
a i语音合成技术又进化了,你现在听到的声音是我用麦克风录制的声音。你现在听到的声音是我用人工智能技术合成的声音,你能听出来区别吗?你就说生意像不像吧。之前我就发布过一期v i t s声音克隆技术的教学视频。今天呢继续分享两个升级版的克隆技术,效果不仅更好,甚至只需要一分钟的音频也能训练出效果非常不错的模型。你是否想学习这个i技术?想学习的小伙伴请把签到打在公屏上。学会了本期视频,你也能克隆自己的声音或者是其他人的声音。好了,废话不多说,我们直接进入正题吧。
今天讲解两个a i算法的使用,bert v i t s二和g p t s。o v i t s这两个a i算法的一键启动包,我都放到了视频的简介里。观众老爷们用的不错的话,别忘了给个免费的赞了。bert v i t s二是这位up主开源的项目,声音克隆效果稳定而声音还原度高。g p t s o v i t s是另一位up主开源的项目,可以仅用一分钟的音频数据就能快速微调出不错的声音模型。我们先看bert v i t s,这两个就是我解压好的两个项目,我们可以使用v s code打开这个工程。我们先看bert v i t s two,这里边可以看到它一个详细的代码。
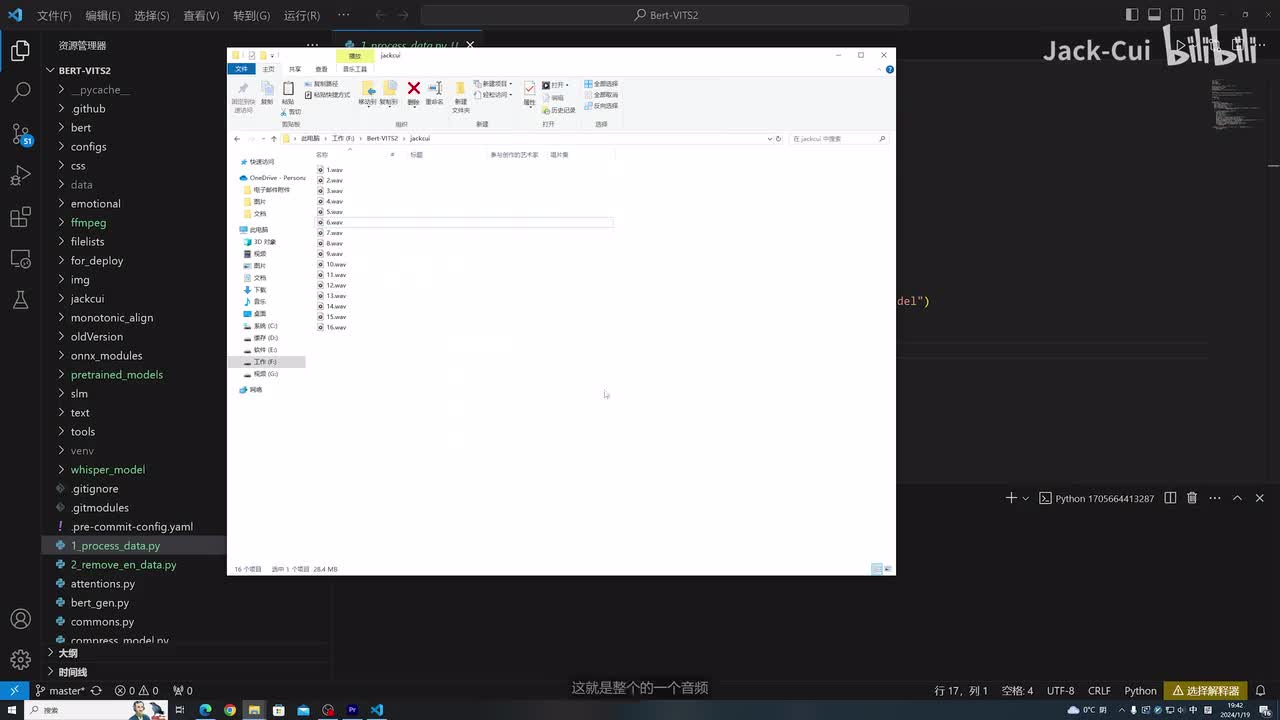
然后我们先拷贝一下我们需要训练的音频。这里边我找来了是我自己的一个声音,可以放到一个根目录,这就是我往期视频的一个录制的声音,大家可以听一下。大家好,我是jack。最近a i领域的发展的日新月异啊,这就是整个的一个音频。我拷贝了几期我的一个视频,然后当做一个训练集给大家演示一下。我们首先需要运行这个数据的预处理,就是把我们的语音进行一个识别。这里边我用到的是一个whisper r的一个工具啊,这里边需要改一下这个名字。
