
被骗了吗?好像又没有你可能已经在很多地方看到过这样的ai动画作品了。什么?a i已经发展到这个地步了,都能做动画了吗?别紧张,这里的ai动画其实泛指一种将视频片段利用a i重制成动画质感的特殊加工手段。而除了二次元风格的动画以外,它还可以实现许多其他不同风格的转会,就像一个自带了各种风格的魔法滤镜一样,让许多视频焕发出了一种独特的魅力。有不少商业级的视频也开始在使用它来为视频带来更多的风格化特色,吸引大家的目光。目前市面上有很多种可以生成类似a i动画效果的软件应用,但目前被使用的最多的应该就是这款被我们讲过无数遍的开源免费功能强大的stability fusion了。没错,从我开始更新这个stable diffusion入门系列课的第一天,就已经有不少朋友在期待一些a i动画的教程了。利用它的图像绘制功能并搭配合适的模型,你可以将一个视频重绘成任何你想要的风格,而结合一些创新的扩展插件,你还可以更轻松的完成操作,且让你的视频更加丝滑流畅。首先,掌握这门技术,你将有机会在ai的帮助下卖出成为一名动画人的。第一步了,在接下来的十五分钟里,我将全方位的为你展示一遍利用a i重绘视频生成动画效果的原理和基本操作方式。

备受欢迎的ai动画扩展movie movie的安装使用方法,结合control net loader等对动画效果进行优化和精确控制的方式,以及absence一个时下公认最为稳定且好用的ai动画生成应用的具体展开方式。课程内容很难也很充实,我建议你先收藏一下再开始学习。准备好,就让我们开始这节课的a i动画之旅吧。你可能会好奇stability version是一款a i绘画的应用,它怎么能做动画呢?其实它的运作原理和我们利用a i生成图像,对图像进行转会是一模一样的。做一个简单的概念科普,它对你一会儿实践操作可能也会有所帮助。我们生活中所能看到的视频动画,其实也是由一张张静止的图片连续播放而成的这里面的每一张图片,我们会把它叫做这个视频的一帧帧和帧率的概念。我做了一些简单的说明,如果你感兴趣可以敲个暂停在这里阅读一下。计算机诞生之前的动画,其实就是依靠动画师一帧一帧的手绘具有连贯性的画面,再拼在一起快速播放实现动画效果的。我们今天做的事情和这个。

过程其实类似。如果你学习过之前的系列课,你就会知道stable diffusion内置的图生图可以帮助你将一张图片重绘成任何一种你想要的风格。这样一个视频变成a i的话,其实本质上就是把它每秒的二十到三十张画面拆开,单独重绘每一张画面,再拼回去变回一个完整的视频。从stability version诞生的第一天起,就有人开始摸索利用它生成动画的种种手段了。从自带的图层图批处理到movie movie扩展,再到诸如多帧渲染absence一类的创新工具。这期视频我想为你系统的把这些方法全部梳理一遍。所以会从最基础也最方便的方式开始讲起这个buff啊。我会建议每一位想要动手操作的朋友,先将视频完整收看一遍,再根据自己的需要从里面挑选合适的手段深入实践。随着时间推移,这里面的一些方法不一定是那个你认为的最佳手段,但掌握了其中的原理,你将能够以更轻松的姿态探索未来的任何一种新方法。
