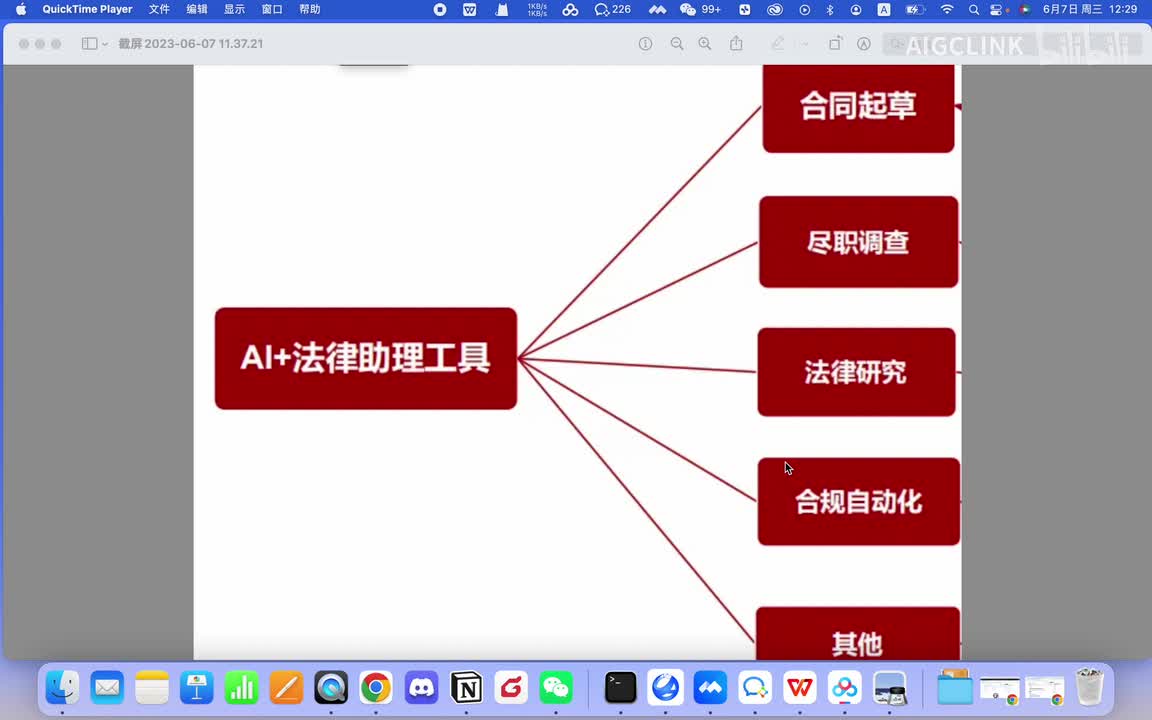
我们来聊一下。a i大模型在这个法律领域的一些个应场景啊,主要从从法律领域来说,可以从这几个场景啊来解来解决一些个问题。比如说像合同起草啊、尽职调查、法律研究啊以及合规自动化。如果说反映我们实际的工作中的话,就是我觉得未来啊因为这个a i法律a i的一些个工具的出现,会使得企业本身的法务这个岗位会消失。但律师的话不会,因为律师还要涉及到一些个相关的主体责任。以及相关的打官司啊等等这些的话他们不会消失。但是对于公司里面的法务,比如说日常的审合同啊,日常的对一些个法律问题的咨询啊,我认为这部分工作可能未来会被a i替代。
我们今天就来聊一下。关于这个a r这个关于这个法律这块相关的一些大模型啊,今天主要聊两个部分。一个部分是关于法律现在市面上的大模型有哪一些。第二个部分的话来聊一些目前如果你自己要训练一个法律的垂直细分的一个大模型的话,那么你可能就需要。自己去呃用一些数据,网上有一些我这里的话提供给大家找了三个数据集啊。就是说一个的话你比如说我先说一下数据集啊,用就是说我们都知道a r的话,因为大模型这个生成式ai的出现,使得跟以前a r的话产生了一个质变的一个变化。最大的变化是什么?最大变化就是说。
