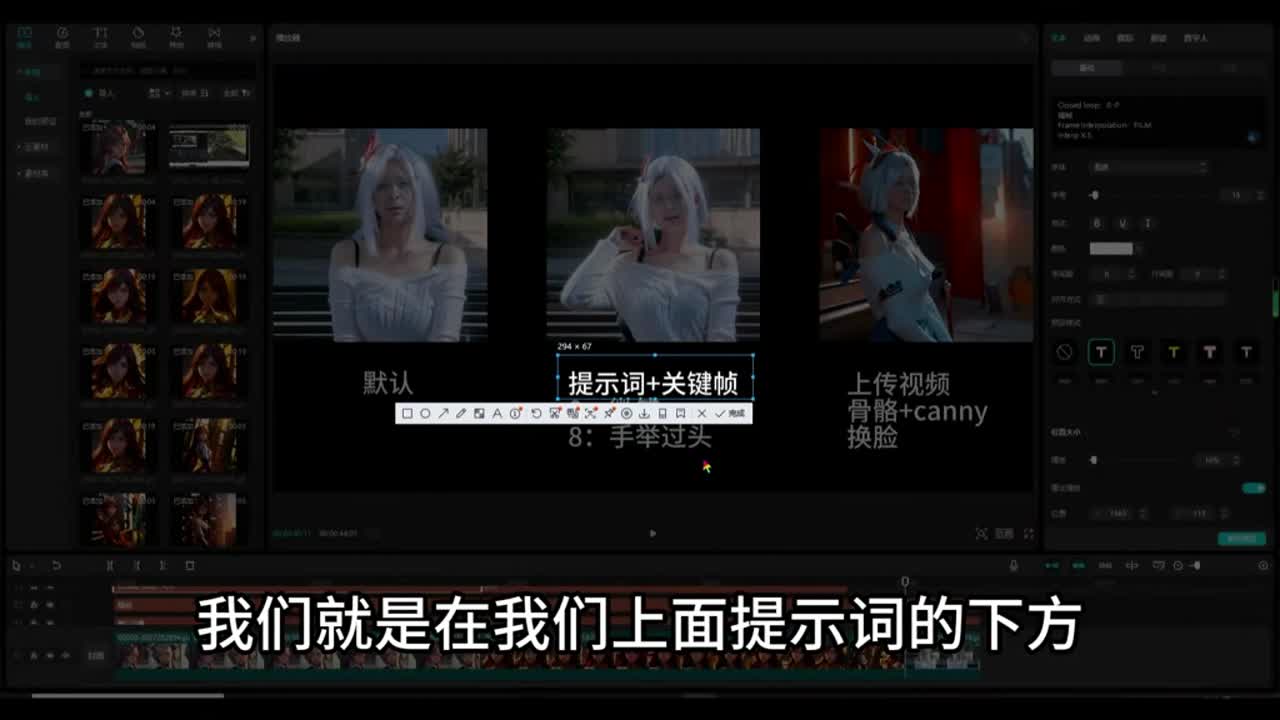
那么这个换脸权重的设置为一,然后我们就可以为它这个生成了生成的图像。我们来看一下这个,这是三种测试结果。第一张图呢是默认的测试模型,我们进行一个词的形式,那么这张图像呢就是提示词,我为他。增加了关键帧提示词。那么什么是关键帧提示词呢?就是在第第零帧的就是在我们就是在我们上面提示词的下方,我们可以给它加上在第零帧的关键帧位置处,让它出现什么动作,然后在第八帧的关键帧位置处让它出现什么动作。那么这样的话会按照提示词为我们生成不同真不同的动作,可以这样来控制。那么如果我们要是使用control net骨骼这些模型来控制我们的人物动画的情况呢,我们就可以不使用提示词里面的这个关键帧控制。
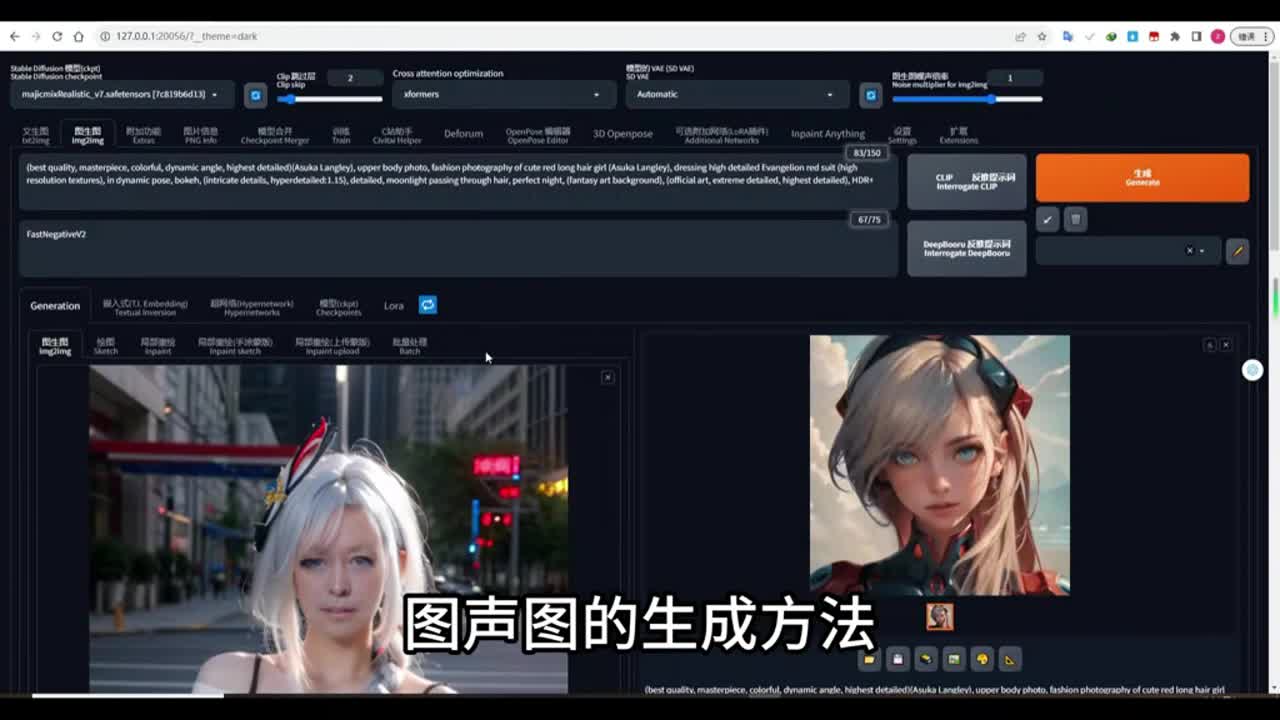
那么你也可以使用,但是最好不要使用这些提示。现在我们来看一下这三种测试结果。如果你使用connect来控制的话。那么你提示词里面加上这些关键帧控制的话就会产生冲突。