
大家好,我是咖啡猫,欢迎来到我的视频。当我们欣赏到一些令人惊叹的k a i绘图作品时,是否也想要自己创作一幅呢?但是当我们从网上下载stable diffusion模型,使用了相同的关键词tag,却往往达不到宣传的效果,这是因为决定绘图好坏的不仅仅是写好关键词tag这么简单。另一方面,网络上可供下载的模型往往提供多个版本,不同版本的模型大小存在差异,我们应该如何选择呢?c b t i网站提供了众多免费的stable diffusion的模型,点开后有的显示chap,有有的显示textron inversion或者ura或者hyper network,这些又该如何选择使用呢?今天咖啡猫就来告诉大家如何从c站下载模型并正确使用它们以达到理想的绘图效果。我们先来简单区分一下这几个模型的概念。

大模型也有叫做d模型,包含了数以亿计的参数。像stable diffusion的一点四版本、一点五版本、二点零版本和二点一版本均属于大模型,具备泛化性,这是绘图时候必须要有的模型。v a e模型是在图像生成的最后将图像在潜在空间中的隐变量latent variable解码为我们可以识别的图像,这也是绘图必须有的模型。只是有时候大模型内部已经内嵌了v a e模型,就不需要我们额外添加了laura dream booth embedding hyper network这几个均属于在大模型的基础上的微调模型,能帮助绘制出特定风格和特定任务的图像,它们是可选的,根据你的需要添加。

laura, embedding hyper network需要配合大模型使用,而dream booth由于其训练后与大模型做了合并,因此你也可以把采用dream booth方法训练后的模型看作是大模型,所以最后当我们绘图的时候,至少需要具备大模型和v a e模型。没有微调模型,只是说无法绘制特定的图像,但还是可以生成图像。check point模型是指在训练过程中保存的模型参数,用于在训练过程中进行模型恢复或模型迁移。由于任何训练后的大模型都可以看作是某个阶段的模型版本,因此check check point等于大模型,底模型等于dream box模型。

说法上是一样的。textual inversion代表一种基于文本的繁衍方法,可以通过输入一个文本生成其对应的潜在向量表示。当前我们一般把embedding型也称为textual inversion,它们在原理上有相通的地方。了解了这几种模型的概念后,我们接下来再试着区分一下模型的后缀名语、版本名称。
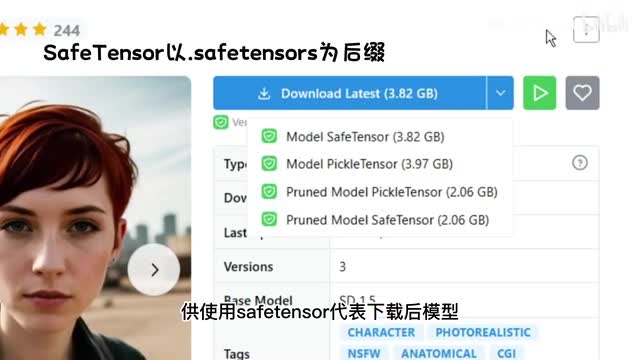
这里还要再学习几个专业名词。我们点击c c t模型的下载按钮后,有时候会看到模型提供了多个版本供使用。safe tensor代表下载后模型以safe tensor为后缀。pick tensor代表下载后,模型以c k p t为后缀。
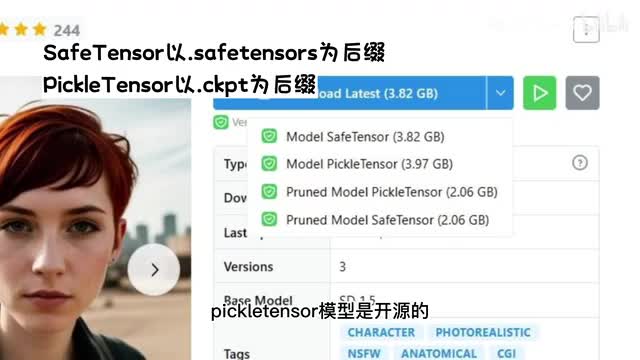
这两种模型本质上是一样的,只是safe tensor是受到加密保护的,我们无法用编程的形式直接读取参数,除非获得开发者提供的密钥。而pico tensor是不受加密保护。换句话说,pick tensor模型是开源的,safe tensor是不开源的。c tensor格式是由hugging in face推出,据说它的加载速度比c k p t更快,将会逐渐取代c k p t p t e等格式,并且更加安全,不会包含恶意代码。

