
这是我的声音。那这个声音呢,你们有没有觉得熟悉?那这是谁的声音,你们听出来了吗?只需要几分钟的时间,让你学会克隆任何人的声音。我知道这些视频的收藏一定是大于点赞,希望大家在收藏的同时可以点个赞。这里我很重要,万分感谢。
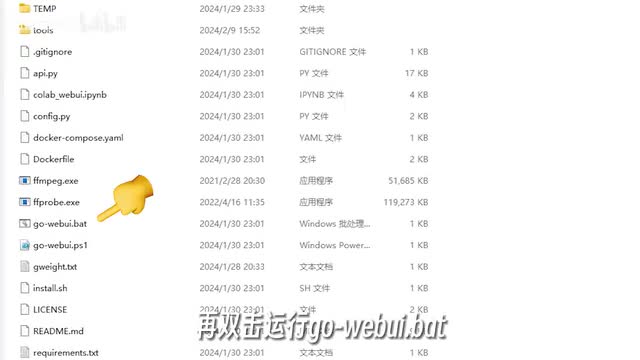
拜托我求你了,爱了。首先解压这个压缩包,然后打开解压后的文件夹了。首先运行g o y b u i点bet稍等片刻,等它加载完毕就可以成功启动网页端程序。接下来我们可以把提前准备好的音频数据上传到应用程序里面。
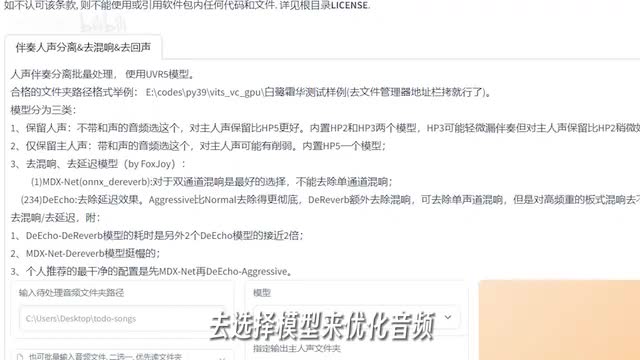
如果有背景音乐之类的杂音,可以先勾选上u v r五的选项,会自动打开一个新的页面,把需要处理的音频上传上去。大家可以根据说明并结合音频的情况去选择模型来优化音频。大部分的音频选择第一个模型就可以,选择好了之后点击转换就o k了。等输出信息这里有了提示,就可以在输出目录找到已经处理好的音频文件了。
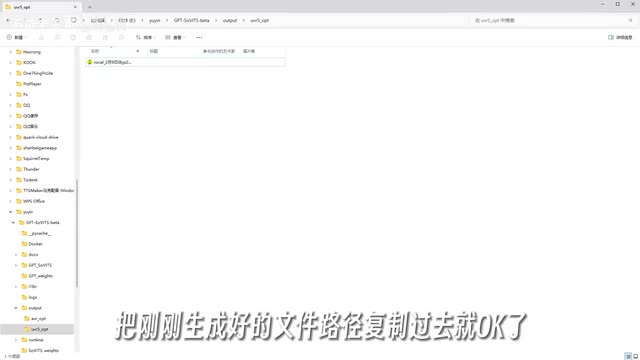
有些处理之后的音频文件没有人声,大家可以听一下,然后删除掉没有用的音频。第二步就是切割音频了,先取消勾选u v r五,然后在这里输入音频文件夹的路径,把刚刚生成好的文件路径复制过去就ok了,其余参数保持不变就可以。然后点击开始语音切割,稍等片刻会默认把。切割好的文件输出在output slicer o p t文件夹当中,然后进入到第三步当中打标。
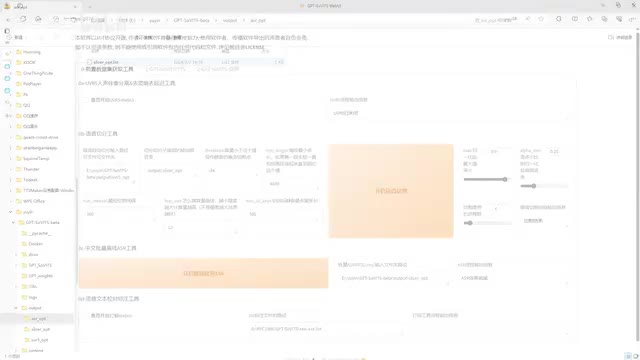
打标就是把音频对应的文本识别出来,把切割音频的文件夹路径粘贴到这里,点击开启,稍等一会儿出现a s r任务完成的提示就o k了。打标的结果会输出在output a s r o p t文件夹当中,把list文件的路径粘贴到这个下面,然后勾选开启打标,web u i就会自动打开一个页面。在这个页面里可以根据切割的音频对照左边的文本,看有没有文字或者停顿上的错误。每做出一个操作都需要点击一下submit text来保存。
结果所有内容都操作完完毕之后,再点击c o fell来保存文件,就可以关闭这个页面了。第四步就要开始我们的音频训练了,选择一杠g p t杠service杠p t s页面,把这个名称随便填写就可以。把刚刚打标文件路径和切割好的音频文件路径分别粘贴到下面的两个输入框当中。然后直接点击下方的一键三连,就可以开始训练我们的声音模型了。
训练完成之后会有提示信息,然后再切换到e b杠微调训练的页面参数一般保持默认即可。如果你的显卡选择小的话可以。适当降低batch state的数值,然后点击开启这两项训练就o k了。成功之后右侧会有提示,在g p t v s和swifts这两个文件夹里就可以看到训练好的模型了。
这时候我们切换到e c杠推理页面,这两种模型默认都选择最大就可以。前者模型中的数字代表了训练的轮数,后者模型中的数字代表的步数。选完之后再勾选开启t t s推理,稍等一会儿打开推理页面之后再参考音频,这里生成一个之前已经切割好的音频文件就可以了。再把音频中文字输入到右侧文本框当中,选择好语种,在需要合成的文本处填入你想要生成的音频文字,选择好语种就可以合成语音了。
基本上每次生成出来的语言都会有细小的不同,大家可以多尝试几次。你们猜猜我是谁?你们猜猜我是谁?你们猜猜我是谁?如果想要生成一段文本的话,可以在下面的文本切分处填入整段文本,再选择规格去切分。我们经历了一场兵荒马乱的战争,没有硝烟,没有流血,却伤亡惨重。青春是美好的,带给了我们很多的快乐和激情。

可是青春又是悲伤的,当有一天青春不在,我们会拼命的去还原。值得一提的是,g p t service这个声音课程软件是b站的大佬花而不哭独自开发的,并且在github上面已经开源了项目。这种开源的精神还是非常值得学习和赞扬的。好了,以上就是今天的全部内容了,我们下期见,拜拜。