那么现在我们来说图生图呃图生图的生成方法。那么图生图我们可以上传一张原图,固定好种子之后,然后下面你可以上传视频,也可以不上传视频。那么你可以上传一张结果图,也就是你这张你的这个动画呢最后一张图要生成什么样子?它的结果图,那么在上面呢我设置的是总帧数是三十二帧。
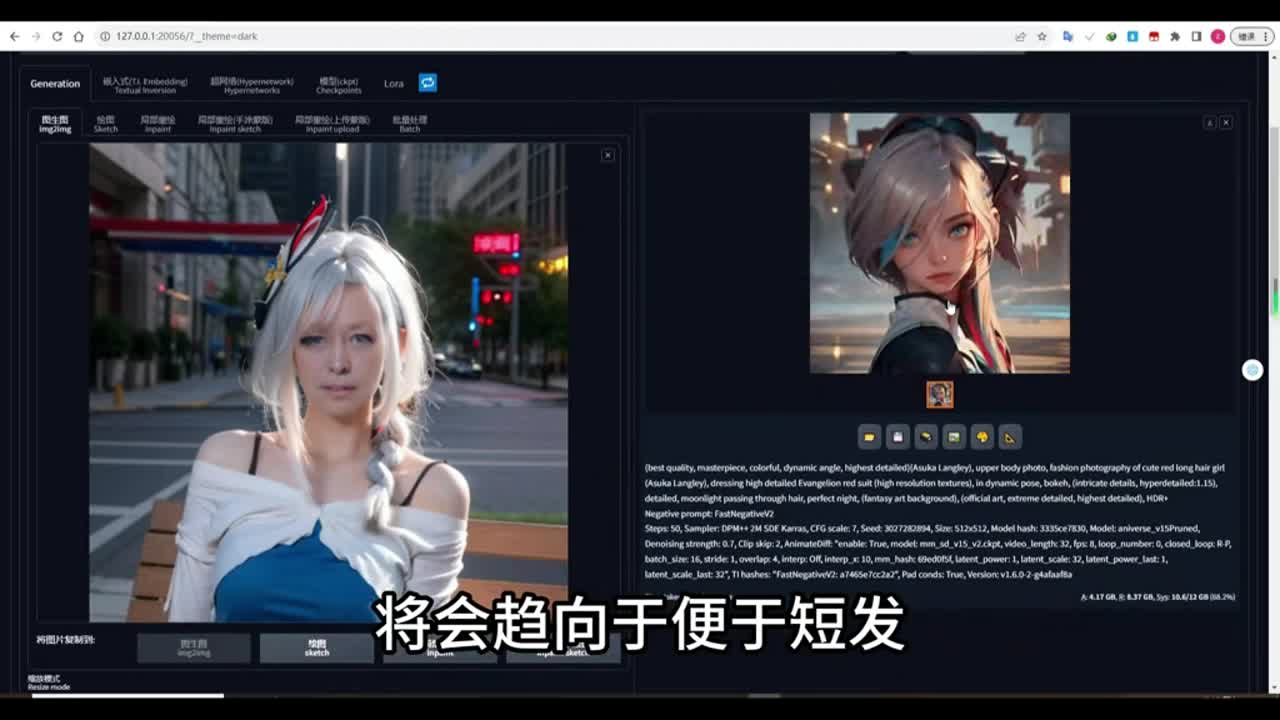
那么在下面在这个位置,还有在这个位置你要给它设置为也是三十二。这样的话确定它是最后一张图,这样的话我们生成的结果呢就类似于右边它会在一开始有这个人,我们的人物呢有它这个长辫子的这个动画。那么到最后它这个辫子消失,将会趋向于便于短化。这个生成结果呢我使用的是动画模型,没有使用真人。所以说它生成的这个结果呢不会完全像我们的原图和像我们的尾图。只是给大家讲一下这个原理,它就是按照我们的原图和尾图进行了一个变化。如果你在这里呢上传视频,那么它在动画的中间过程当中呢,也会按照视频来进行变化。
那么如果你要是使用真人模型来生成这个动画组成图动画的话,那么就是这个样子。我们的原图是一个远景,那么这个尾图呢是一个近景。那么它就是能够产生这种远景到近景的动画。好,那么现在来说一下下面的这些laura这些模型运动模型怎么使用。比如说你下载了一个运动模型,也就是向左运动的这个模型,你将它呢放到你的这个ura模型文件夹里面。放进来之后呢,你可以在正向提示词里面为它加上这个提示词。加上这个提示词之后,它有一个权重,你可以设置,那么最好我们也设置为零点七五,这样的话不会过拟合。
然后我们生成的动画呢,它的背景就会进行一个向左移动的一个动画模式。这是由laura来控制enemy deef它的这个镜头镜头动画的这个laura模型。好了,那么这就是这两三天使用这一套生成动画流程的这个测试经验和分享。那么我觉得这一套流程呢已经给大家介绍的非常详细,也思路非常的清晰。大家觉得如何呢?如果大家有什么意见或者是评价。可以在我的视频下方留言。如果这期视频觉得对大家的帮助比较大,那么请为我点击关注加三连。
那这样呢会帮我的视频增加平台的权重,那么谢谢大家。那后面呢努力为大家出更好的干货视频。