像以前的a r的话,他不知道就是不知道他是有边界的。但现在的a r的话他是没有边界了,他不知道他可能会给你胡说八道啊。如果说你给他训练的是一个可以胡说八道的一个a r那那么他就会给你胡说八道。当他不知道的时候,他就会胡说八道。比如说你训练他是一个专业的律师。你用律师的这个比如说你如果说你用律师的历史的合同啊,就这个律师曾经给这个企业就是拟过的各种分类的各种各样的合同来让他学习的话。那么未来这个是训练出来这个a i它就具备审合同的能力。
如果说你给这个律师的是一种咨询能力,你把历史的你跟客户的这个聊天的律师咨询的这些记录,然后通过未给这个生成的a r那么a r的话就会这个大模型就会帮训练出一个能够满足咨询需求的。啊,这样的一个呃这个a r助手呃,律师助手。那么的话就是说这是两个相对相对比较常用场景。当然的话如果说哎我说我就是。我希望你训练一个蠢蛋,那你只需要给他呃就输入这个蠢蛋的一些相关的语料,相关的一些数据集,那么它就出来就是一个蠢蛋。你想给他训练一个非常专业的一个,比如说医生啊或者其他等等一些其他方面的一些个呃相关的语料,那么它出来就是一个非常专业的一个。这个相关的一个a r那么的话我们知道这个原理之后,那么你第一步的话你就需要数据集,对吧?你需要用市面上,比如说我们要训练一个法律的数据数据集。
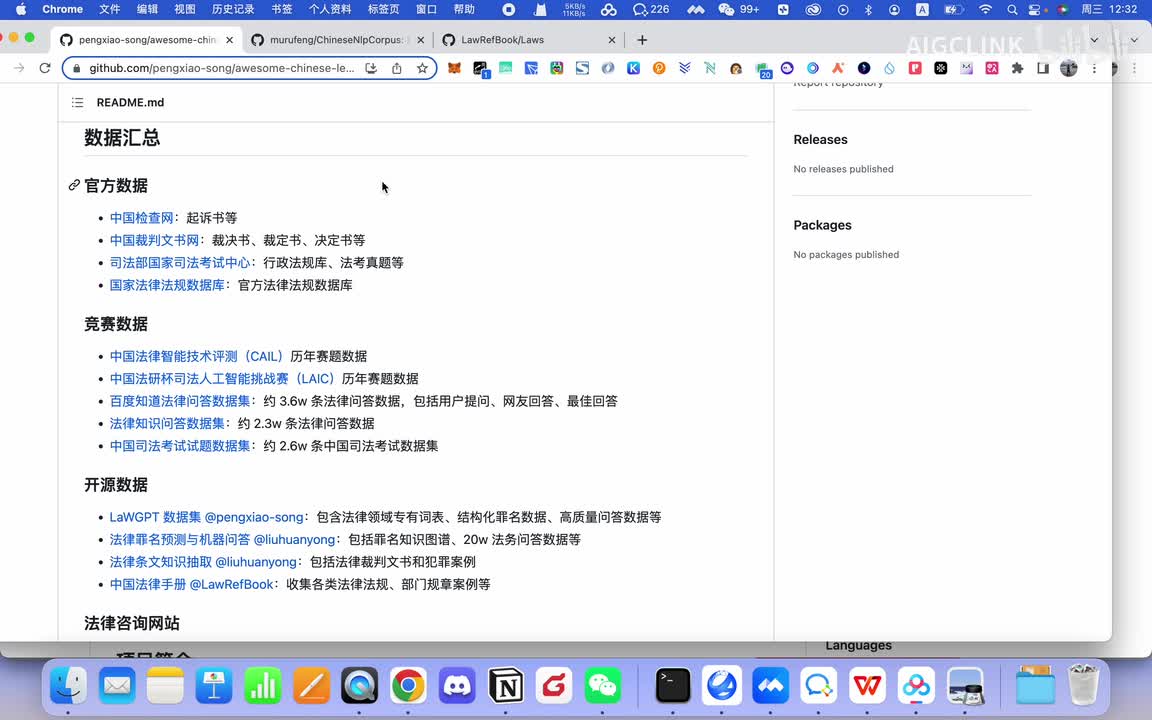
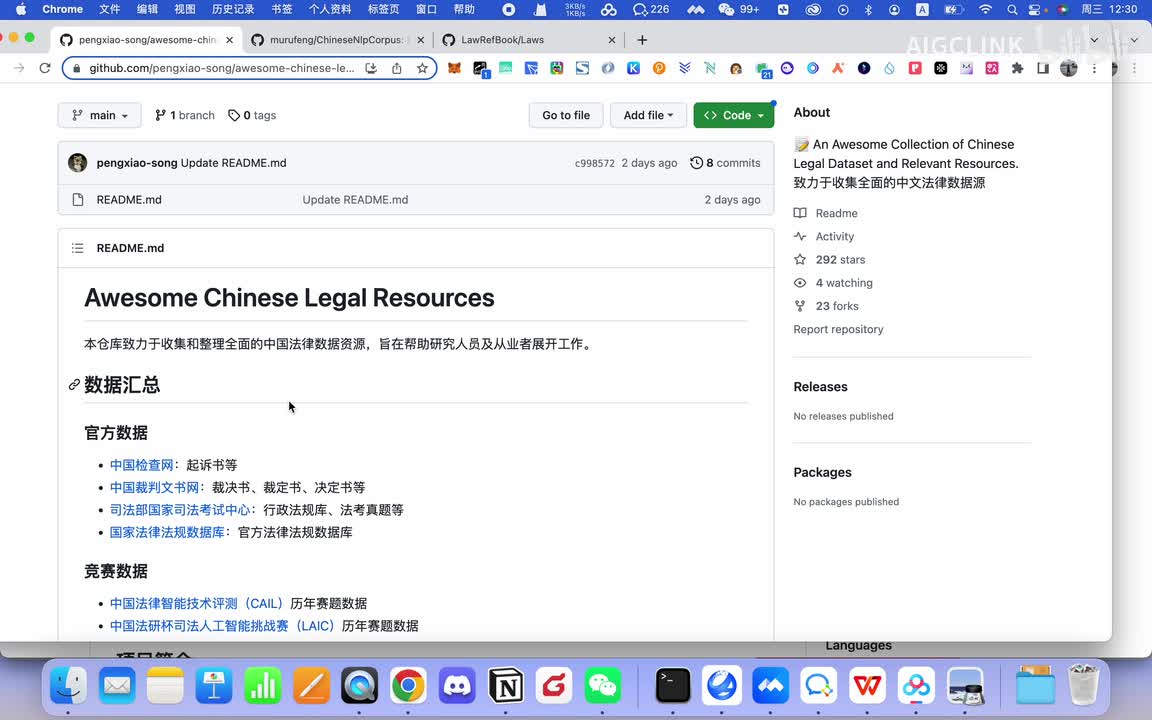
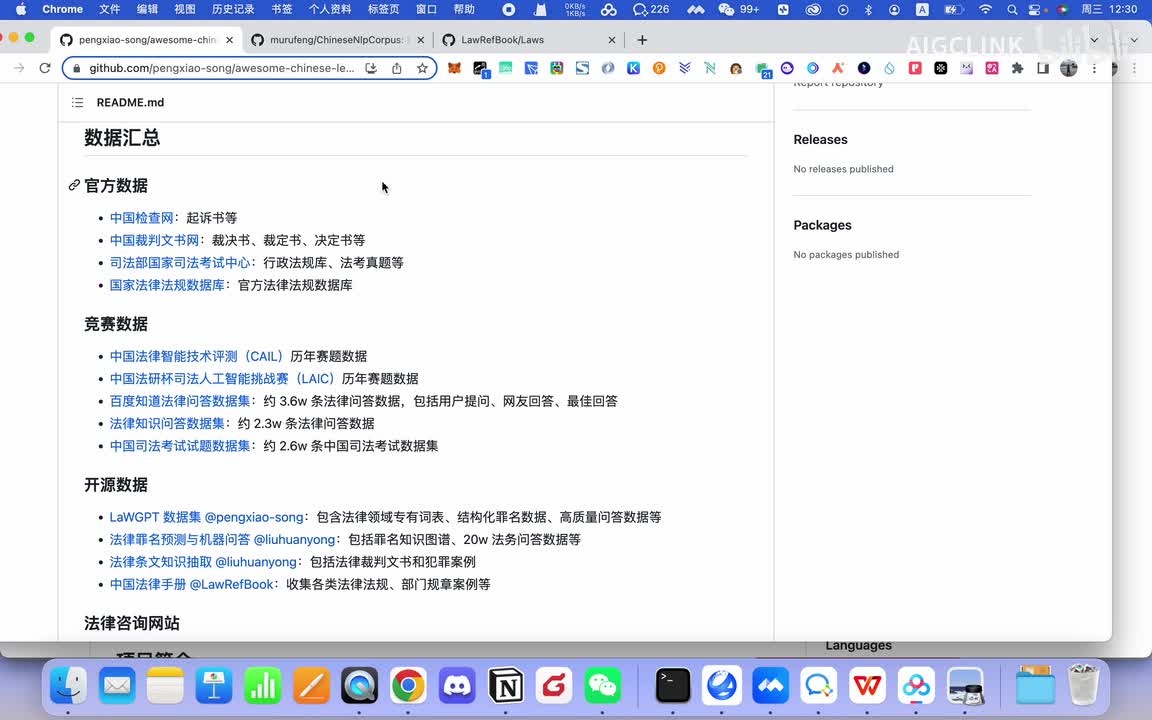