而c k p t文件使用p q序列化的这意味着它们可能包含恶意代码。如果你不信任模型来源,加载c k p t文件可能会危及你的安全。对于使用者来说,推荐c tensor。prune是指经过剪枝pruning的神经网络模型文件。
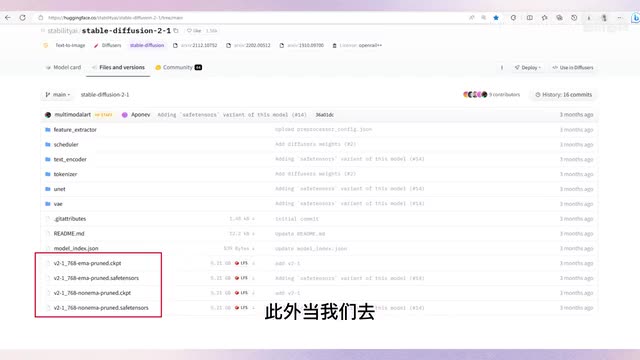
剪枝是一种神经网络优化技术,它通过删除一些冗余的神经元或连接来减少神经网络的复杂度,从而提高模型的运行速度和泛化性能。推荐使用pro的模型,它不仅泛化性更好,而且剪枝意味着参数的减少,模型文件需要的储存空间更小。此外当我们去hugging face下载stable diffusion一点五版本或二点一版本的模型时,还会看到e m a或者e m a only的字样。e m a也是一种常用的优化神经网络的方法,它可以平滑模型的参数更新,降低训练过程中的震荡和波动,提高模型的鲁棒性和泛化能力。

一般选择e m a优化后的模型会更好。有时候模型的文件名上还会看到s t s t一六、s t三二这类单词,这代表模型数据使用了不同数据类型。进行储存的f t十六、f t三二分别代表了单精度和半精度浮点数。简单理解就是f t三二相比于s t十六保留了更多小数。

