
在本期教程中,你将学习到如何在康复u i中使用enemy d五生成效果经验的ai动画视频。如果你还没有上手过康复u i没关系,别划走,这个视频将会成为你学习它的启蒙。我将会在云端以免安装的形式,带你率先体验一番康复u i的便捷操作。让你在十分钟之内就爱上这个节点式的s d操作流程,并开启我全新系列的康复u i教程。在视频的最后我还会分享许多优质的康复u i工作流,让你一步到位快速上手。作为一期启蒙先导教程,我将不会在这期内容里教大家如何本地部署康复u i,而是会选择一个优秀的云端来及时开启试用。
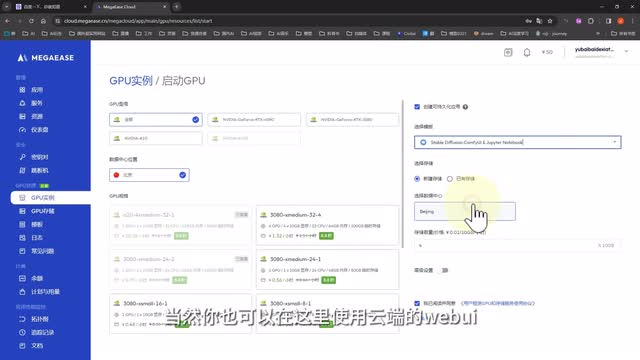
后面我还会更新系统全面的视频教程,请大家持续关注。我们打开mega ease登录后,在左侧选择g p u实例,然后点击启动g p u,在这里创建一个云端实例。右侧勾选创建可持久化应用,然后下拉选择最下面的康复u i当然你也可以在这里使用云端的web u i,选择上面两个就可以了。然后新建一个存储,选择合适的大小。这是相当于一个单独计费的持久的云盘,可以长期保存你上传的模型文件,价格非常的便宜。选择好以后,在左侧选择一个你想要使用的显卡,就可以确认启动了。
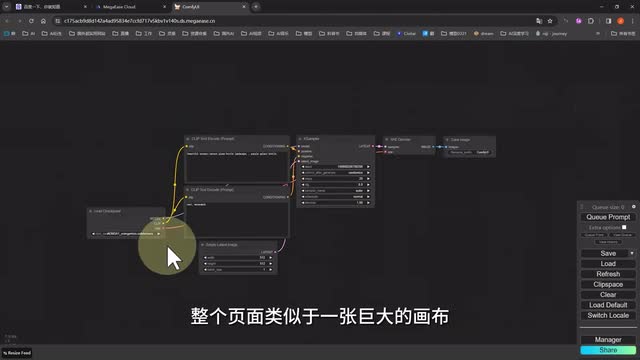
两分钟以后一个云端康复u i就搭建好了。我们只需要点进去,然后点击这里就能打开康复u i的操作界面了。首次进来以后,映入眼帘的会是一个最简单原始的纹身图的工作流。整个页面类似于一张巨大的画布,每一个模块都以节点的形式分布在。画布中并且以不同的颜色的线条相互连接着。我们先不去探究这每个节点的含义,我们只需要知道conf u i。
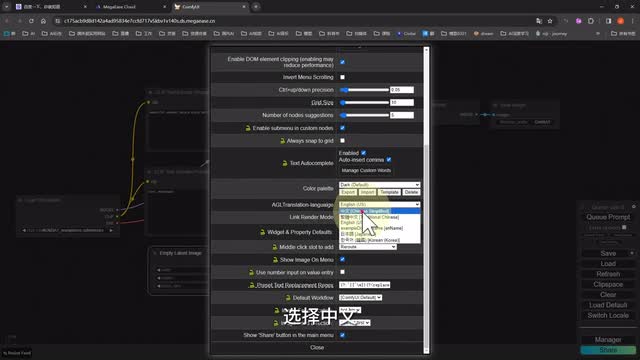
最简单的理解就像是一条条管道一样,通过不同的节点被染成不同的颜色,最后汇聚到一起,共同完成一幅多彩的画作。接下来我们会发现整个页面是英文的。没关系,云端内已经帮我们安装好了汉化包。我们只需要单击右侧选项上方的设置图标,在设置菜单里找到语言选项,选择中文,页面就会自动刷新成中文模式。当这些熟悉的内容出现,你是不是会觉得画面瞬间就友好了许多呢?不过我还是建议大家在后期熟悉了以后,时常切换回英文模式。因为有一些节点或者说功能翻译成中文以后呢,就很容易造成无法搜索,导致你找不到节点的问题发生。
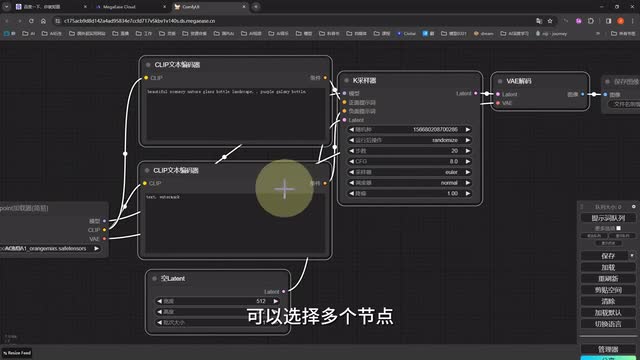
