
a i懂得猜声音了,还开源免费。
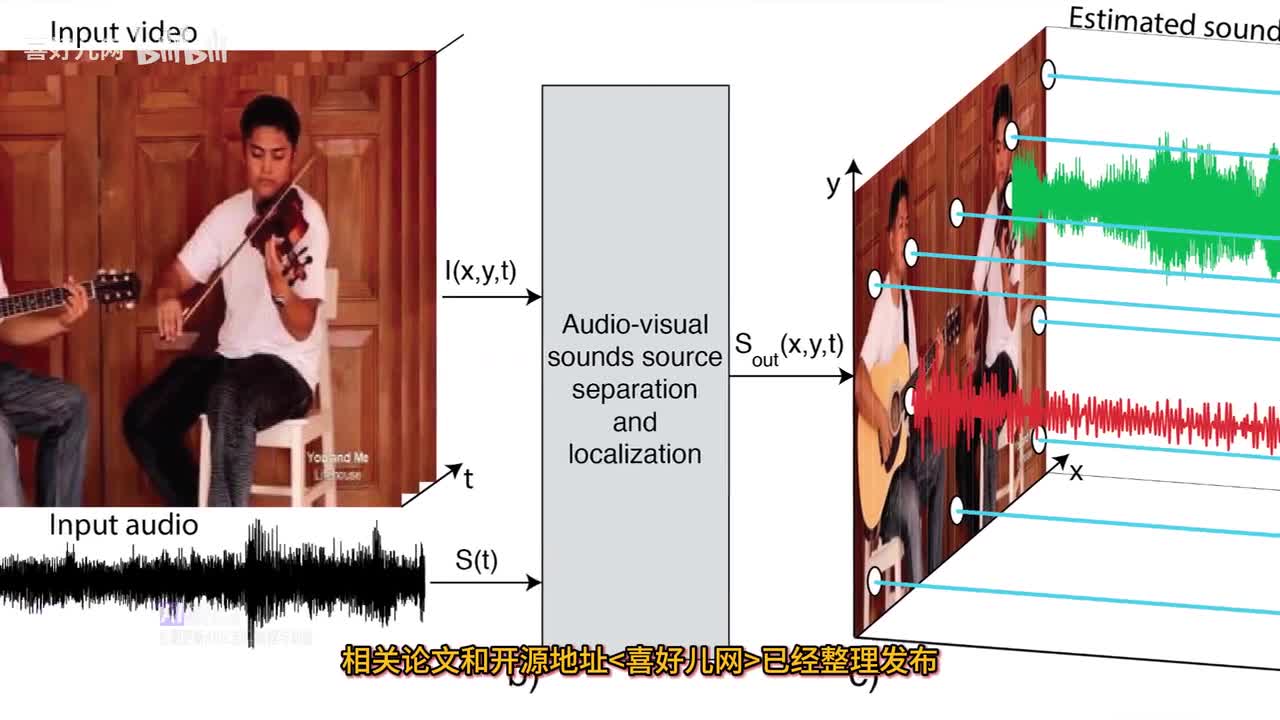
这个开源模型可以说是视听界的黑马,它通过看视频就能让图像区域产生声音,并且能够分离音轨。
相关论文和开源地址喜好儿网已经整理发布,感兴趣的朋友可以去看看哦。