由于f t十六的数据精度较低,可能会影响模型的性能和精度。我们可以减少模型的存储空间和计算量,从而提高模型的训练和推理效率。如果电脑内存足够,那就选择f t三二吧。说了这么多,终于要进入正题了。
现在开始介绍如何下载并使用模型。我们点开c站主页可以看到这里提供了很多绘图类别的模型下载。有动漫的,有女子的,有游戏的,还有卡通的等等。往下每个模型的缩略图左上角都会标注这个模型的类别。
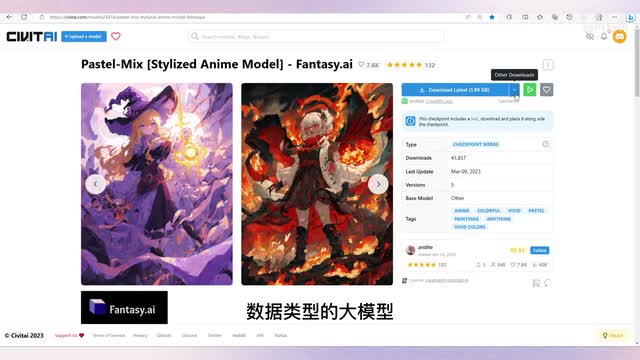
我们这个模型是checkpoint模,这个模型是lora模型。我们我们点点开一个check point模型,在这个位置可以看到这里提供了safe tensor数据类型。的大模型,这个模型有一点九九g b,同时它还提供了一个v a e模型。我们刚才介绍过check point,point可以是大模型,也可以是dream booth模型。
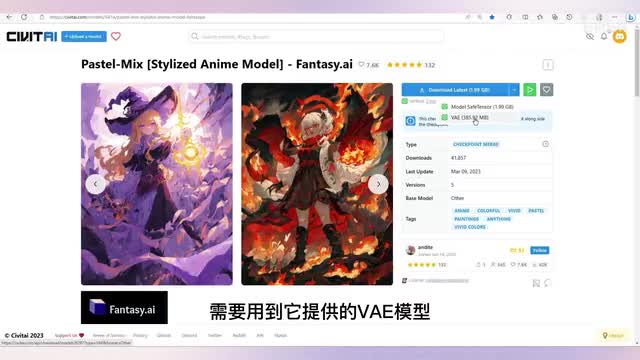
当然也有可能是通过其他某种方法训练出来的模型,这不重要。我们只要知道它是一个具有绘制这种动漫绘图风格能力的大模型就可以了。并且在使用的时候需要用到它提供的v a e模型。下载后我们把这个大模型放在web u i的model stable diffusion文件夹内,然后把v a e模型放在model v文件夹内。
打开web u i界面,在setting的这个位置选择我们下载的v a e模型,点击应用,然后点开text to image界面,在这里选择我们下载的大模型。模型就设置好了,现在让我们来输入关键词并调整好参数吧。我们打开官网点开这边任意一张图片,发布者并没有给我们提供这张图片的关键词参数信息,因为这里是空的,没关系,我们返回往下拖动,这下面都是用户上传的采用这个模型绘制的图片。我们点开这一张,这里就有关键词信息了。
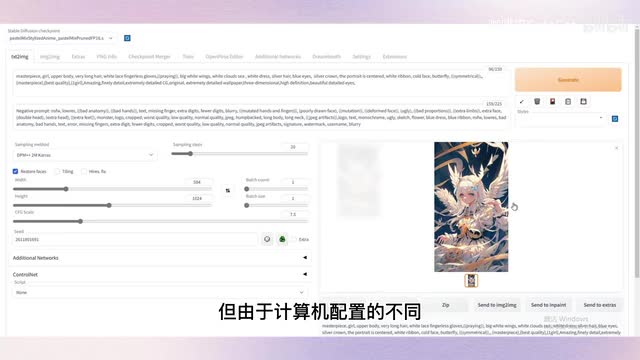
这下面还有一些具体的参数设置,我们按照这种设置填好参数,把种子数也复制过来,图片大小选择五百八十八乘一千零二十四,运行一下,可以看到生成的图像已经非常类似了。但由于计算机配置的不同,生成的结果难免有些差异。我们再来试试,如果不使用他们给的v a e模型会是什么效果。是不是有点灰蒙蒙的感觉,色彩饱和度明显低了不少。
所以选择正确的v a e模型是很重要的,现在我们就可以在这个基础上局部修改。誓词进行绘图了,下面我们再找一个laura模型试试看。我们在搜索框中输入laura,找到一个自己喜欢的laura模型,我们试试这个,这是原神中甘雨的人物,laura模型有写实风和动漫风两种。点击下载模型。