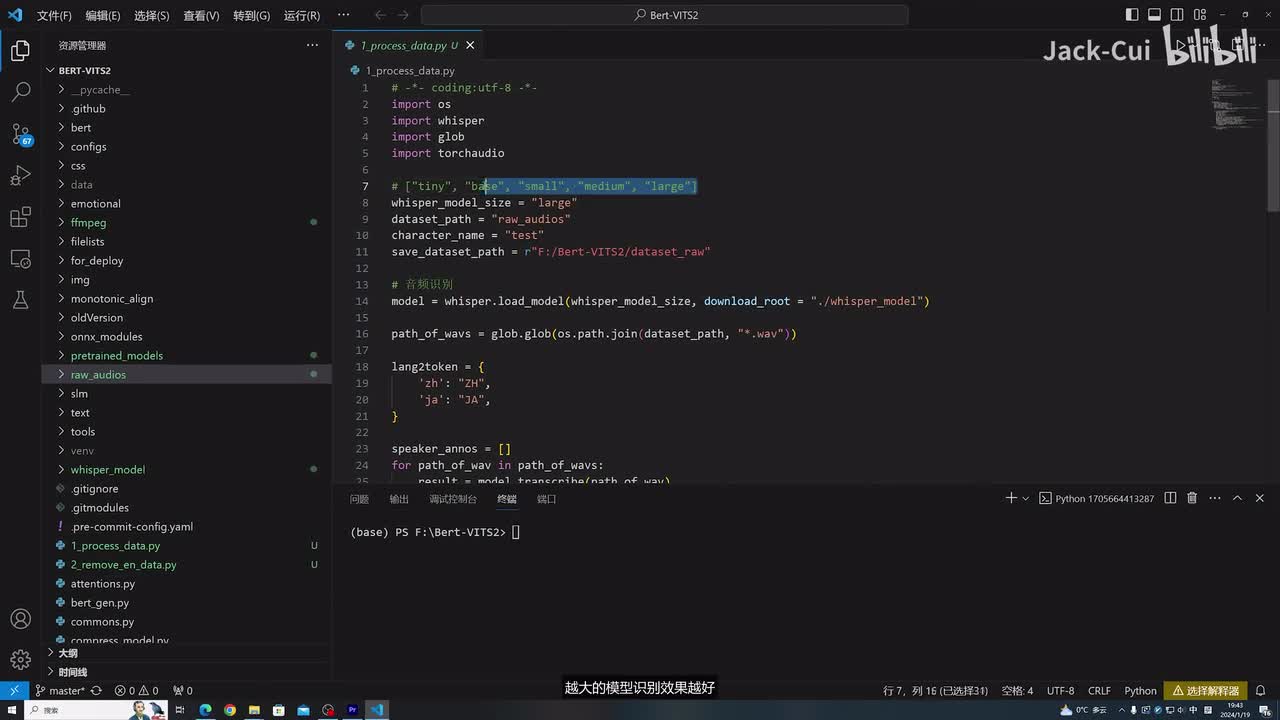
我们把我们的这里的名字jack可以改为这个raw audience,就是相当于我是存储这个原始音频的一个地址。然后这里边选择的模型选我这里面选择large,这里边有很多模型可以选啊。就比如说tiny是最小的,然后medium是中间的,然后还有large是最大的。越大的模型呢识别效果越好,但是可能需要的机器资源的一个字,大家根据自己的情况选择就行。如果你的机器性能不够的话,可以选择一个的一个模型角色的一个名字。这里面需要我叫jack吧。嗯,这边可以随便起,就是你训练这个音频,你也可以给它起什么名字,可以写到这里。
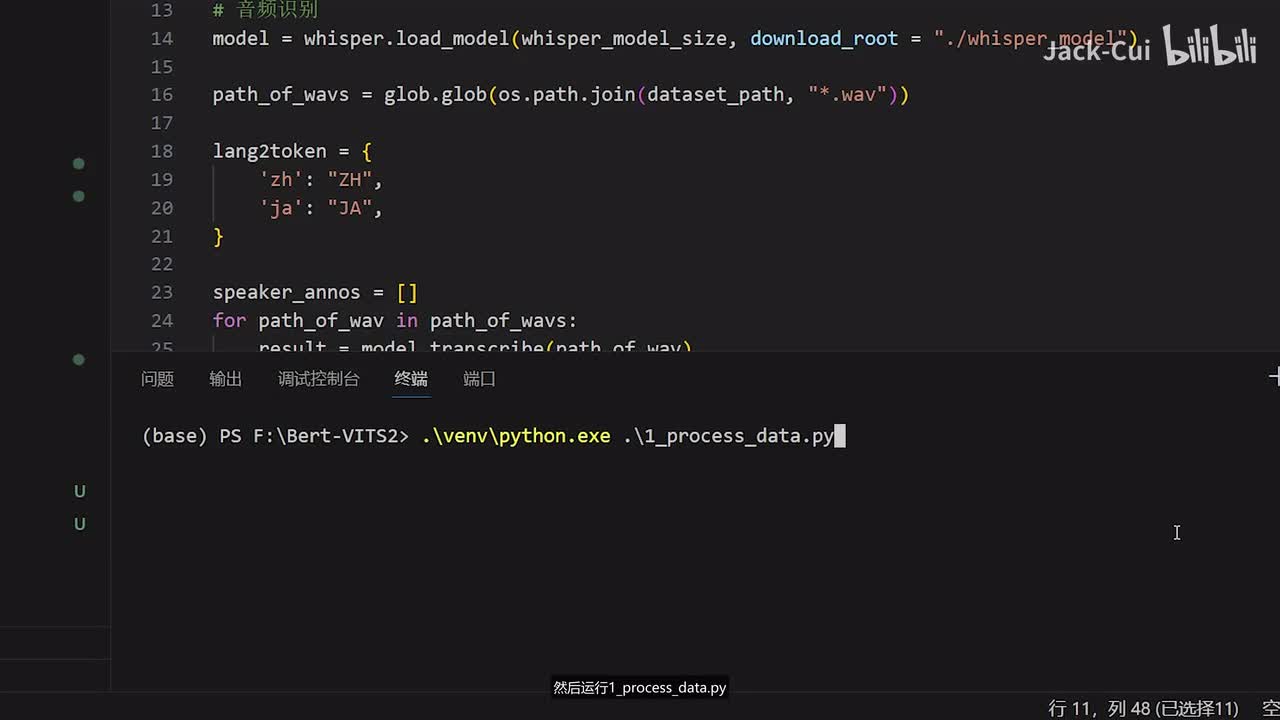
这个save dede就是你处理好的数据要保存到哪里,这里边我就根据我的情况写了,我是放到了f盘,然后bert v i t s two的下面。然后我需要创建一个文件夹,这个文件夹的名字叫design,我改改dede row。然后这样的话就是把数据处理好的数据存储到这里,然后我们运行一下。运行的方法呢是使用我这里面已经打包好的一个环境,选择我们的python,然后运行一这个process state,点击回车可以看到一下监控。还有个显存占用占用到十五g就是说这个large的模型呢它会占用十五g的显存进行一个音频识别。如果大家的显存不够的话,可以选择更小的,比如说medium啊,medium会占用大概八g左右的一个显存,如果是显存更小的话,就得选择更小的模型。打开这个decide roll可以看到音频已经正在处理了。
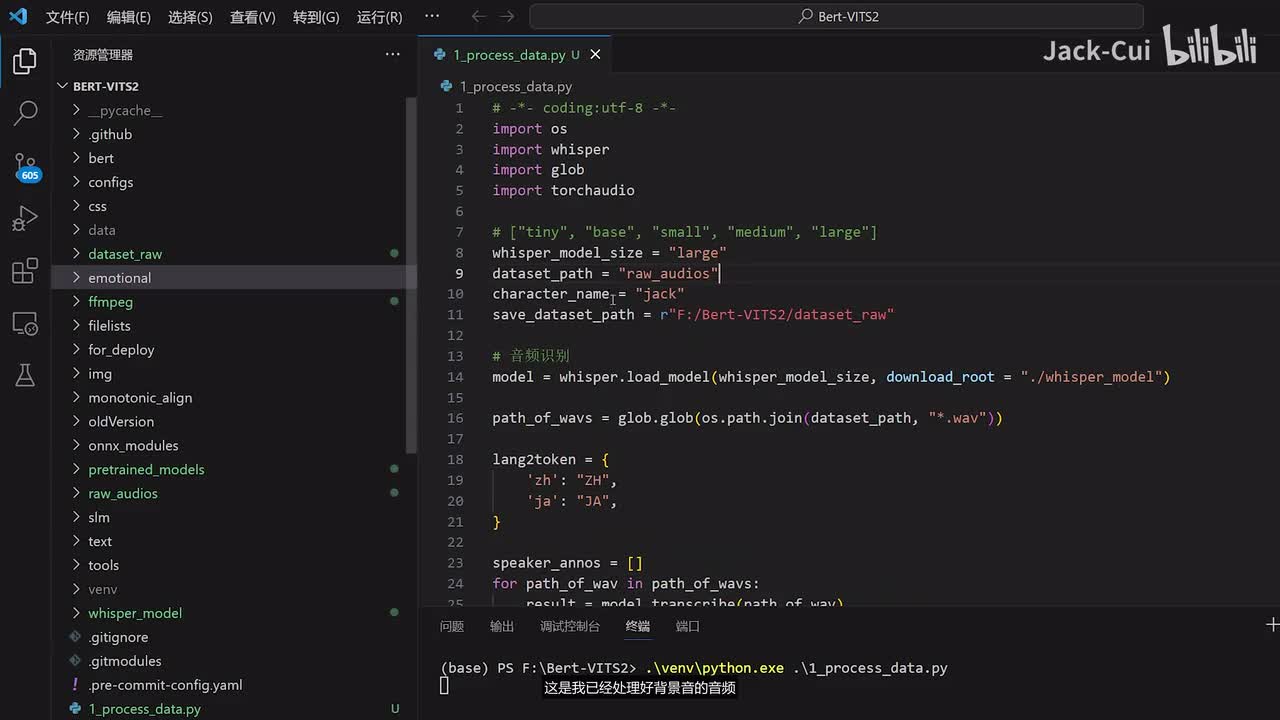