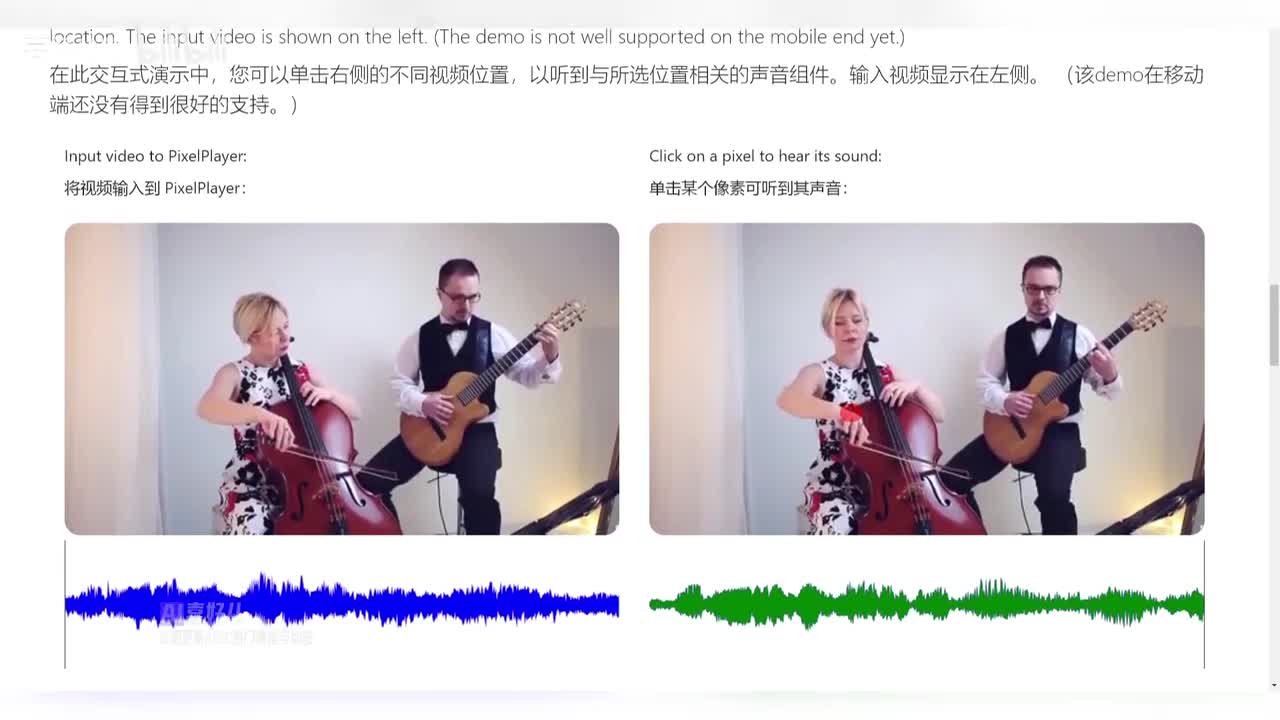
该模型通过观看大量未标记的视频,自动学习如何定位图像区域产生声音。

例如你在看一个乐器演奏的视频,这个系统就能把声音信号分成多个声道,每个声道对应不同的乐器类别。

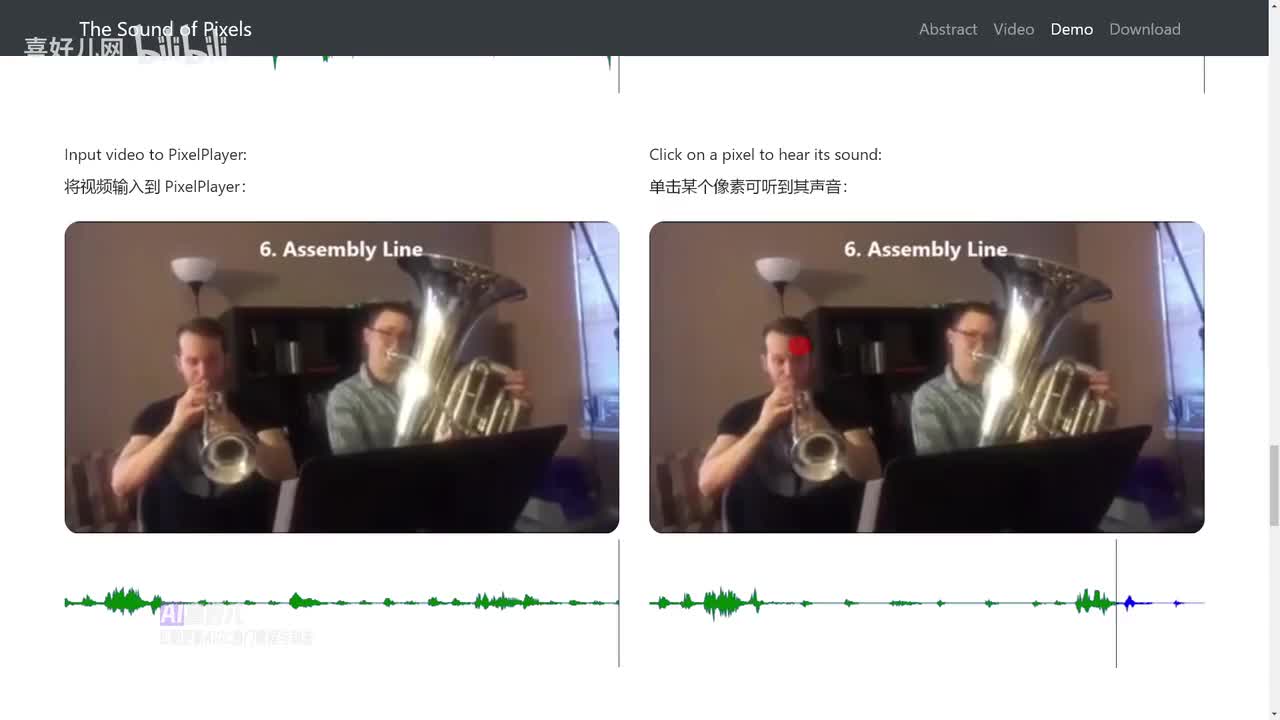