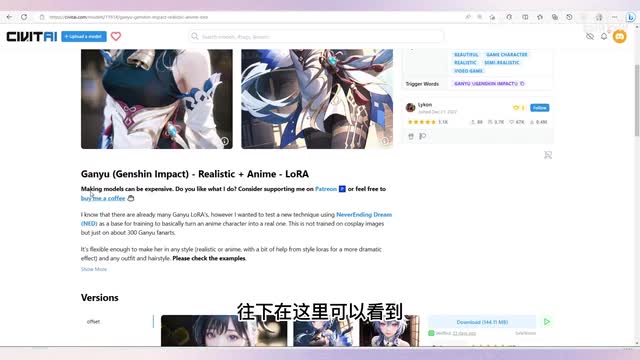
正如之前介绍的,laura模型是在大模型的基础上微调而来的。所以为了画出这种风格的人物,我们还要下载大模型。那配合这种laura的大模型是什么呢?往下在这里可以看到发布者介绍说大模型是这个叫never ending dream nad的模型。点击这张写实风格的人物可以看到,在这个位置也显示说大模型是never ending dream这个模型。
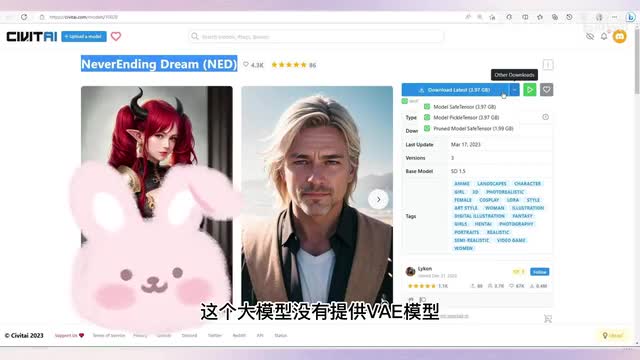
所以我们要先下载它,在c站内搜索一下,看看还真的有,我们把这个大模型下载下来,同样的放在model stable diffusion文件夹内,把laura模型放在这里。这个大模型没有提供v a e模型,那也许v a e模型已经内嵌到大模型内了。我们先不管v a e模型试运行一下看,接着我们还是复制关键词信息参数到text to image中。可以看到在这个关键词是这个大括号里的。
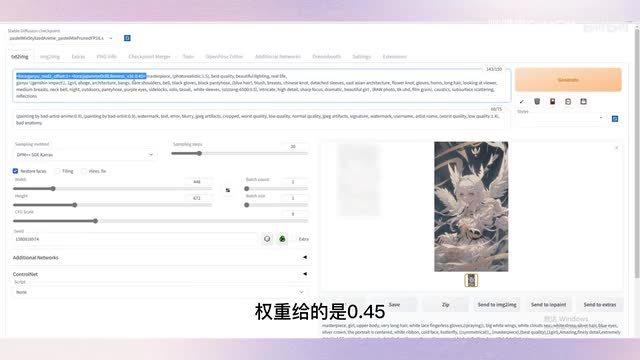
内容就是我们下载的甘雨laura模型,权重给的是一。此外它还添加了另一个laura模型,japanese lateness, 权重给的是零点四五。这个lura是要下载的,这里就不演示了。我把这两个laura删掉,下面演示一下如何手动添加。
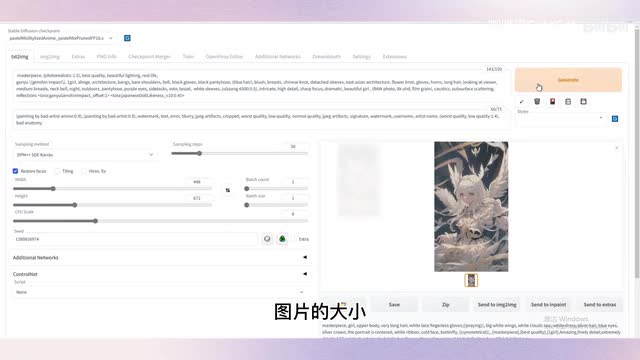
点击这个红色的按钮,点击laura选项,然后点击甘雨和japanese lateness,laura就自动添加到文本框了。是不是很简单?把权重调整一下,图片的大小选择四百四十八乘六百七十二,选择好大模型。接着点击运行。这个图像稍微有一点呃,我就不完全显示了。
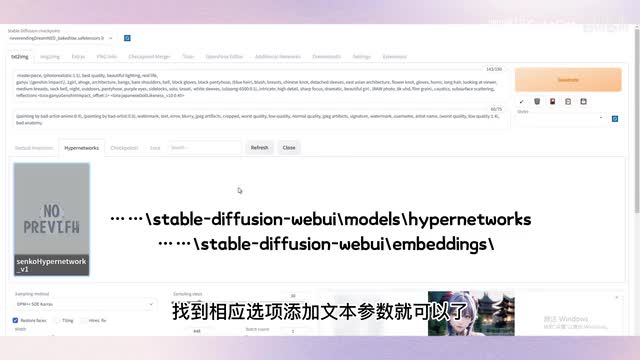
尽管衣服有差异,但是人物形象已经非常接近了。embedding和hyper network模型我这里就不演示了,也是一样的操作。下载模型后,放在指定的文件目录下,点击这个红色按钮,找到相应选项,添加文本参数就可以了。感谢大家收看本视频,希望这个视频能够帮助大家了解如何从c站下载并使用ai绘图模型,并在实践中不断提升自己的能力和技巧,创造出更加优秀的作品。

如果你觉得这个视频有帮助,记得分享给你的朋友,如果你想学习更多更好玩的ai绘图技巧,记得关注我哟,我们下期再见。