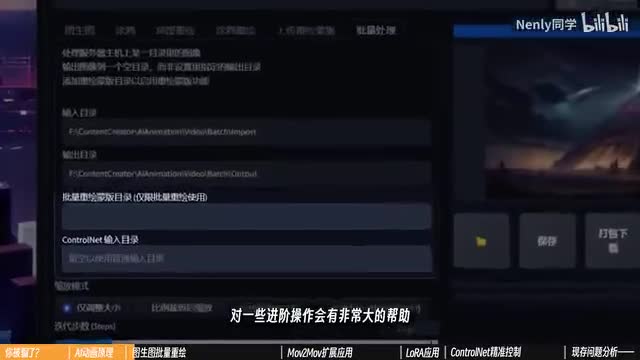
最早期的古法动画是将视频手动拆分,真以后批量图生图重绘。stable diffusion的图生图标签里有。一个自带的图像批处理功能。在这里面你可以选择一个装有图片的文件夹,再设定一个输出图片的文件夹。它就可以对多张图片批量进行图像图操作。下面它还可以批量导入重回蒙版和骨骼图,对一些进阶操作会有非常大的帮助。但我们今天先不聊,这是最为简单且朴素的动画重绘方式。那么怎么用它来制作a i动画呢?如果你会操作premiere等剪辑软件,可以将一个视频导出为一张张的图片序列。但我猜很多朋友确实没接触过,我们争取把所有工作都在web u i里解决。
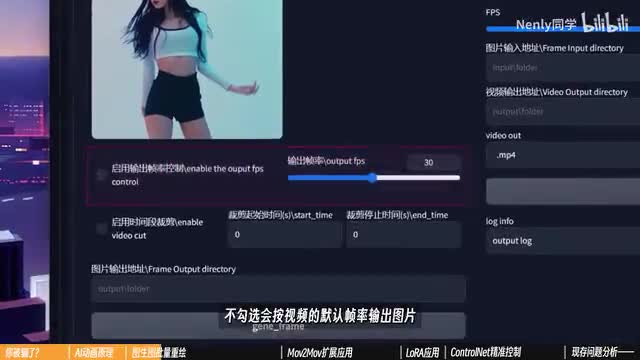
我找到了一个国内开发者制作的web u i扩展,叫做ec net pro。它的链接与扩展文件我已经放在视频简介里了,你可以按照第八课里的方式进行安装。完成以后,你可以在上方打开这个ec net pro的标签页,里面就有一个功能,可以帮你将导入的视频拆分成图图图片变成重绘这个视频放进来就可以了。下面有两个选项,第一个可以用来调节视频的帧率,不勾选会按视频的默认图片输出图片。在电脑上有一个视频属性里的详细信息中,你可以看到它的自带图图片信息现在。这个视频是每秒二十五帧,就是每秒播放二十五张图片。下面的选项则是可以控制裁剪视频里的某一段特定时间比较长的视频可以用这个来裁短。设定好输出文件夹,点生成,你就会把这个视频拆散成单独的帧。按照二十五帧的帧率,它一共被拆成了三百多张图片。
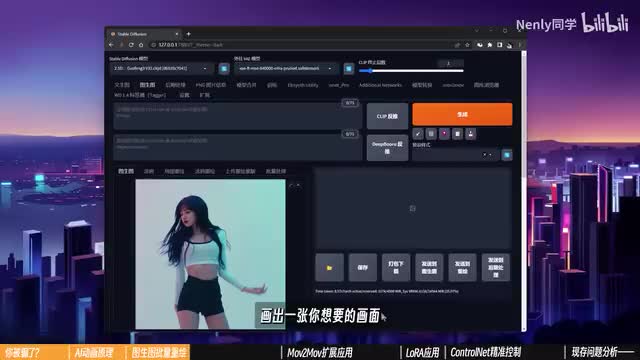
这就是一会儿我们要重画的了。完成以后先别急着开始批量绘制。制作a i动画的时候,我们需要先做一个小的风格测试。具体而言,我们可以切换回正常的图生图,在刚刚的视频片段里挑选一帧比较具有代表性的画面,把它放进来,像进行常规的图生图那样调试模型参数提示词,画出一张你想要的画面。在大模型上,我选择了一个叫做dark sushi mix的模型,它在人物刻画上非常有有表现力。参参数帧大小可以设置成了视频尺寸的一样的比例,重点在于这个重复度度。因为每一帧的画面都不一样,所以这里的图图图的不一样的。一般不超过一点一的,就可能会造成画面的混乱。不一样的,这个也是非非常重要的一环。
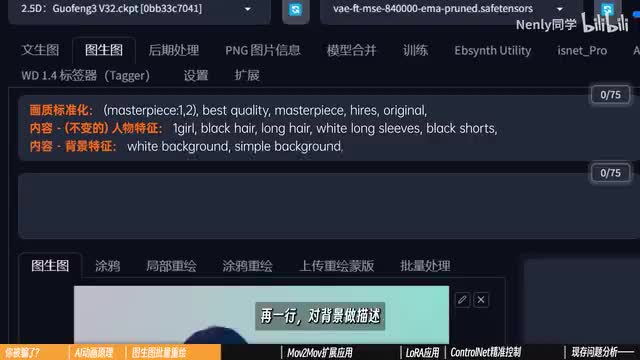