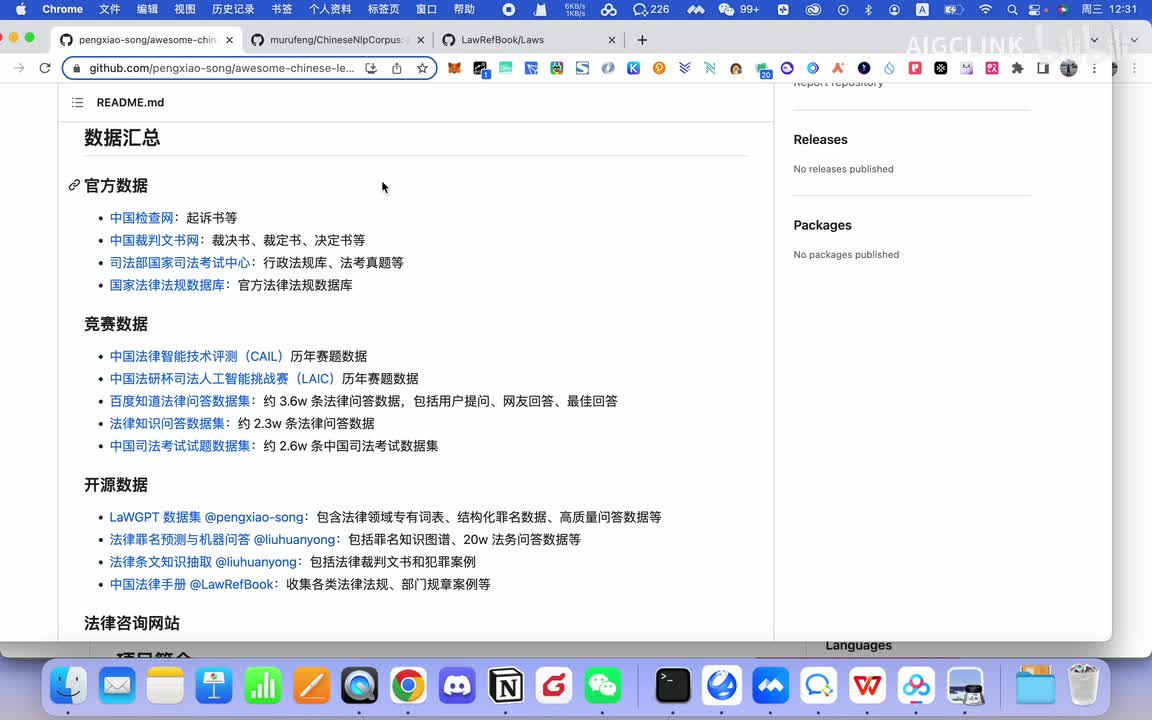
那你首先那你可选的这个数据有哪些呢?比如说啊中国的这个所有的呃,比如说起诉网上的呃裁判文书,网上的所有的裁判书。啊,所有的判决书,法官判的各种判决书,你可以让ai来学习。然后的话比如说各种法律考试的这些个考试题库啊,你都可以让a r来学习。比如说各种法律国家的各种法律也可以让a r来学习。那么的话,这是一个最基本的一个官方数据。那这个时候你训练的这是一个通用型的,基于官方数据的话,会训练一个比较通用的这种哎呀,你也可以基于竞赛数据啊,还有开源数据这些个相关的数据集来对它进行一个训练。当然还有一些个法律咨询网站,一些数据。
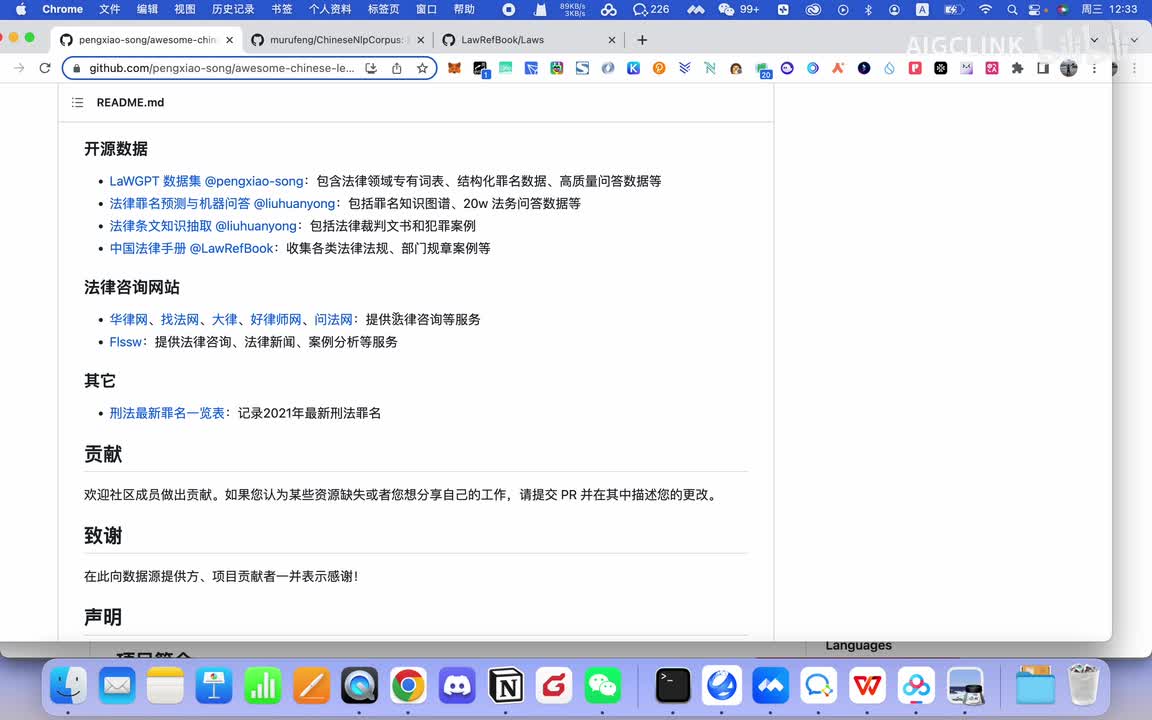
如果你有他的一些个相关的一些数据的话,你也可以用来训练。那么这样的话就能训练出一个能够日常帮助就是企业的,应该说是能解决企业法务的啊很多问题的。就是可能我以前公司需要一个法务,现在的话可能这个就是公司这个法务的话,比如我以前需要五个法务,可能现在一个就够了。这个法务借助a i的话,可能生成这个审核的什么,这个效率一下子提升了。这个其实对于律所啊,包括公司来说的结论成本来说都是很好的一个主要帮助。然后后面还有数据集,比如说像这个还有这些数据集啊,就是这个数据集什么数据集?这个数据集是类似于就是说让a r的话具备一定的就说话方式、情感啊或者说观点一些倾向性。