同时它还能为每个像素分配不同的音频波,让你听到视频中的每一个细节。
嗯。

简而言之,就是让视频中的每个像素都开口说话,就是不知道是否演奏的是同一首歌。
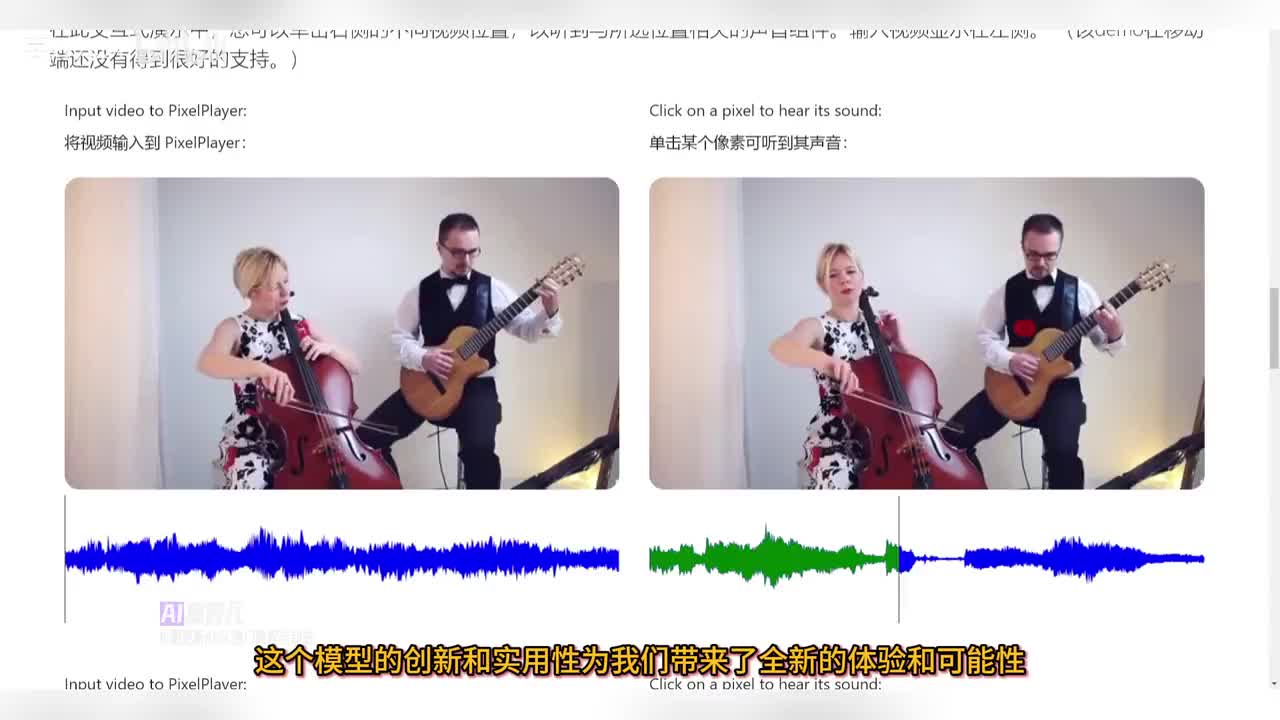
这个模型的创新和实用性为我们带来了全新的体验和可能性。

这里是喜好儿网,长期更新热门ai教程与动态,我们一起探索人工智能的新世界吧。