同样。因为前后画面的差异,我们不能给到一个特别固定具体的提示词。因为批处理是针对每一帧的画面进行操作的,这个提示词会被同时带入到每一帧的画面中,描述太具体反而容易南辕北辙。有一个写提示词的框架是你可以参考的。在这种批量重绘的过程里,我一般会用三行提示词来描述画面内容。一行画质的标准化,不用说你也知道,应该有一行人物或者画面主体的具体描述,一般精确到从头到尾都适用的这种外貌特征就够了,这一行对背景做描述,我们这个视频的背景比较干净,就用white simple background描述,这样就差不多了。如果你转会的视频动作幅度较大,我会非常推荐你加入dynamic post一类的提示字,增强动态感,而detailed face则可以确保在半身或全身画面下,人物的脸部不至于太过模糊。点击生成,反复调试,直到得到一张符合你需要的图像度结果。再打开批量处理,用刚介绍过的方法把图片的输入输出文件夹设置好,点击生成,你就可以见证这个批量重绘的过程了。
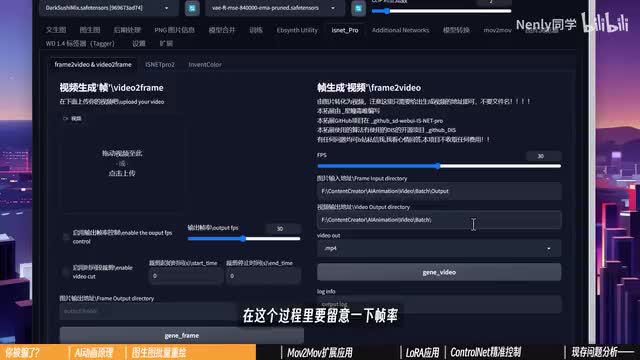
你可以在生成窗口上方看到一个进度条,显示绘制的是。与时间绘制完毕以后,我们就可以到输出文件夹里去验收成果了。在这个案例里,我们花了七分钟左右的时间绘制了三百多张图片。现在他们还是一堆零散的图片而已。但我们可以再到easy nepo里面,除了拆拆sa它可以帮我们把这些图片重组,以图图片地址就填我我们刚刚批处理输出的文件夹。视频的生产产值可以和它一样,可以设置成它的上一级菜单里找找就行。在这个过程里面要留意一下图片,我们视频的一个是二十五,这里就是要保持一致,然后期出来的视频速度会对不上。再点生成,看到完成的提示以后,就可以去文件夹里面的成果了,这就是stability function里采用最简单的方式能够生成出的一个ai动画,你对这个效果满意吗?批处理可以很好的揭示这种a i动画操作的本质。和图生图板块高度整合,除了拆视频以外,基本不需要依赖任何外生扩展,这是它的方便所在。
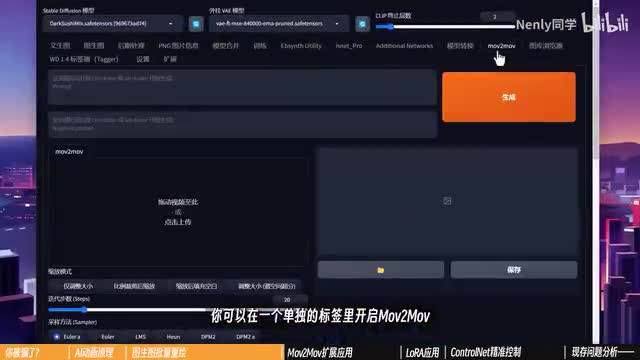
说到这里,如果你对这种反复拆散重组视频的过程感到麻烦,那可以考虑采用一个扩展应用来实现真正的视频到视频的转换。它就是movie to movie。这个过程同样是有。为国人开发者向丁老师开发的。紧接我附上了原发布地址和它的教程视频链接。完成安装以后,你可以在一个单独的标签里开启movie to movie这个界面。所有的设置选项和图形图基本一致,唯一的区别是导入图片变成了导入视频。没错,你可以将一个视频拖拽到这个窗口里,并把刚刚的所有参数提示词直接同步过来。比起图层图,它多了一个可以设置的参数,是这个multiple噪声层数。

这个参数其实我们不常调整,它被藏在设置里的采样器参数中,默认值为一,你可以把它简单理解为输入的重绘幅度乘以这个数,才会得到真实作用的最终重绘幅度。很多ai动画创作者会将它设置为一个很低的数值,以确保稳定性以及产出作品的原视频足够像,但会消除一些a i绘制的风格化因素,且容易造成画面模糊。对于每一个案例最佳的设置参数可能都不一样,但我喜欢设置在零点八到零点九之间,主要通过重绘幅度去调控画面变化程度。下面的movie frame代表程度和刚才一样,保持与原始视频一致。max frame也是一个用来测。是的,小选项设置成负一是不生效。如果你想先跑一小段,看看出来的感觉对不对,就可以设置一个数值。例如这里输入五十,就是先画五十帧,生成一个两秒左右的视频来测试一下。最下面还有一个model net是作者为大家提供的一个清除背景的选项,但似乎需要加载额外模型。