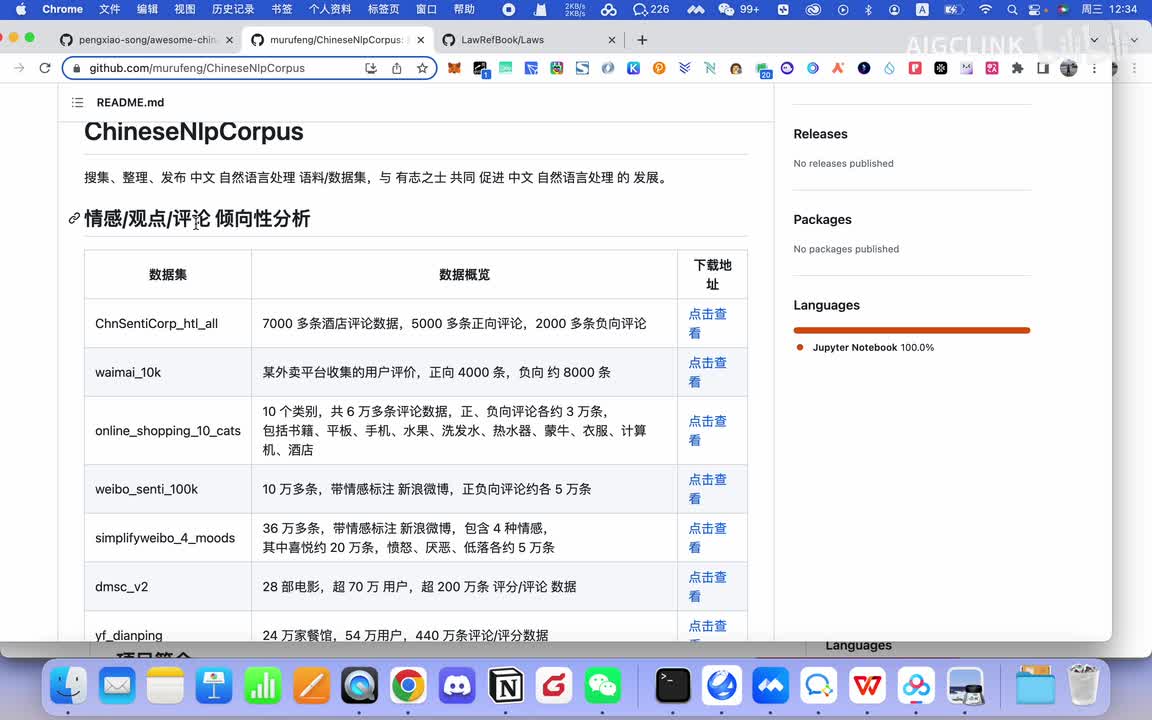
你的是说话方式,比如说哎我希望这个人说话跟周杰伦一样,或者我是希望这个人说话跟这个岳云鹏一样,那么的话你就可以给他喂一些个岳云鹏那种。他的输出的那种说话方式的一些呃规定啊,这个相当于训练文本的一些个style的一些要求啊,那这样他最后训练出来他的说话风格啊,就跟这个什么这些人你你想要的这个风格一样。比如说哎,我希望他以律师的口吻跟对话,那ok那你就可以给他注入一些个。以律师口吻的这种说话方式啊,这个的话我们也参考一下。然后还有一个的话就是呃,这也是一个数据集啊,然后这个是这个项目,就这个项目它主要收集数据集,它有各种各样的数据集,比如说最高人民法院的司法解释,刑法这些等等数据集。有了这些数据基本的数据集之后,那么下一步我们就可以选一些大模型来给我们自己训练一个大模型。目前市面上有这么一些吧,比如说law g p t t z z杠z h,这个是中文法律大模型啊,然后这个的话就是说。
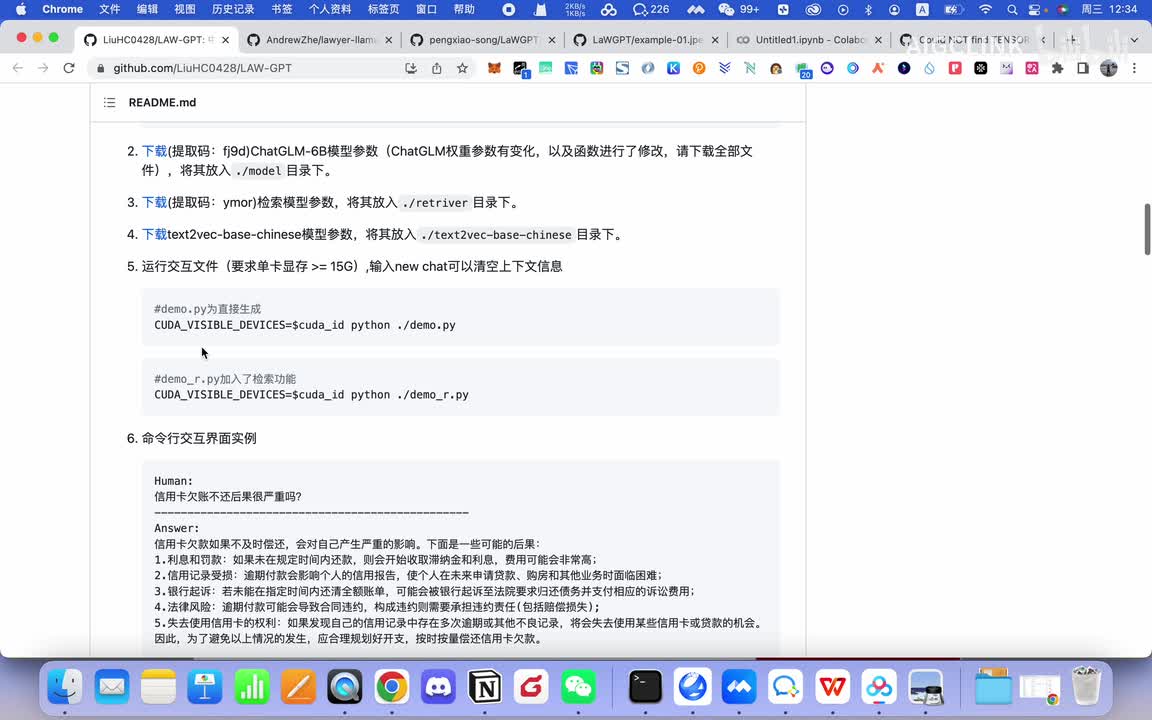
他们就是说基于这个清华的这个g g m m六的通用大模型,用lorry啊要用lorry来微调出来的啊。那么的话它它的它如果说你想体验的话,你可以自己按照这个命令自己体验一下啊。我这里就不装了,因为这个因为它这里的话要下载很多东西,需要在服务器上运行。啊,我这就不装了。