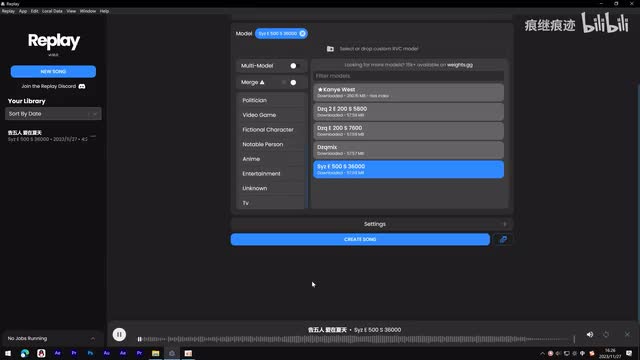
这个软件可以让你一键制作ai翻唱,只需要随便拖入一首歌,然后选择喜欢的模型,最后这么点一下,ai翻唱就全自动完成了,是不是非常简单,它就落在我心上。撑着一把伞。就站在我梦庞那这个软件叫replay,大家可以去这里下载,支持windows和macos,目前是完全免费的。以后我也不知道,但别管这么多用就是了。
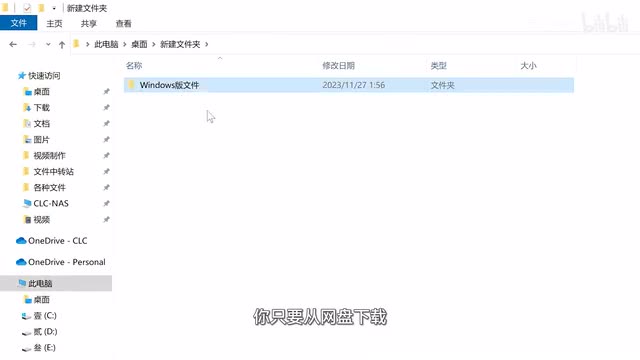
安装完成后,它要先下载一些运行文件,如果你的网络条件不太好的话,可能要等很久。因此我也为大家准备了需要的文件。你只要从网盘下载,然后打开资源管理器,在这里输入这串内容后回车,再把解压出来的文件夹放进来就好了。macos用户需要打开访达,然后选择前往,前往文件夹,输入这串内容后回车,同样把这个文件夹放进来就行。
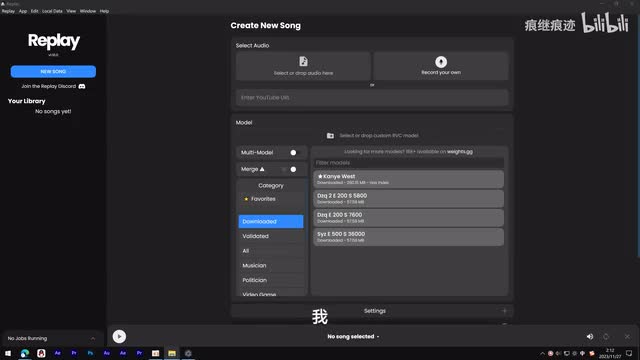
那打开之后我们可以看到哇,全英文的界面真的是一目了然啊,看都看不懂。哎,别害怕,其实特别简单。虽然我知道我说这句话的时候,肯定也有弹幕会说一点都不简单,但是你只要跟着我做就好了。那最上面这里你可以直接上传一首歌,这首歌你不需要做任何处理,放进来就完事儿了。
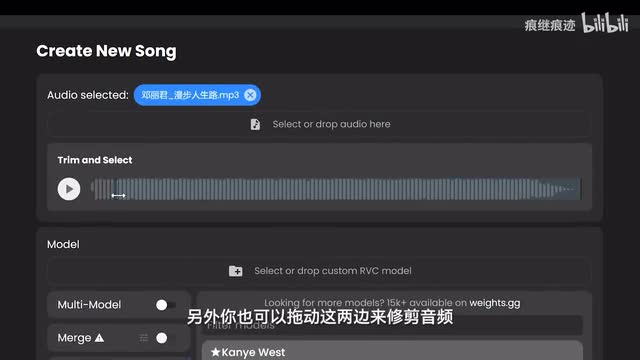
因为replay会自动帮你分离人声。和伴奏。那如果你对自己的唱功比较自信啊,也可以点旁边的录制来高歌一曲,唱完之后点这个保存就行。另外你也可以拖动这两边来修剪音频,先挑一小段听听,效果好的话再处理整首歌,或者也可以打开设置里的sample mode,设置的具体内容后面会讲。