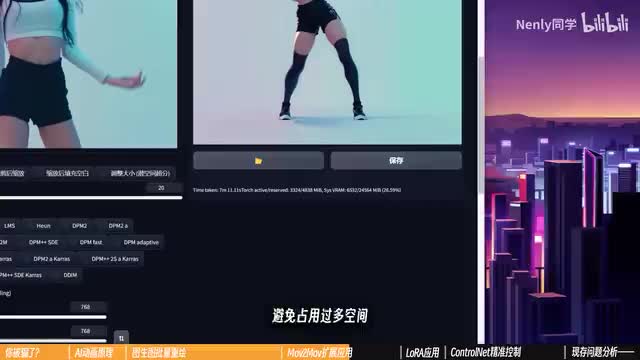
你可以选择使用一些视频的图片,你可以维持默认不开启,把它折叠起来点击生成,它就会像刚刚一样一帧一帧的画画完以后你可以直接在页面上上的这个视频的时间吧。如果你用过movie to movie生成视频,虽然你跟目录下output文件,文件里会额外多出两个属于的产品文件夹。video s s里装着成品视频,可以从这里拷贝出去。旁边的images里装着单帧绘制的图片,它也是经过了这个拆散重组的过程的。如果你对视频满意,且不需要局部调整了,也可以选择直接把里面的图片删掉,避免占用过多空间。在速度上,movies、movie和批处理没有太大区别,有时候它会更长一些,就当是帮我们拆视频组视频化的时间吧。虽然它看上去更方便,但目前阶段拇指movie绘制过程是相对独立于。y b u i原有的图片生成流程的这意味着你只能手动一项项把参数复制粘贴过来,无法直接通过参数读取生成信息,或者借助图库浏览器发送信息。另外他们两个还有一个小小的通病,就是都只能生成画面,无法把音频整合进来,但这一点不难处理,你可以利用任意一款剪辑软件,把它的画面直接叠在原有的视频上,保留音尾部分即可。
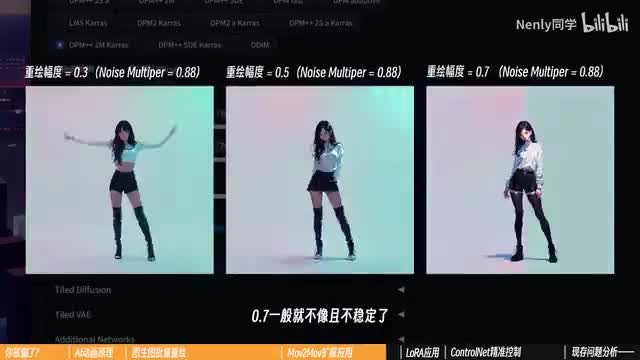
在使用这两种方法生成ai动画时,最应该注意的点就是模型与重绘幅度。首先是模型,在图层图里,模型是决定画风的最大要素,不同模型出来的效果不太一样,这个我们在第四课里已经详细分析过了,重绘幅度的设置没有绝对的正确答案,更多在于一个取舍。如果你追求动画和原视频更像,就可以设置的比较低。但如果想让a i更自由的发挥并保留更多的模型特质,就设置的高一些,但最好不要超过零点五,和图层不一样,零点七一般就不像且不稳定了。以上两点你都可以在测试阶段去确定下来,有时候也需要换几个画面,或者利用刚刚提到的测试几帧来看看它在不同画面上的表现如何。讲到这里你明白一个a i动画。应该如何实现了吗?如果你学会了,请在弹幕扣一个一。如果你没学会,那不要紧,因为接下来要讲的内容你就熟悉了。把批处理和movie movie的底层逻辑梳理明白以后,你会发现ai的话其实没有什么神秘的,不过是图生图的过程重复个三百次而已。
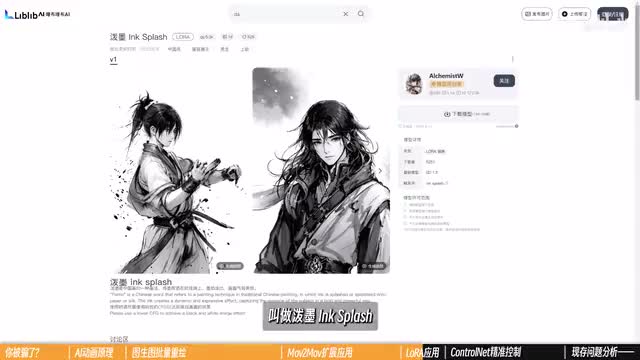
但这也就意味着,之前你所掌握的任何一种在stability version中用来出图的操作手段都是可以使用的。在制作ai动画的过程中,我们就常常会借助一些其他扩展应用的帮助,实现某些特定的目的。首先是laura在批处理或者模式模拟的过程中开启additional network,可以让特定lora微调你的绘制过程。laura的具体作用我们在前面的第九课里做了非常详细的分析。在ai动画中,最常见的应用是使用一些画lora来让你的画面增强某种风格特色。