然后其实的话就是我简单跟你说一下,比如说你在跟命令行交互的时候,你比如问他信用卡账单欠款严重吗?他给你这样回答。然后他的数据集的话是由这两部分组织这些这这两部分组成。第一部分就是说律师跟的这个客户之间的问答数据啊,大概有二十两百k的这么一个数据量。
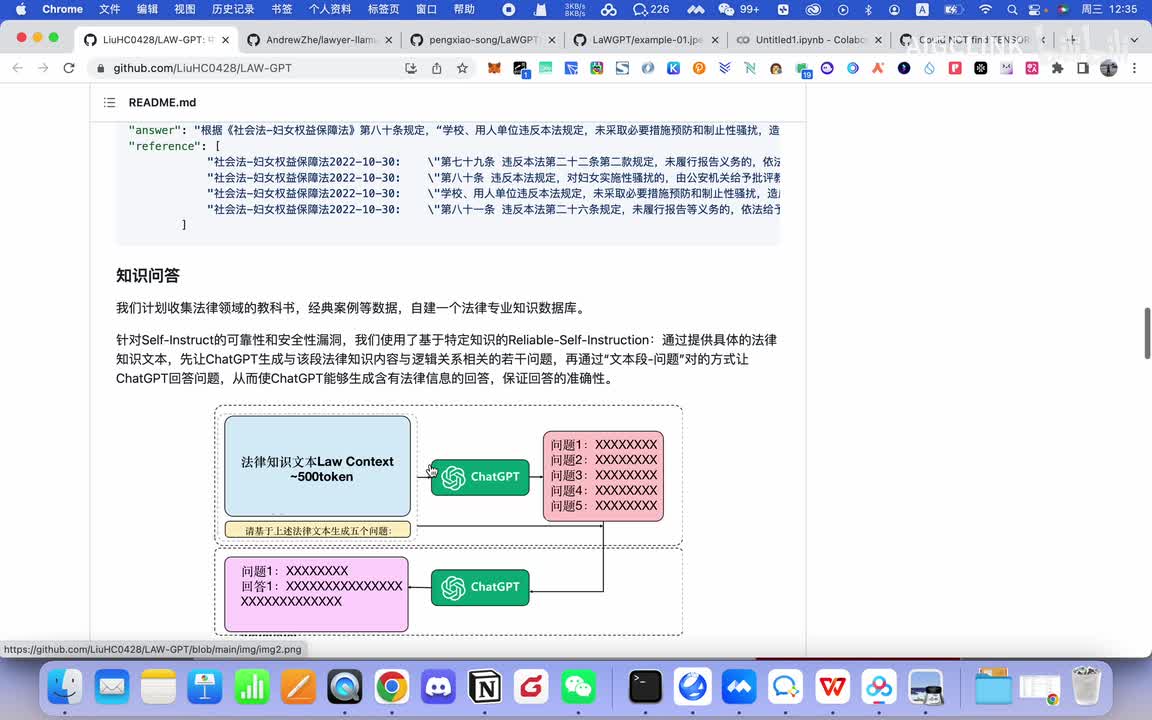
然后再有一个就知识问答,就比如说像百度知道里面有一些个知识类的一些个解释性问答啊。这个的话就是说他们现在还在做。但是我觉得就是说大家如果说你能收集到百度知道里面的这些个问答的话,你也可以来用来训练这个数据。那么就下面的话就大概它会有这么它是用这个格式啊比如说question这个,然后这个answer的答案是这个,然后底下相关的引用啊,这个的话大概逻辑就这么一个逻辑啊,比如说它的整个的一个模型的逻辑啊,使用的是呃这个reliable self instruction。就是说首先第一步的话就是说他把法律的一些知识文本啊然后送给chat g p t。然后让chat p g p t基于这些个相关的知识文本的话,就是生成一些问题。比如他可能问一些问题,把这个问题的话再用chat g p t啊把这个问题衍生出五个问题出来。
演出五个问题出来之后,然后再让这个五个问题再让叉g p再回答啊,有一个回答、两个回答、三个回答、五个回答。然后再把这个回答的话再扔给这个叫什么?就是这是数据它的基础的一些数据的构造,然后再把它扔给这个就是大模型来进行训练。