接着就是选模型了,你可以从列表里选择下载。但这些基本都是国外的,我也不太认识,所以说你可能得自己准备一些模型。因为它用的就是r v c模型啊,因此你可以自己来训练,然后把你的模型文件拖进来。r v c的训练在b站上有不少教程,也有整合包。
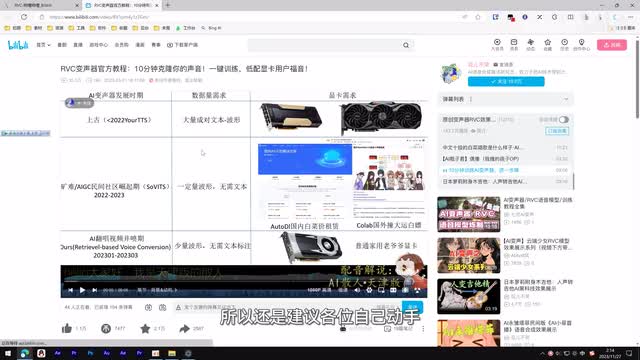
相比于我之前说的那个sobs,i v c对数据和电脑硬件的要求都要更低一点,训练速度也要快不少。如果你懒得训练,也可以去网上找别人分享的模型。但这个东西说实话真的不行,所以还是建议各位自己动手丰衣足食啊啊选择模型之后,直接以这个crosson就完事儿了,然后你可以自己的等待就行。因此简单来说三步就可以完成a i翻唱上传歌曲选择模型,点击开始是不是特别特别简单。
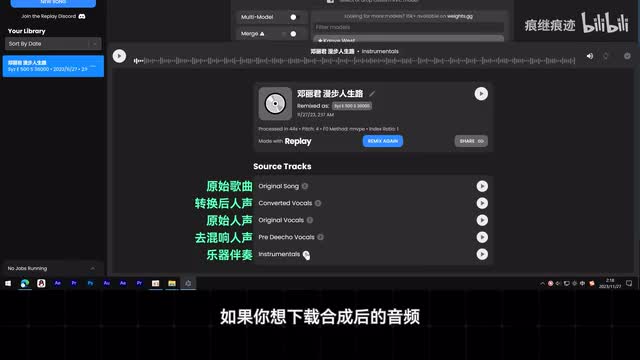
那转换完成后就可以在这里听到效果了。点击这里可以看到不同的模型,你可以点击播放播播放或者这里的的是你你可以在这播播的音频,可以在左边这里点download。打开这个verty model,还可以一次选多个模型,然后在播放界面这里就能看到多个结果。你甚至还可以打开merge,然后就能把不同的声音混合在一起,获得一个全新的声音。
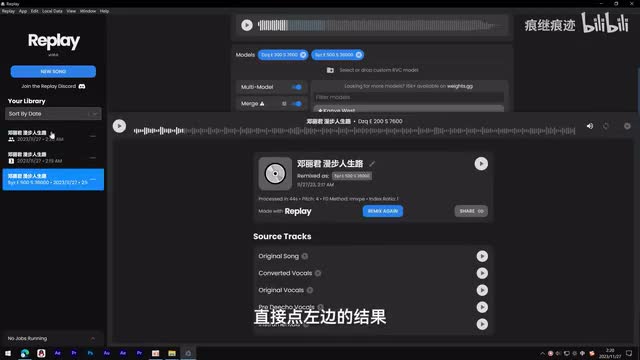
点开这里可以调整不同声音的混合比例,算是一个很有趣的功能了。需要注意的一点就是直接点左边的结果是不会切换这里正在播放的音频的。你需要点击这里的播放按钮才会替换上面播放的音频。那以上就是最主要的内容了。
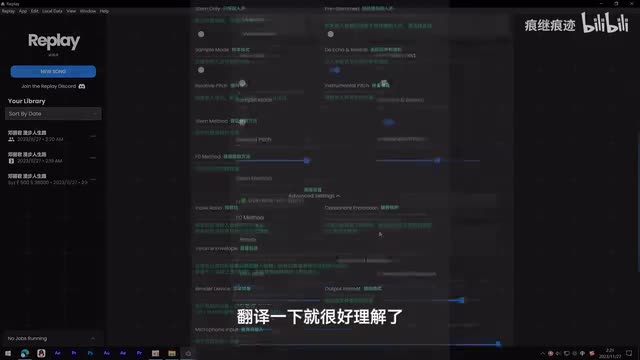
但是你看这里有个设置啊,点开还有个高级设置。哎,这里内容就比较多了,有些还挺重要的。不过也很简单,翻译一下就很好理解了啊,我只讲一些比较重要的选项。虽然only开启之后会跳过转换声音的步骤,只进行人声和伴奏的分离。