在设置好了页面以后,我们来了解一下基本的页面操作。首先鼠标的滚轮可以放大缩小页面,然后左键点击画面的空白,哦,不是,是没有节点的空灰部分,按住就可以拖动画布。而我们按住control再点击鼠标左键的时候呢,就会变成选框模式,可以选择多个节点。如果只单击选择节点,节点就会被选中,变成加白色外框并显示高亮的模式。而节点也是可以选中以后拖动在画布里面任意移动,然后连着的线也会像路飞的手一样变长。此外节点还可以堆叠到一起。
后加上去的总是喜欢在最上面的一层,总之就是可以任意摆放,自由度超高。你还可以右键点击节点选择颜色,为它赋予你喜欢的颜色。我整理一下,然后当你需要一个新的节点时,只需要在空白的地方单击右键,选择新建节点,就会出来一堆的内容啊,这些你懂的,后面的教程我们会来逐个击破。而现在我们了解了基本操作之后,就来个最简单的仪式感,用它的默认参数和描述语画一张图吧。这时候我们只需要单击右侧的提示词,队列系统就会按照我们节点的链接顺序依次运行。每个节点运行到哪个节点,哪个节点就会显示边框和高亮,最后生成出来的图片也会显示在预先设置好的图片预览节点里和页面的最下方,这样我们一张图片就完成了。
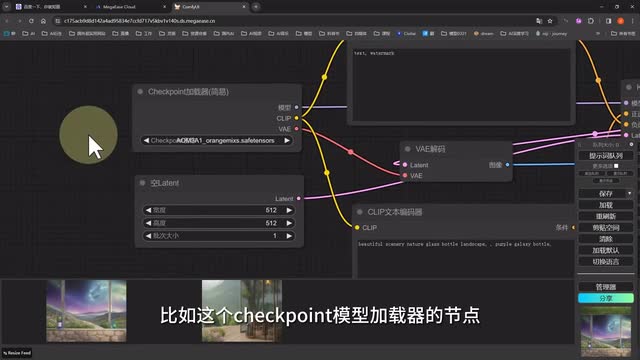
而如果我们的操作有误,或者说某个节点的线连接错误或者忘了连,那时候就会提示报错之后把出现错误的这一步以红色边框的形式显示出来,并圈起你漏脸的部分。对比于web u i一堆乱七八糟的报错码,这种方式是不是人性化多了呢?接下来我们再简单介绍几个常用节点,就可以开始我们的animal def工作流介绍了。比如这个check point模型加载的节点,就是我们选择模型的的地方。我们可以以云端端我们要预载载的模型文件,而这两个clip文本解码器就是我们必不可少的正向描述语和反向描述与输入框。这个空白latch点点可以设置一下与与输入数据模型节点。这里我们可以设置其他的类似于一点点迭代数据,clip点采集器等参数。
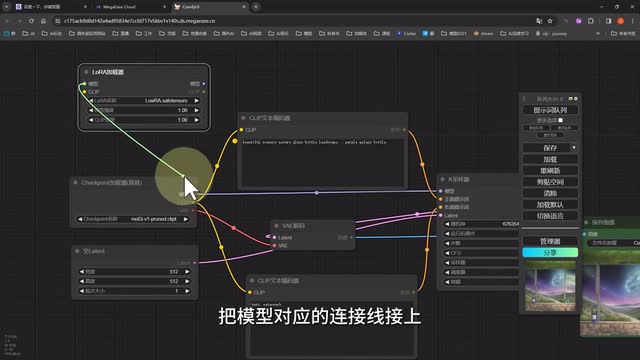
而当我们需要添加的内容,比如说我们要为它选择一个laura的时候,我们就需要新增一个节点了。我们可以鼠标左键双击空白部分搜索laura或者右键单击调出菜单,选择新建节点加载器,laura加载器就可以创建一个新的laura节点。然后laura的载入其实应该是在大模型之后就要进行的。所以我们改变连接线,把模型对应的连接线接上,再把大模型clip连接点连到laura上,laura的clip连接点与正向描述与反向描述与连接上,这样laura就正确的串。引进工作流中了,我们再次点击生成,大家就能看到我这个增加细节的柔软模型已经正常的生效了。看到上面的一系列操作,相信很多小伙伴已经开始蒙圈了,感觉好像好复杂啊。