它里面有原始的一个w a v格式的数据,还有一个是这种lab。格式的数据,这里边存储的就是一个识别的结果。啊,每个都是对应音频的识别结果。它这里面代码呢其实就是把所有的一个长段的音频进行一个切分,切分成各个小段的。啊,这是我已经处理好背景音的音频,如果你的音频还有背景音,那么你可以参考我之前的视频,对这个音频进行一个区域背景音。现在音频数据已经处理完了,在field list里边可以找到这个speaker list,这里面存储的就是我们处理好后的一个音频啊,一共是一千二百条的一个数据。我们把这一部分的数据再进行下一步的处理。
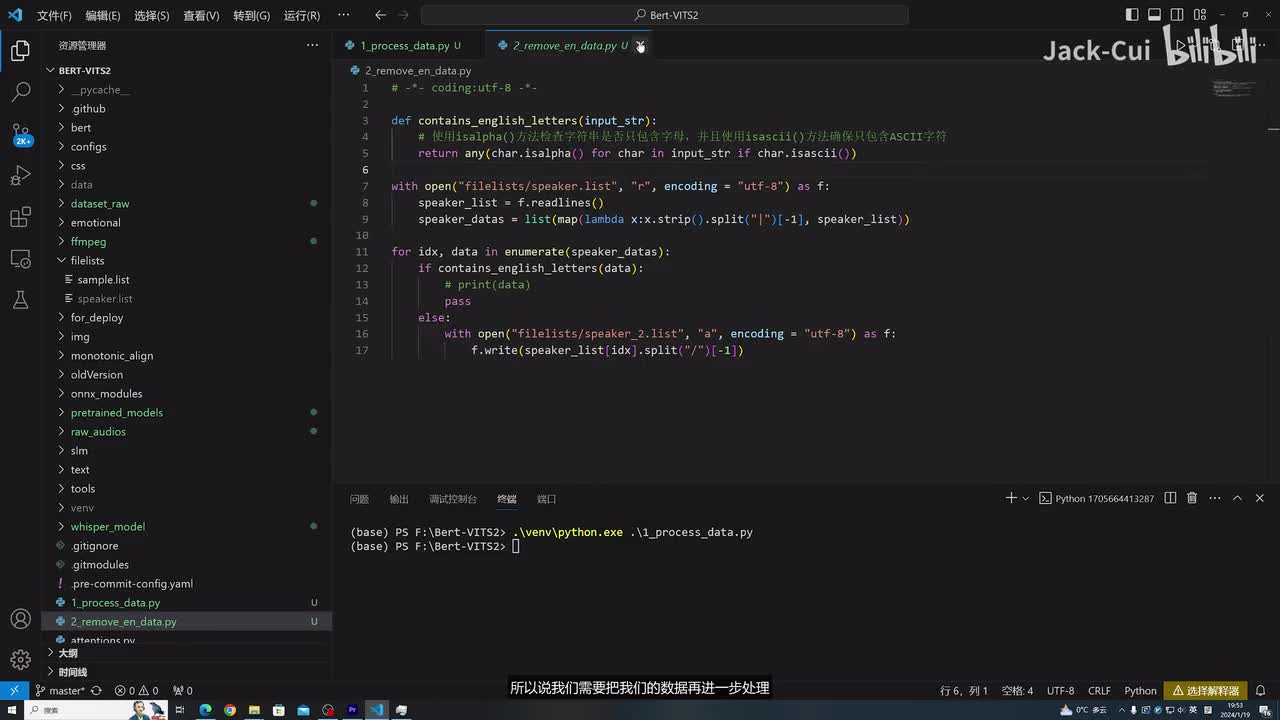
就是需要去掉它对应的一个英文。因为现在这个模型呢,我训练的模型呢是只能训练成英文的模型。就是这里面如果是有中文和英文和呃混合的,那么我们只能一个一个训练。就是说我们先一次只能训练成英文的,或者是只能训练练成英文的,用的时候可以是合并着去用啊,但是不能说这一个模模型有能英文的英文英文啊,所以说我们需要把我们的数据再进一步处理。因为现在的话直接。说的话还夹杂着各种英文啊,什么b站啊、a i啊,这些都是无法呃无法处理的。我们在运行第二个这个脚本,还是使用我打包好的这个一个环境,python点e x c选择这个第二个remove啊,处理音频数据,选择回车啊,这个处理很快在这个full list里边生成了第二个这个list文件。
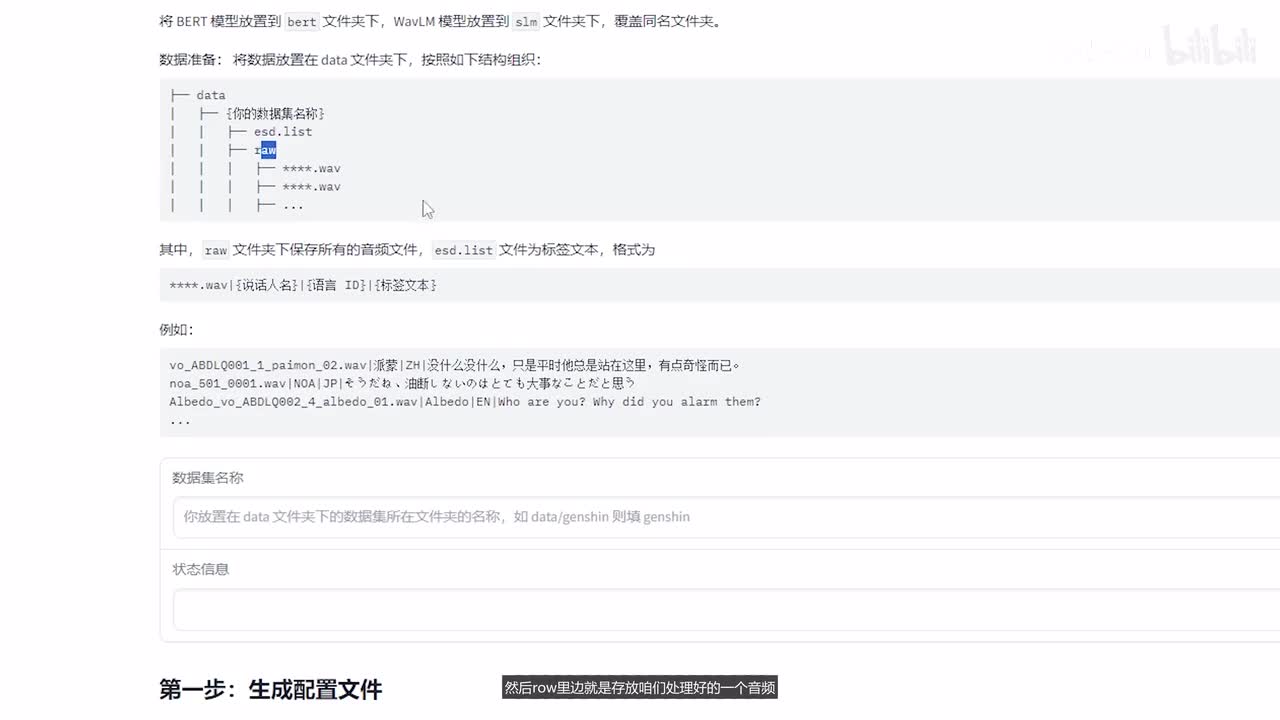