啊,这里的话他举了举了一些这个对他训练来说,训练出来结果的一些个对比啊,所以的话就是说这个在法律领域也是很好用的一个大模型。这个模型的话是由这个上海交通大学的呃这个呃廖玉生,还有这几个人他们共同研发的。然后指导老师是这个王玉副教授。然后这个模型是一个,然后我觉得就是说law g p t的话也现在也是非常受欢迎的啊。你看它这个star的话也也是几百个啊。
然后就是下一个别受欢迎的是这个啊叫log l m a m a啊,它也是中文的一个法律领域的一个大模型。啊,这个大模型的话就他主要掌握了呃,比如说中国的法律知识,他把所有的这个法律相关的一些东西的话都喂给他了。然后再把一些个呃涵盖婚姻借贷,还有这些相相关的一些法律领域咨询的一些个相关的一些呃东西的话也喂给他了。那么他基于这两部分数据,相当于训练一个模型出来。然后至于下面也巴拉巴拉我就不细说了啊。就是说你只需要知道他能解决什么问题。因为他训练的他相当于学习了中国的法律知识,学习了法律实务,那你就可以把这个模型当做一个人来理解。
比如说这个人掌握了啊中国的法律知识,掌握了中国的法律实务,那么这个人能干嘛呢?这个模型就能干嘛。o k如果说我们希望一个大模型能够干嘛呢?如果说我希望你这个大模型能帮我审合同,o k那你就要给它喂大量的合同,然后以及这个合同对应解决的问题和文本相关之间有一个对应关系。就是说目的性,你的倾向于这个合同是解决什么问题的,有什么注意事项?有个数据标注,把两个关联性关联起来。关联起来之后的话,然后喂给这个大模型。然后大模型再根据啊这里面的一些个,对,就是根据你的这个描述各方面的然后进行学习。学习完成之后,那么最后的话就是说。他就可以来处理。