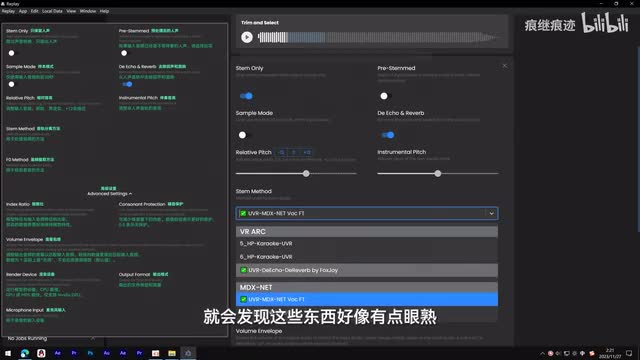
这时候replay就成了一个伴奏提取工具。如果你往下面这里瞅一眼就会发现哎这些东西好像有点眼熟。没错,就是u v r五里的那些模型。因此这个replay也可以说是特别简易版u v r五这个press steam的。
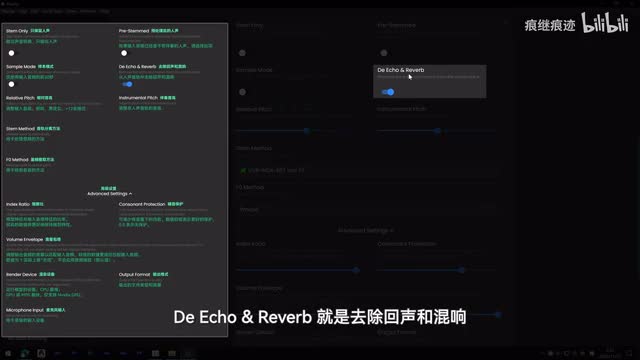
开启之后就会跳过分离人声伴奏的阶段,直接进行人声转换。如果你输入的音频是干净的人声,那就开启它,否则就别开了,不然合成出来的效果会很差的。the echo and reverb就是去除回声和混响,因为很多歌曲在后期混音的时候会加上这样的混响,去除之后对于转换的效果会有所提升。同样在r v c训练时也建议先去除一下回声和混响。
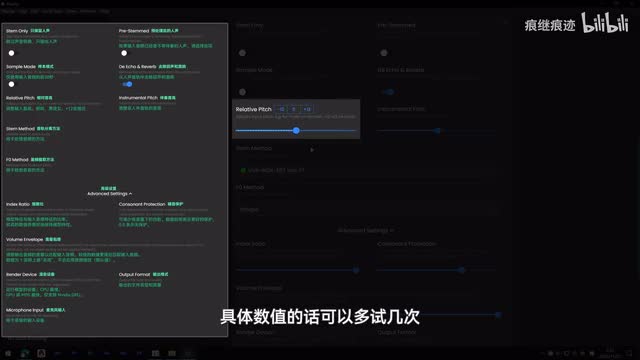
relative page是用来调整人声音高的,比如男声转女声,你就把它调高。女生转男声调,调节具体数值的话可以多试几次。高级设置里你可以调整一下v u e l o b,降低该数值可以让转。换后人声的音量和原始人声音量尽可能接近。
渲染设备能选库塔肯定选它,速度要快很多,不行的话就只能用c p u慢慢来了。麦克风输入这里会自动选系统默认的那个,如果没法录音,可以来这里检查一下麦克风设置。那么以上就是这个软件比较重要的内容了,还是很好理解的对吧?相比于你自己分离伴奏,然后转换音色,然后再混合人声与伴奏要方便很多了。那所有的下载链接你只要点个伴奏就能看到了。
嗯,其实不点也能看到,那还是点一下吧。那好了,以上就是本期视频的全部内容了。如果喜欢的话不要忘了点关注,你可以长按点赞一键三连,我们下期再见,拜拜。