这里可以看到它就没有英文了啊,全是中文的一个数据啊,这部分数据我们就可以拿来进行一个训练了。我们使用这个web u process点p y啊,我们还是使用这个环境,然后是这个python,然后web u i process打开这个o k环境就打开了。可以看到它数据的一个结构是这样的啊,需要是这个目录下,然后是你的数据集名字,然后还有这个e s d点list,然后roll里边就是存放咱们处理好的一个音频。我们按照这个格式去整理一下数据,先在date里面创建一个你的数据集的一个名字啊,我们就叫jack。我们再把我们的list拷贝进来,就是这个speaker这个处理好的数数据我们拷贝进来。feel list, 然后这个拷贝到date下的。jack下的这个里面,然后给他改个名字叫。
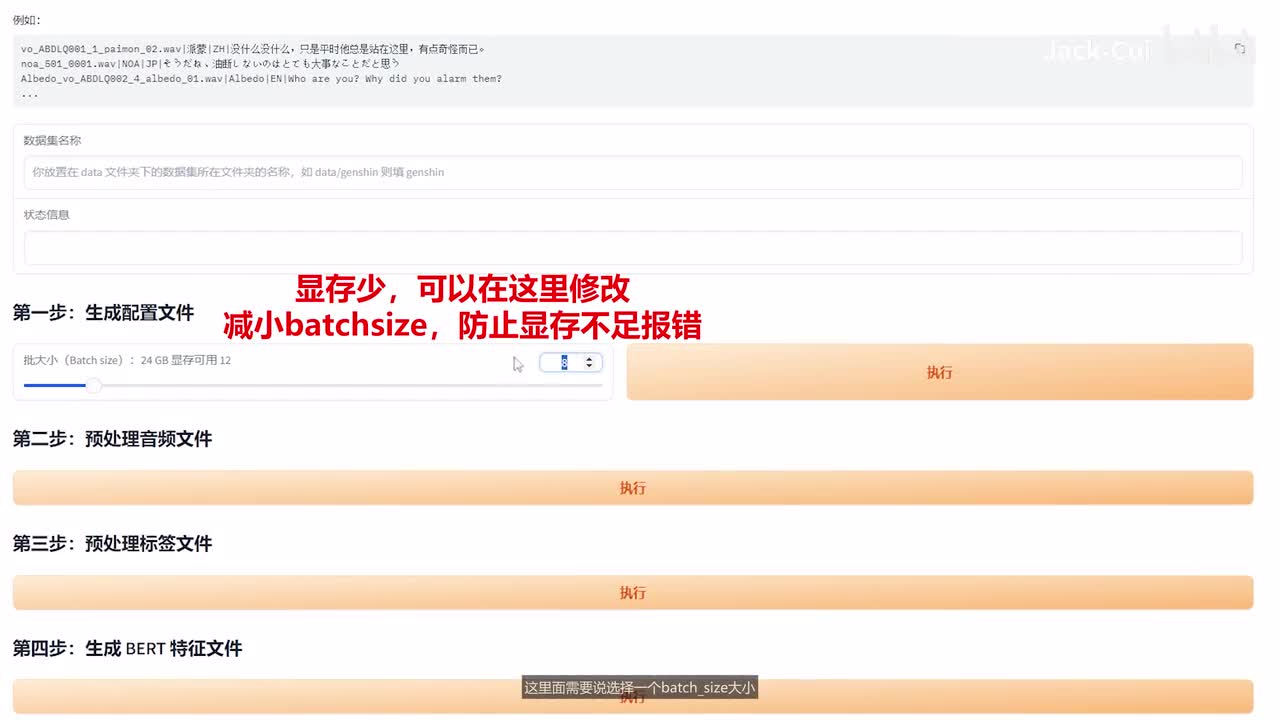
e s d list创建一个role。放我们的原始音频,那就是把这里的数据啊,处理好的数据全部拷贝过来。o k这样就好了啊。其实如果你是在第一步生成的时候,也可以写到对应的目录下。再往下看,这里边需要说选择一个batch,在大小这里边设置为十二,选输入你的文件夹名,那我这里边叫jack,点击执行可以看到配置文件生成了,这个就是我们的配置文件。配置文件需要修改一下数据集的这个地址,这里边写data到我们的jack。因为刚才我们创建的目录就是放到这里了嘛,后面需要改的话就是一些配置,config的配置,这里边需要改成config。
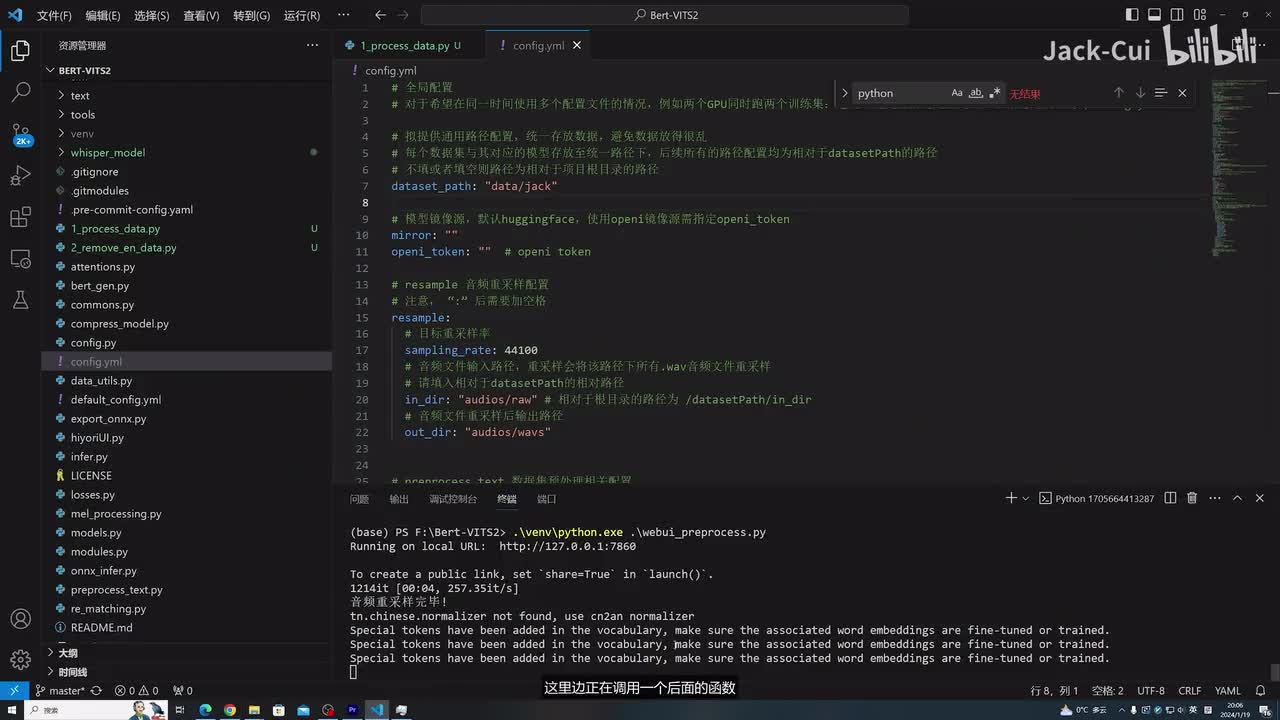
前面加一个conflicts,下边也是同理。然后一直往下全是变成。config config jason. o k这样就都改好了改好后我们点击第二步运行预处理音频文件,可以看到现在正在处理呢,音频采样完毕,然后我们再运行下一步预处理标签文件啊。第三步,这里边正在调用一个后面的函数,然后进行一个处理。