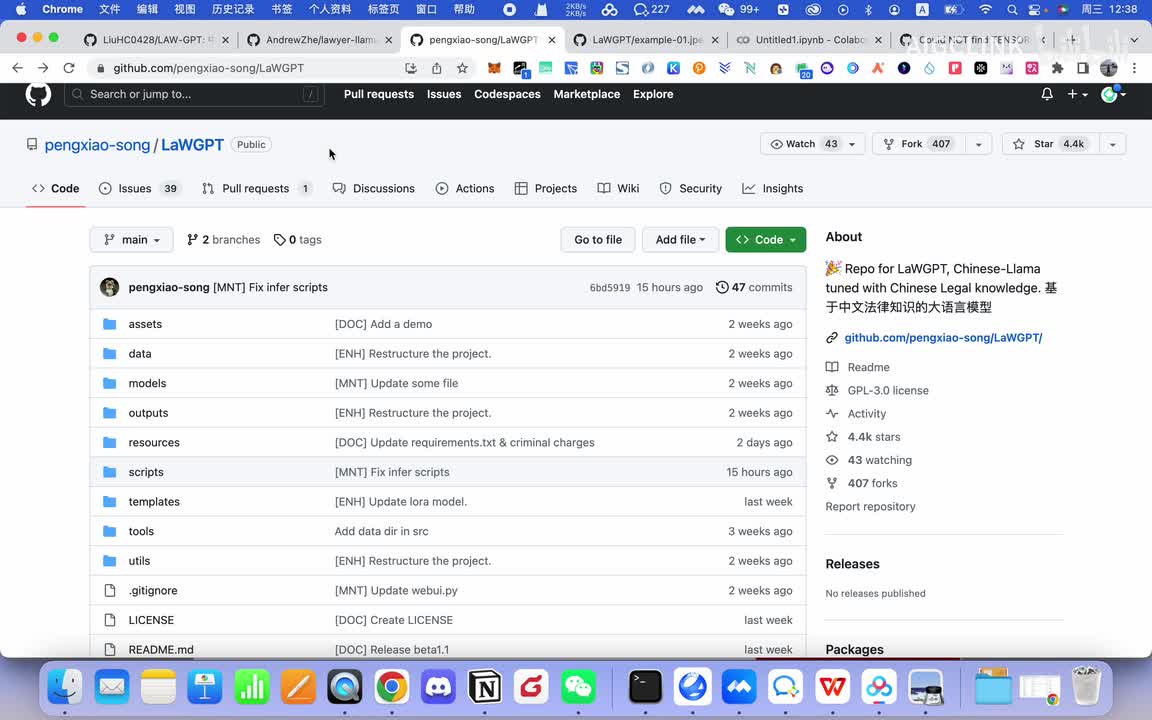
比如说你让他出一个相关的合同模板的时候,他就可以根据他历史学过的经验来给你出一个对应的模板。啊,所以它跟人的思维方式是一模一样的,它可以具备人的这种学习能力,并且的话把它学习能力用在正常的输出上。啊,然后第三个的话是什么呢?这个的话应该是现在非常受欢迎的。你看他的这个。呃,应该说是前段时间还在get hub这个呃开源模型这个榜单上的话,还冲到这个趋势榜上去了。然后它的话已经将近有四千四百个这个star然后有四百多个folk啊,那么说明这个模型是很受欢迎的啊,那么的话底下的话就是我们可以看到就是说有。呃,它的话大概一个它是基于这个l m a七b的这个通用模型基础上进行指令微调的啊。
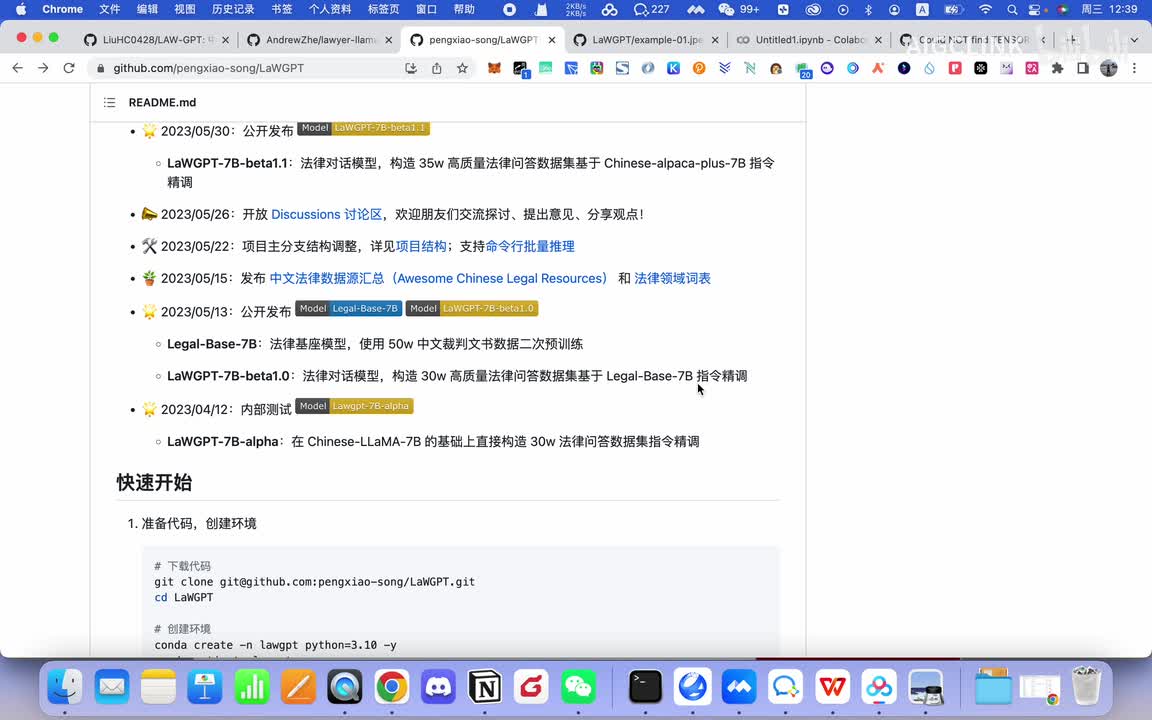
指令微调上部上面的话就是说呃它后来的话在基于这个base,它是发布的这个e lego base七b啊,这是它的法律基座模型,然后使用的是五十万的中文裁判文书。这个数据啊就进行了训练,然后底下还有一个对话模型,然后构造了三十万的这个呃法律问答数据,基于leg基于上面这个,然后再进行微调,大家也能看到这个是什么意思吧?