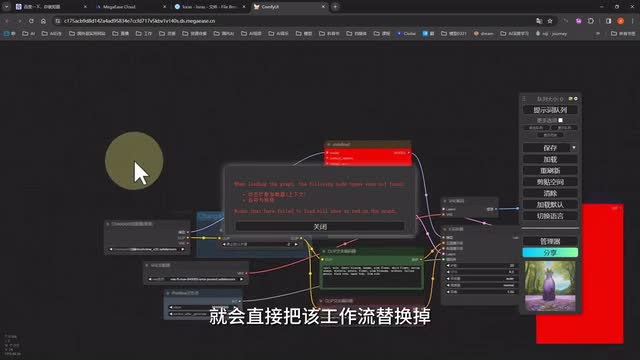
而这个其实你完全不用担心,因为在大多数时候我们都不需要这样自己去挨个调整节点。在康复u i里你可以直接把别人已经做好的工作流直接导入进来使用有两种方法,第一种是直接把带工作流的p n g文件直接拖入conf u i页面中。比如我们去到enemy i i f的github主页,把作者提供的标准纹身视频的工作流图片直接拖动进来,页面就会直接把该工作流替换掉你当前的工作流。还有一种方法就是我们在右侧选择加载,把我们下载或者保存好的jason格式的工作流文件加载进来,也能达到这样的效果。而相反,当我们想要把当前页面保存成一个工作流文件的时候,我们也可以单击右侧的保存,把它保存成jason文件,或者在空白处单击右键,选择最下方的工作流图像,选择导出两种格。是的,文件。
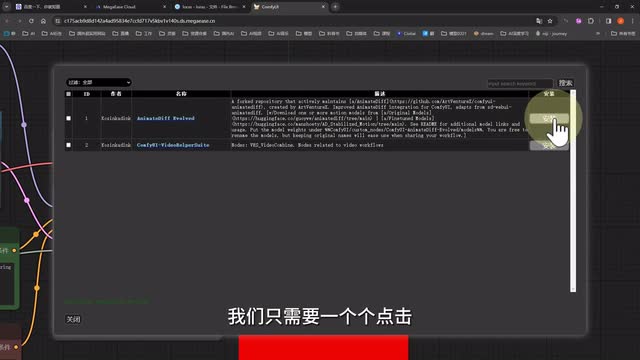
于是接下来我们又要引入一个新的问题,就是当我们导入新的工作流的时候,我们可能会发现有一些节点显示缺失。也就意味着你的康复u i中有某些扩展节点没有安装。这时候我们只需要点击右侧的管理器,点击安装缺失节点,系统就会自动检查你需要安装哪些节点才能运行当前的工作流。稍等片刻,等列表加载出来,我们只需要一个个点击,安装好这些节点,刷新页面后,我们再次打开这个工作流就能正常运行了。而在管理器这里,我们也可以加载所有的可用节点列表来安装或者卸载你的节点,类似于web u i里的扩展管理界面。当然你还可以在这里安装一些常用模型,或者更新你的conf u i版本,是不是非常方便呢?学到这里,你已经可以开始初步使用conf e i了。
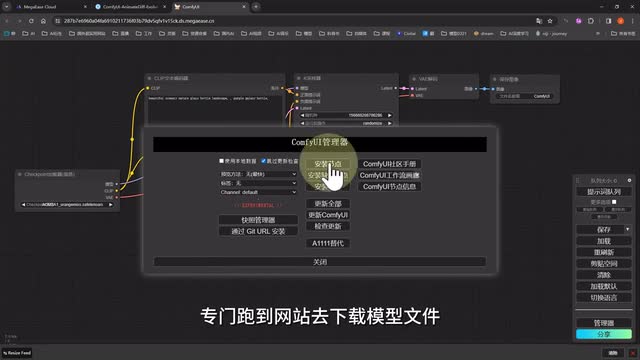
那么我们接下来就进入今天的正题,用enemy i f f生成酷炫的动画视频。我们刚才我们安装好了enemy dif,但是如果要运行它的话,还需要安装一些必备的模型。这时候我们不再需要像web u i那样专门跑到网站去下载模型文件。我们只需要在管理器的安装模型这里下拉或者搜索,就能在各种配套插件的模型库里找到enemy diff的模型。我们这里先安装一个s d一点五的v二版本的模型。大家如果存储允许的话,可以根据自己的需要加装其他的版本。
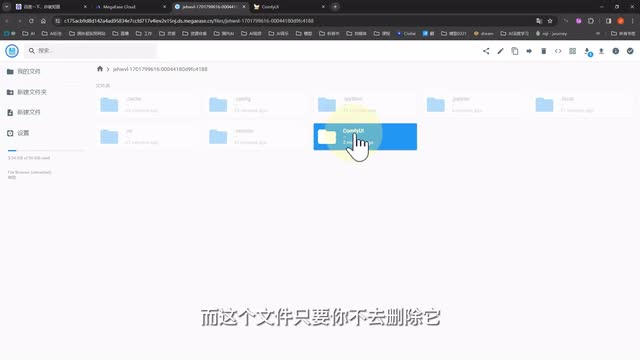