o k数据集已经切分完了,然后我们再运行。第四步,生成bird特征文件,这是后台的一个输出情况啊。可以看到这边不仅有w a v格式的数据,还有bird点p t啊,这是已经处理好后的一个音频文件啊,这样它就已经处理好我们的音频了,我们就可以用来进行一个训练。
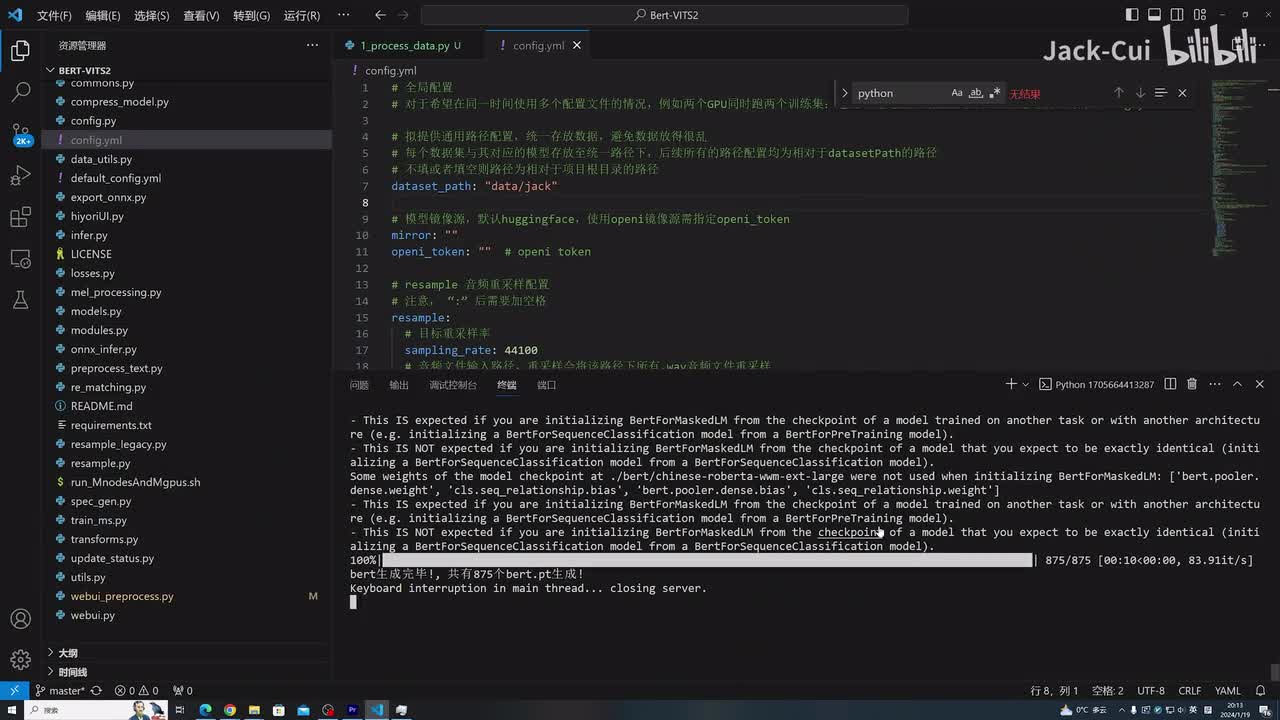
我们接着往下看,这里说需要把预训练模型保存到data目录下。这里边我准备好了对应的一个预训练模型啊,就是在这个pretrail de models目录下,我们给它拷贝过来,还有data jack。models目录下把这个预训练模型拷贝进来,这里告诉我们使用它们进行运行。其实不用啊,我们直接用python就可以跑了啊,这里面关掉了我们的窗口,然后我们还是使用这个python train m s点p y啊,我们选选择回车。哦,报错了啊,这里面其实写错了,应该写成can fix。我们需要把这里改成config加个s那我们把所有的config配置文件全改改一下。这名字写错了啊。
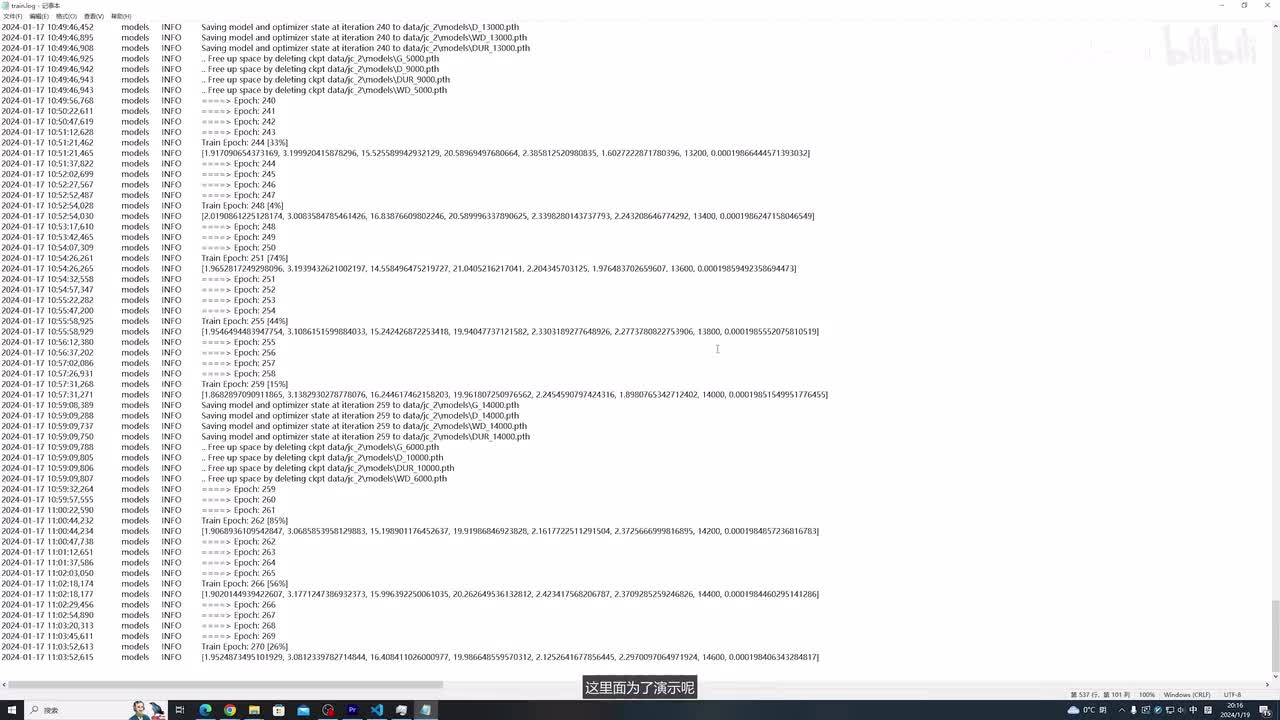
o k这样就好了,然后我们再重新运行。这样啊模型就起来了,这是目前的一个显存占用情况啊,大概占用了十六g的显存,训练大概需要花费三到四个小时。啊,这里面给大家看一下我之前训练的一个loss。最终是训练到一万四千,然后这个可以直接看它的一个效果。我把我之前训练好的这个模型拷贝进来。这里面为了演示呢,我就不再浪费三四个小时的时间等待了啊,我直接把我已经训练好的模型拷贝过来啊,这三个文件来拷贝过来,这是当做我们已经训练好的。然后我们把这个停掉,然后改配置文件,还是这个配置文件里面的这个模型的名字,需要把这个八千改为一万四,然后我们再运行web u i这个文件,还是使用这个已经打包好的环境,然后python点e x c,然后web u i。