有一个非常好用的水墨风格laura叫做泼墨in splash,结合一些古风质感的大模型,你就可以轻松做出像这样酷炫的传统水墨风格动画作品。所以,对风格的延展,除了关注大模型所能实现的效果,还要多留意这些富有特色的微调小帮手。此外,我观察到很多ai动画的创作者会将具有辅助性的对画面改动不是那么大的loa添加进去润色,例如使用detail trickle丰富细节,或者画人士加入fashion girl一类的美颜。laura, 这是加了额外的调料以后出来的效果,你觉得如何呢?其次。
control net关于c control net神通广大的控制能力和它的作用原理,我们也在第十课里讨论的非常充分了。在这里就直奔主题吧。每一种control net在a i动画的过程中,其实都可以发挥一定的效果。如果你专注于浮现人物姿势,我会推荐使用open post,特别是要开启face,因为它在对表情的附件上会大大增强你动画的生动程度。一些近程镜头,特别是会扫到首部的,一定要开启hand,嫌麻烦你就开始一步到位。如果你致力于还原具有场景特征的画面,那一定要开dept根据我的亲身体会,depth会极大程度的降低发生在复杂背景里的闪动速度。在你的画面变化幅度不大,主题比较固定的情况下,开启kenny和soft edge一类的控制,我能还原准确的主体形象。如果你使用的是最新一点一版本的control t它还可以开启一个叫做line art线稿的模型。它可以提取比canny更为精细且富有连贯性的线条,对具体对象轮廓的描摹更加确切。
在输入不同属性的信息图时,记得要选择对应的预处理器来让结果变得更准确。有不少a i动画的创作者致力于用这样的方式。转会mini dance一类的人物舞蹈动画来实现a i三选二。为了维持角色形象稳定,大家常常也会加入一些对应的人物laura。但如果你画的是一些比较冷门的角色人物,没有人类laura那该怎么办呢?c t r l n x在最新的一点一版本里推出了一个新的模型,叫做reference only。顾名思义,这个模型的最大作用是提供参考。你可以把一张记载了主体形象的图片置入到c t r l n e t中,然后开启references only。它就会致力于生成过程中都去复现这张图片上的一些特征,从而让生成出来的每一张图都跟这张图足够像。对a r r n来说,这个特性非常有用。
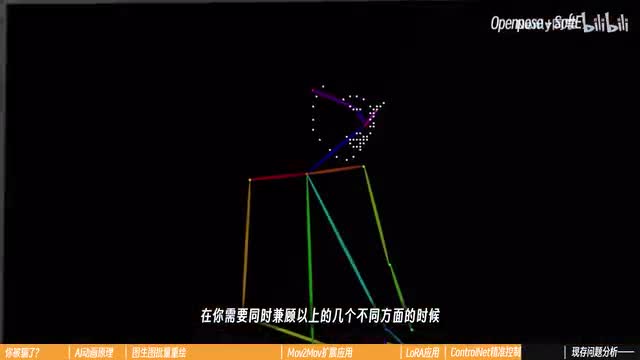
reference n n的这张参考图可以是角色的清晰官方图,也可以是你在测试过程中觉得最满意的那一张,和ura一样,我喜欢适当调低权重,防止图片过度影响本来绘制的风格。实际测试一下,这是在没有load的情况下,meta reference only实现的效果,你觉得哪一个更好呢?无论如何,这两个加了东西的都比不加东西的要稳定自然的多。你肯定也已经想到了multicolor l net同样可。并在这个过程里发挥作用。确实在你需要同时兼顾以上的几个不同方面的时候,可以加多重控制网,实现更严格的控制。