因为这些插件和模型都在云端后台有备份,基本上都是秒安装,可以说是非常方便了。而当你想要删除模型或者说管理自己文件的时候,该怎么操作呢?我们回到mega ease云端的模型,点击g p u存储,打开我们已经建立的存储文件,点击打开web控制台,就能在云端管理我们的文件了。而这个文件只要你不去删除它它就会一直存储。并且在你建立新的云端实例,比如web u i的时候,你也可以继续使用这个空间存储。如果使用久了文件比较多,我们还可以随时在这里操作扩容。而且原本云端环境所需要的空间以及预装载的所有模型文件都不会占用你创建的空间,可以说是非常良心了。
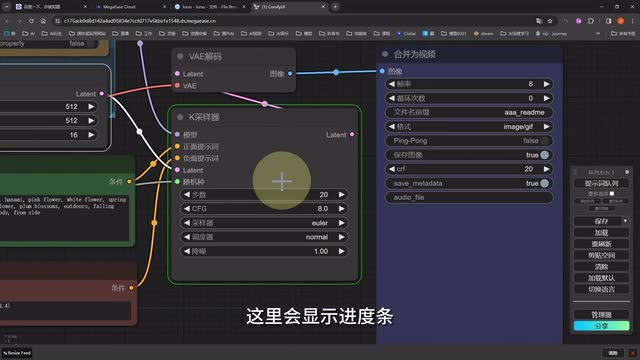
回到conf u i界面,我们选择一个合适的模型,然后重新选择一下v a e,把种子设置成随机,使用默认的提示词和采样器参数,然后在动态扩散加载器,也就是n my diff的节点这里选择s d一点五的模型。如果没有的话,点一下右边的重刷新,其他参数先不改,点击提示词队列就可以生成了。我们可以看到在k采样器的节点这里会显示进度条,而我们在云端的管理界面的g p u实例详情这里点击运行日志也可以看到后台运行的情况非常快。我们的视频生成出来了,速度比web u i着实快了不少。当然以上只是一个最简单的文字生成视频的工作流。接下来我还会把原作者提供的一整套循序渐进由难到易的工作流分享给大家。
大家可以点击简介或者置顶评论中的链接获取这些工作流。从提示次跃迁参与视频生成到生成四十八真的六秒视频,到生成带镜头运动laura的视频,再到生成以上视频后对视频进行高分辨率修复放大,到我们纹身视频的终极目标,利用c t r l e t来控制画面生成。视频涵盖的范围非常广大家只需要根据自己的要求加载相应的工作流,然后修改相应的参数进行生成就可以了。接下来我们就来实际运行一下,这里面看起来就特复杂,难度超级加倍的利用open pose图像控制生成视频的一个工作流吧。把工作流拖进来。在确认安装好了所有的节点以后,我们先来研究一下这个工作流。
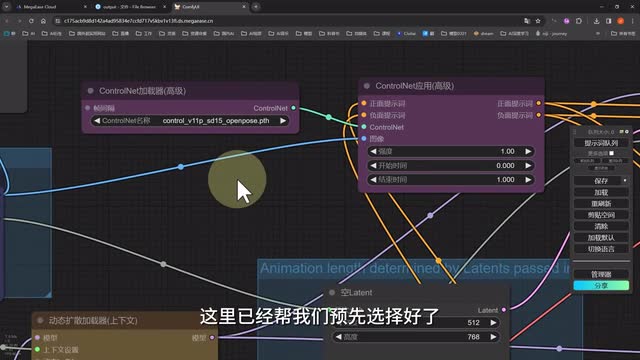
左侧有一个图像加载节点,我们需要把预处理好的open pose模式图通过这里加载进来。然后左下方是一些我们比较熟悉的基本参数设置。然后图像读取上限其实就是我们需要生成视频的总帧数,其他的我们不需要修改。中间位置上方是control net模型选择和参数,这里已经帮我们预先选择好了open pose模型,再往下是分辨率和描述与设置。右边的话这里除了基础参数设置外,会多出一个latent按系数缩放,其实就是图像的高清修复。而这里我们两个合并为视频的节点其实很好理解,就是一个是初次生成后的视频,一个是高清修复后视频的设置。