好了,废话不多说,直接进入正题。如果你有任何问题,欢迎在评论区里留言,这次我在线解答。这里边还有一些参数可以调啊,大家可以自己试一试。就包括一些停顿,包括一个语速的快慢。比如我快一点。如果你有任何问题,欢迎在评论区里留言,这次我在线解答。o k啊就是大概就是这样。
接下来演示一下g p d s o v i t s的一个训练过程。我们打开我们的v s code,然后找到我们的根目录,找到我们的文件。ok这样就打开了,我们还是使用我已经打包好的这个环境。然后运行这个web u i页面,哎,这样环境就打开了。这边我还是拷贝一个音频放到raw audio里边,这就是我要训练的一个音频数据,可以听一下啊。hello大家好,我是jack。如果你有背景音的话,还有一些伴奏的话,可以选择这个u v r五啊进行一个音频分离。
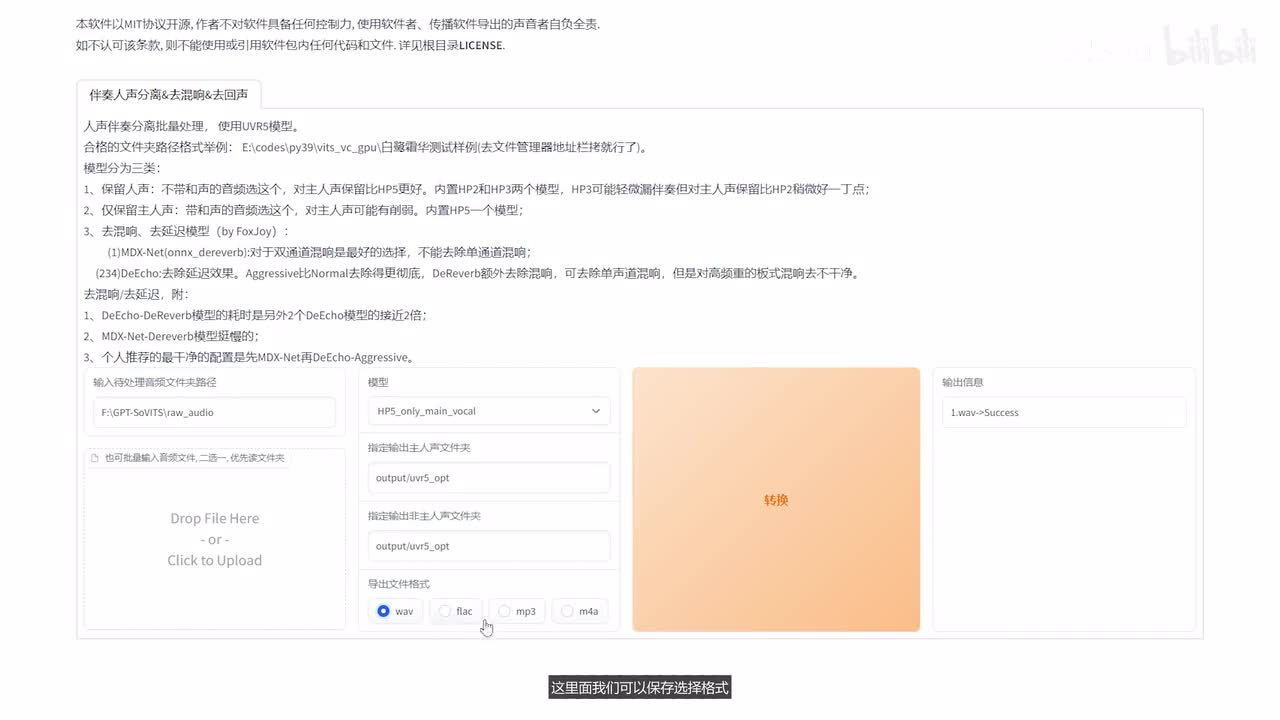
我们点击这里,然后它就会在后台启动这个服务,它会自动弹出窗口,然后我们输入我们的音频目录。拷贝过来选择模型,这里边选择只要人声选择转换,可以看到它就把保存是保存output下面。然后在这个对应的目录下啊,可以看到音频就处理好了。这里边我们可以保存选择格式,这里面我可以选择w a v,你可以再转一下看一下。w a v格式就有了,那我们只要w a v的啊,这是干声,这是背景音。我们把背景音去掉,直接删掉就可以了。然后这个页面关掉,我们接着再进行一个音频切分,然后输入我们这个音频切分的一个路径,就是这个原始的文件夹。
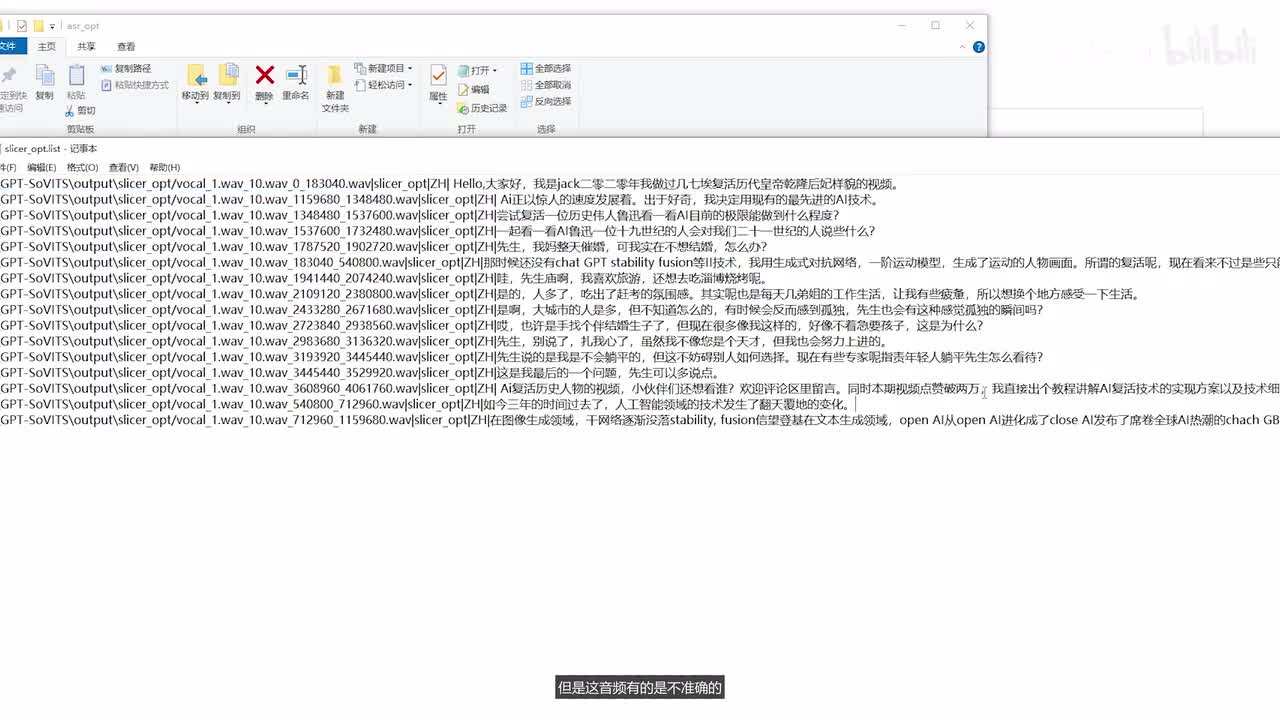