有几个我非常喜欢使用的组合是可以向你推荐的。例如画人物是我会用open pose加低权重的depth来准确呈现体态,画的场景比较多的时候就会加上candy或者line二,再加aps固定场景细节实现的风格转换比较大的时候就会用soft edge将open pose保留充分自由度。但我其实并没有推荐你在ai动画里使用太多的control l e t。原因主要有两点,一是我们之前提到过的过多的控制欲会让a i丧失自己的创造力。

科学点说是加加的控制引导,让i过分的重视信息图,而削弱了风格化重绘的影响,这一点你可以直接从这组对比图中看出来。另外一点就是在使用更多的控制的时候,你你的绘制速度会变慢很多,这一点我们马上就会分析到。总而言之,在ai动画里应用lora和c t r l e t会让你的动画拥有更高的细节质量和更精确的控制水平。在将来可能还有更多对图像生成有所帮助的扩展应用被加入到web u i中。如果他们能在这些工作的流程里被充分利用起来,那你的ai动画作品一定会拥有更大的发挥空间。先别急着激动,说到这个份上,我们就不得不提一些ai动画现阶段尚且存在的问题了。在我看来目前所谓的a i动画其实还不是非常成熟。它的核心问题归结下来可以用三个词语来概括。一是错乱a i并不能正确读取到每一张图片上的内容,且无法理解一些动作表现与空间关系。
这一点在画面变得。越来越复杂时,也会变得越来越严重。二是闪烁a i在刻画前后的真实经常会存在不一致的现象,从人物外观特征到服饰到场景都有可能变化,从而造成类似这样画面一直在闪动的效果。而第三则是最重要的一点,速度慢。在前面的案例里,我们绘制一个十二秒的中等清晰度视频要花上八分钟左右。这就意味着每生成一秒二十五帧的视频,大概要花费四十秒左右的时间。你可能会觉得这个水平好像可以接受,换算成一个一分钟的视频也只需要四十分钟。但我用来测试的显卡呢长这个样子。而在进一步开启诸如control l net的坡慢进度的扩展时,这个时间甚至会两倍三倍的往上翻。

这还没算上反复调试测试用的时间。你的显卡在这方面表现如何呢?在画一张图的时候,我们的一些操作对生成的影响很小,前后差个几秒里不会有太大感觉。但在ai动画里,任何一两秒的时间差距在重复几百张以后也会被放大。你所能感知到的时间差异。这这三个问题严重约束了ai动画的产出效率,也限制了我们的创意与想象力发挥的空间。因此今天的a i的话只能说是一个一个的问题的生产力。不过在过去的半年里,围绕着对ai动画的探索技术,社区里涌现出了许多致力于优化解决上述一系列问题的手段。相对应的扩展应用,例如多帧渲染、背景分离处理和单帧提示词反推这些方法,我们的不同的能力也有各自的优缺点和技术难点。例如多多真渲染可以利用前后帧的画面的辅助进行生成的实时显示,实现稳定的画面传达。

代价就是绘制的总时长会变成原来。的三倍。有没有一种手段能同时解决上述的这一系列问题,既轻松又稳定的把这个动画做出来呢?答案就是这样一款叫做absence的人工智能生成应用。