这里我们都能在这里得到预览。下一步我们开始准备素材,其实是一期的图模型设置,这里依然是我们把它变成一个小姐姐视频的视频。所以我们先把视频切帧转换成按顺序排列的图片。这一步有很多种方法。比如使用专业的剪辑软件或者拆真工具都可以。而我准备使用web u i里的一个超简单的插件,叫做is net pro。
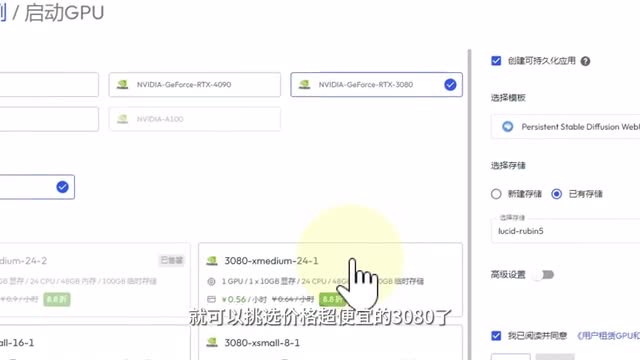
这时候我们只需要回到mega e e s云端界面,在另外创建一个s d web u i的g p u缓存。这里我们就可以选择我们前面已经创建的存储。这样的话两边的文件都会存储在同一个盘。而接下来我们在g p u的选择上,就可以挑选价格超便宜的三零八零了,一个小时只需要几毛钱。因为这个web u i我们只需要处理图片,对显存要求没有处理视频那么高。而如果你想要生成高分辨率的视频,或者试用一下最新的s v d模型,就可以尝试一下另外两种规格四零九零或者更强大的a一零了。
否则也可能容易遇到报显存的问题。等实例创建好,我们先在web u i里安装插件。因为mega ease云端官方后台对所有的插件和大部分模型都做了本地缓存。所以我们不管是在web u i还是web u i里安装插件和下载场。模型都会非常快。等插件安装好,我们把视频拖进视频生成帧的界面,然后设置一下帧率。
这里选择二十四,然后点击启用帧率控制,输入图片输出文件夹的地址。注意这个地址不能含有中文,否则会报错。然后点击生成真,很快我们的五秒火柴人视频就被切成了一百二十帧逐帧排列的图片了。这时候我们回到conf e u i里,点击选择文件夹上频,选择我们的文件夹,然后设置图像读取上限为一百二十,完成图片上传。然后逐个设置其他参数,选择一个你想要的模型,选择v i e,把种子设置成随机,接着选择enemy diff的模型。设置好c r r l t的模型和参数是找分辨率,把描述也输入进去。
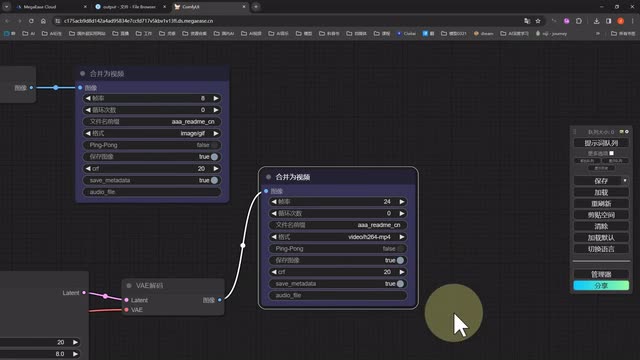
大致的意思就是一个选择一身白的女孩在橙色的背景下跳舞,然后我们设置一下基础参数,而到了后面我们再导出视频。这里初次生成的时候,我们选择合并成八帧的g i f图,放大后我们设置合并成二十四帧的m p四的视频。因为我们最重要的肯定还是高清的视频嘛,前面的做个对比就行。设置好以后,点击提示词队列就可以开始生成了。视频完成以后,大家可以在这里看一下效果对比。因为我的火柴人没有手指,所以这块可能会有点崩。
但是整体效果我觉得还是不错的,后面我们也可以继续来优化。最后别忘了去云端存储的output文件夹里找到刚才的视频并下载下来哦。以上就是我们今天config i的先导教程了,不知道看完视频的你对coffee u i有没有产生了一点兴趣呢?