我们可以选择输入这个,然后选择直接开启音频切割。可以看到它会放到这个目录下,然后它把我们的音频进行一个切分,这样就切分好了,然后再继续,就相当于它是一个给标注的一个过程。我们还是输入我们的路径,这是我们的路径选择执行o k后台就开始调用对应的模块,然后进行一个音频识别。这里就是识别好后的音频,但是这音频有的是不准确的,我们需要进行一个人工的一个校对,我们输入这个list那个目录的一个地址,然后选择开启打标,这样标注页面就出来了。我们把含有英文的数据去掉啊,因为我这里边都是夹杂着英文去说的,然后就是这个部分。的数据不要我们给它处理一下,然后选择这个delete o k英英文去掉了,这样我们再看一下我们这个数据是否准确。哇,先生庙啊,我喜欢旅游,还想去吃淄博烧烤呢。
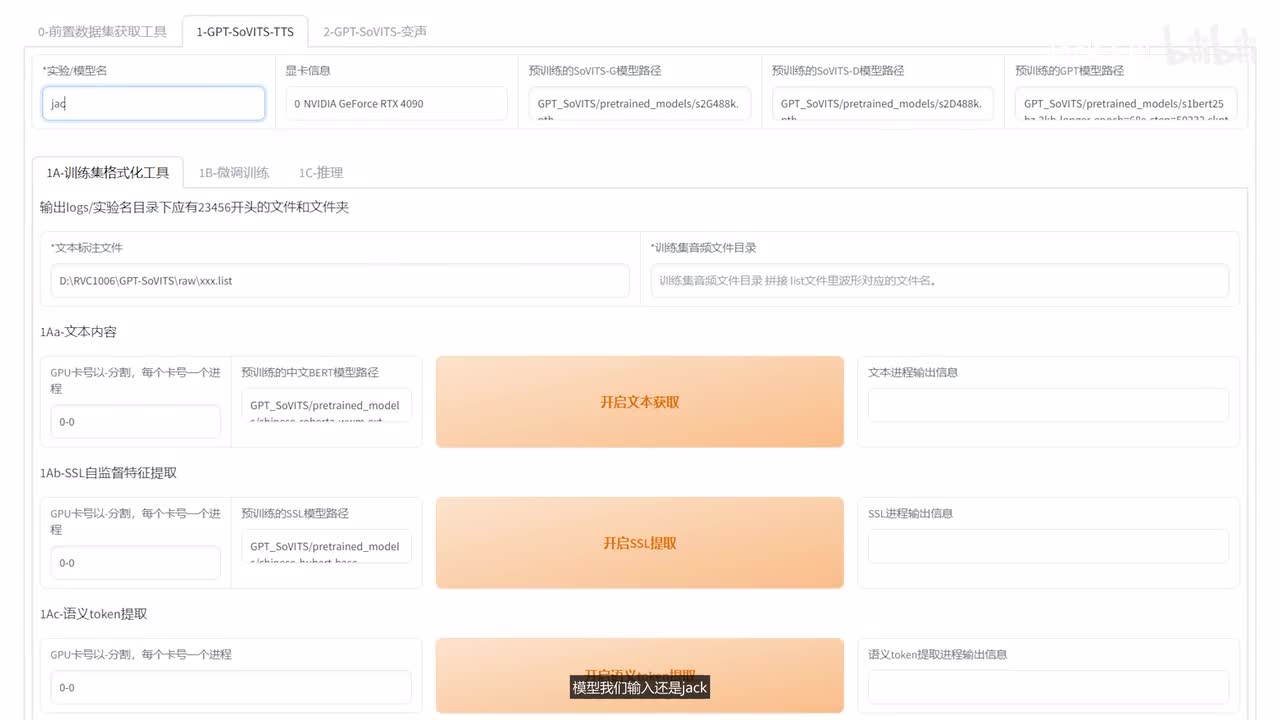
对这种错误的啊数据可以直接给它手动改一下啊,这里边我就不做过多的修改了。大家如果处理了自己的数据,可以全部过一遍啊,基本上一共十条数据就能训练一个不错的模型了。处理好后我们选择提交,我们再打开这个list就可以看到已经正式处理好后的数据了。然后我们进行下一步啊,把这个勾选掉模型我们输入还是jack这里边的标注文件,标注文件啊,在这里我们输入我们的对应的路径。然后这是训练音频文件目录。在这个已经处理好后的切分好后的数据下,然后点击这个开启一键三连啊,就是进行一串的处理。一键三连进程结束,我们找到我们对应的logs目录下,就是我们处理好后的数据。
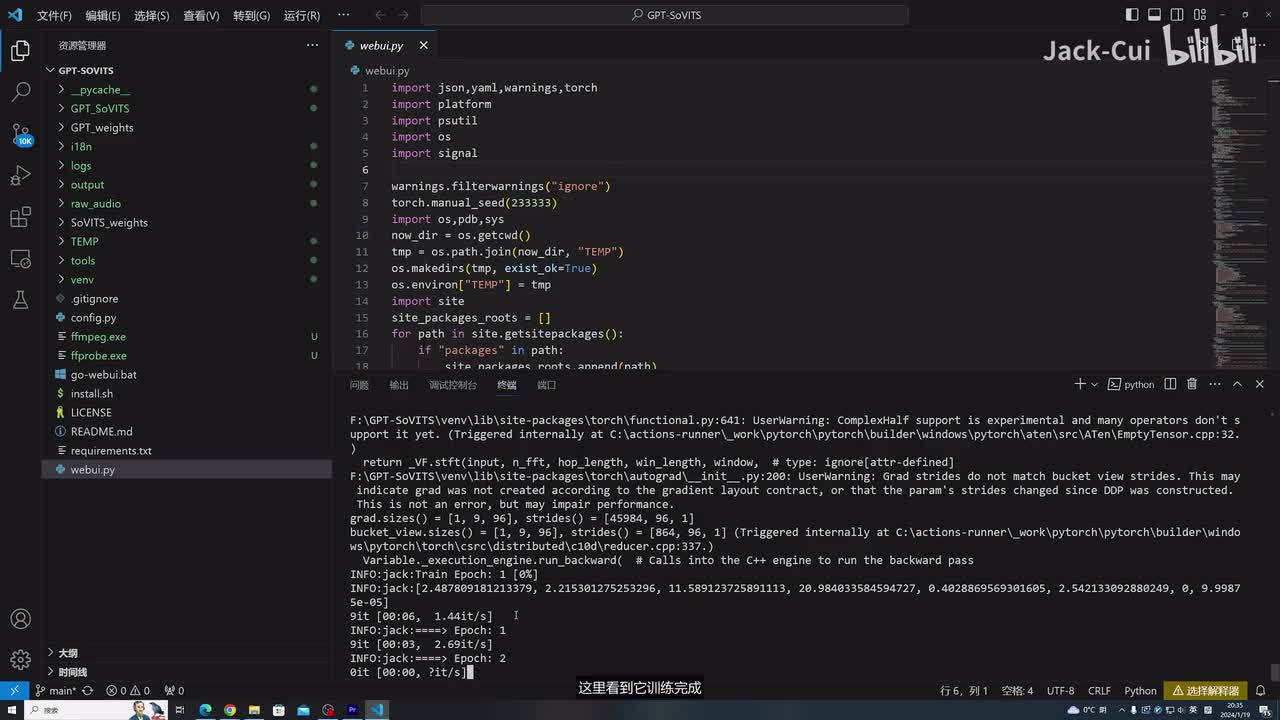
如果没有问题啊,这个每个目录下都会有文件啊,这几个目录下都会有文件啊,然后这样数据就处理好了,然后我们再进行一个微调训练。这里边选择我轮次就选择十五,然后开启训练。这个训练速度还是很快的,大概几分钟就能训练完成。这里看到它训练完成,我们接着往下训练,点击开启g p t训练。其实它就是一个微调的过程啊,微调很快,可以看到的速度非常快啊。我这里边没有加速,它是正常的速度啊。训练完了啊,总共其实整个训练过程大概五六分钟啊,就整个全跑完了。
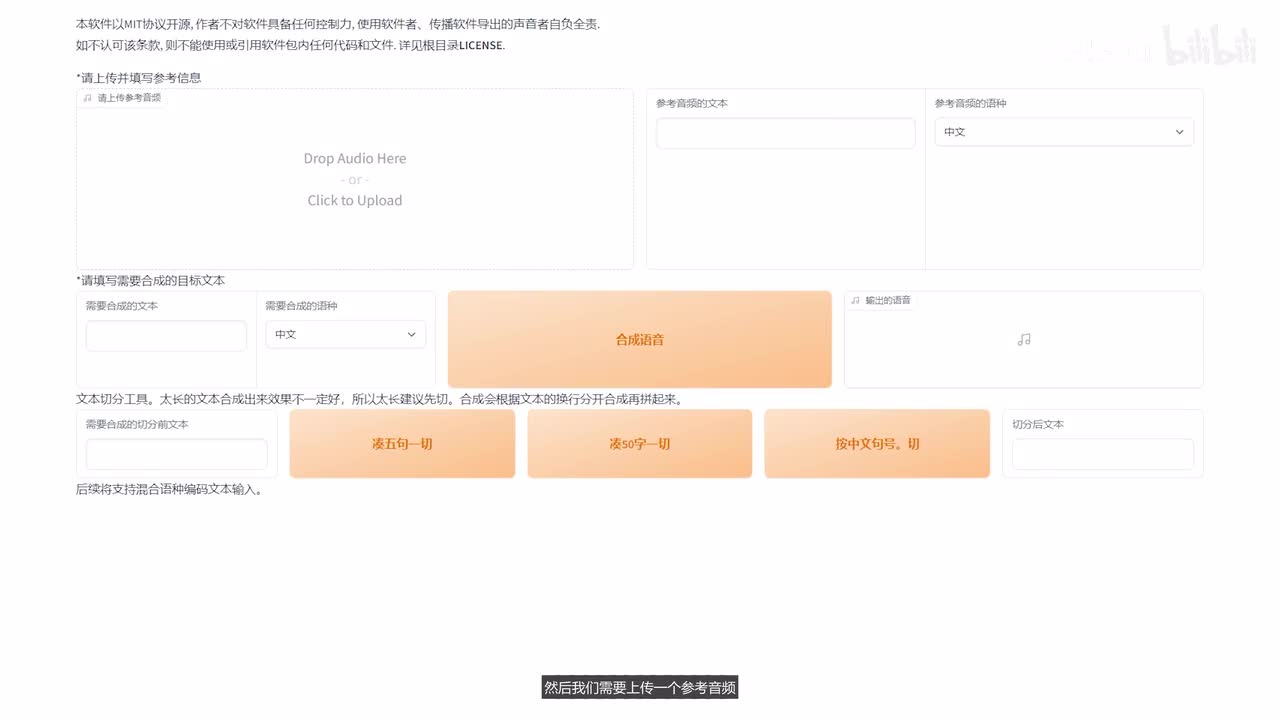
微调完了我们看一下微调后的一个效果,这边没有训练好的模型,我们选择刷新。然后就可以看到我们训练好的模型了。选择这个一十五,然后选择这个你就挑数最大的啊,然后点击这个开启t t s推理o k web u i就打开了。然后我们需要上传一个参考音频,因为这个声音t t s需要有一个参考音频进行一个生成。这个是跟bert v i t s two的一个区别。我们把这个一七几的这个音频进行一个上传,上传到这里。先生,我妈整天催婚。
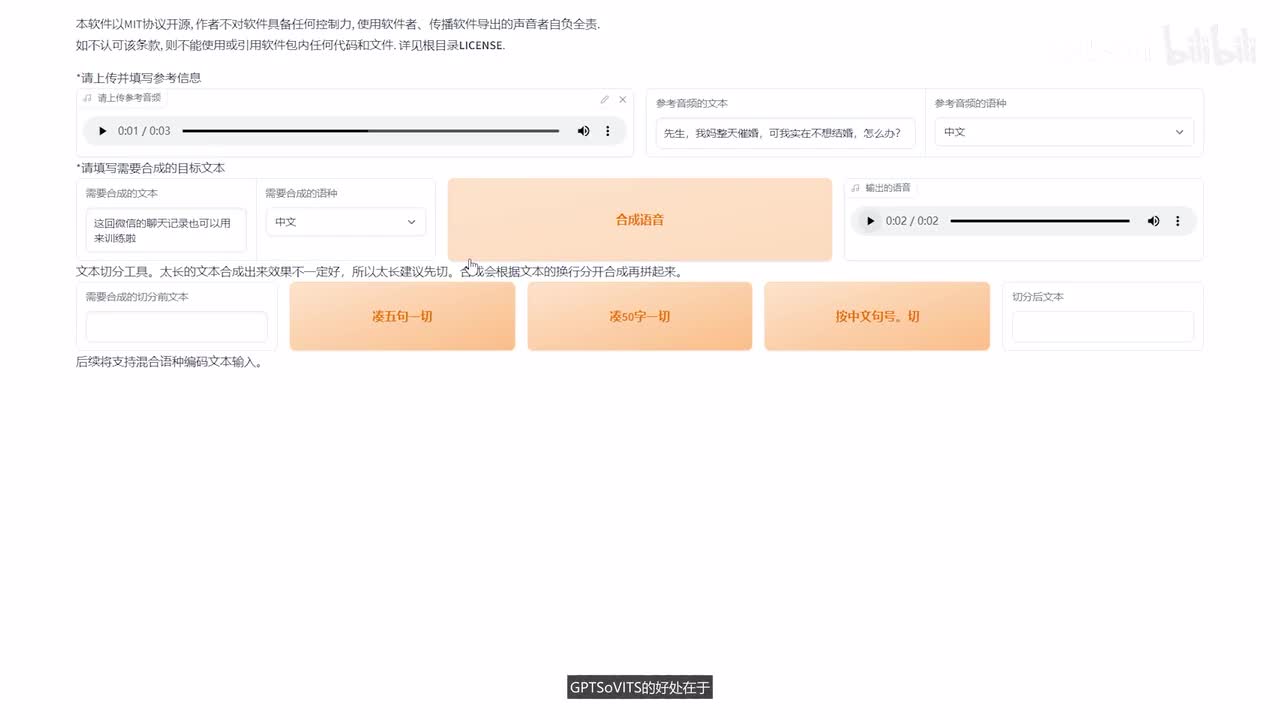
然后把我对应的文本拷贝到这里,然后我们再输入我们想要生成的音频。大家好,这个声音训练的怎么样?这回微信的聊天记录也可以用来训练了,基本上就是这么一个效果。g p d s o v i t s的好处在于啊,它只要需要少量的数据,也能训练出一个不错的音色。我试了一些小姐姐的一个音频啊,效果非常不错啊。我这里边就不展示了,留着自己欣赏了。大家可以自己尝试一下。大家可以根据自己的需求决定选择bird v i t二还是g p d s o v i t s,效果都挺不错的。

如果你有任何问题,欢迎在评论区里留言,这次我在线解答,争取大家都能跑起来。好了,我是热爱技术分享的jack,我们下期见,拜拜。