就是说他现在学习分了两步,他第一步的话是先把这个裁判文书网上的所有的。这个裁判文书都学一下,判决书啊各方面的都学一下。完了之后他紧接着然后又在这个基础上学了这个摸清楚。然后他在这个基础上又学了一个将近三十万的呃,关于法律咨询问答的一些数据啊,这些个聊天记录啊之类的。然后再让他训练,然后再形成了一个。
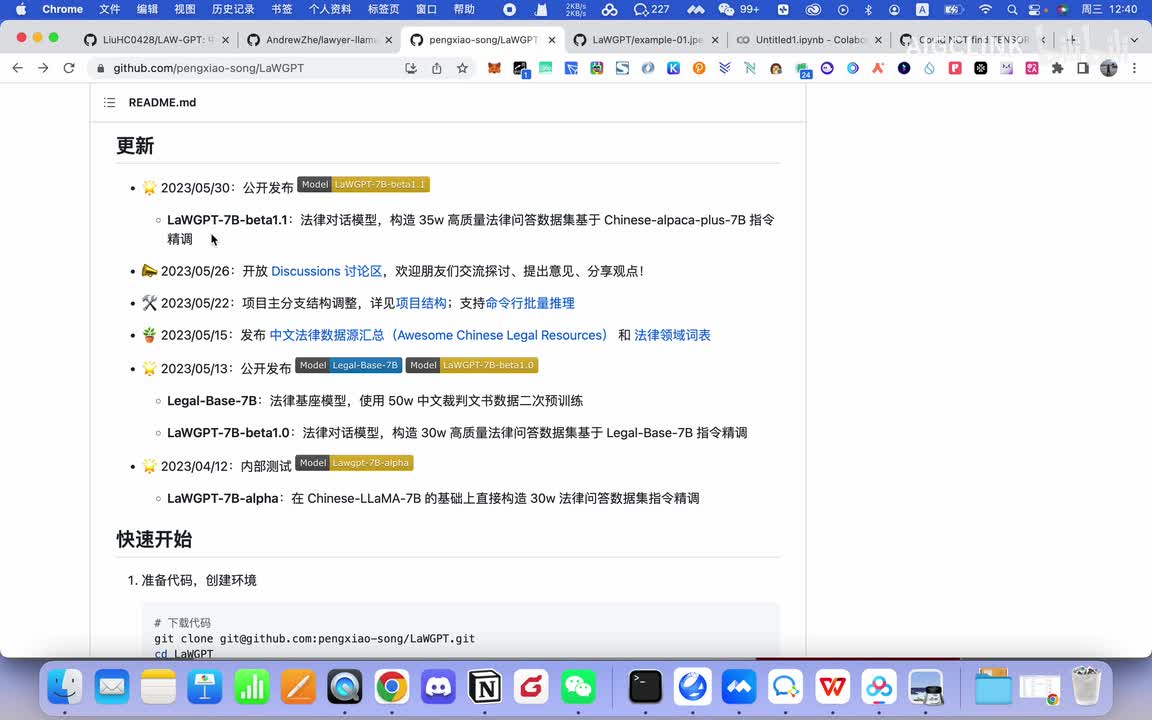
就law g p t七b的这个法律模型啊,那么的话他后来的话他把他的数据集向一他发布了一些数据集啊,比如中文法律的数据源汇总啊,就是我刚才给大家看到的有一个数据源就是这个。然后还有这个法律领域的词汇表这个啊以及这个呃上面的话就是他近期又发布了一个,五月三十号又发了一个版本就是。它又基于三十五万的高质量的法法律问答数据集啊,然后就是又基于这个chinese ipad这个plus七b指令微调又微微调了一次啊,所以的话就是说它这个模型一直在迭代。啊,一直在迭代啊,就是说迭代的话就是我们只需要关注他具备什么能力啊,比如他学习,就你要关注他具备什么能力,你就要关注他学习了什么东西比他学习了哎,就这个裁判文书网的所有的这个裁判文书啊,比他学习的这个什么所有法律的知识或者法律的考试,那么他在。考法律考试以及法律的相关的啊,比如说这些个解读啊方面就比较厉害一点。你如果让他学习大量的法律合同,那么他可能会在法律合同方面审的就比较厉害了呀。啊这是关于这个模型的大概一个原理。
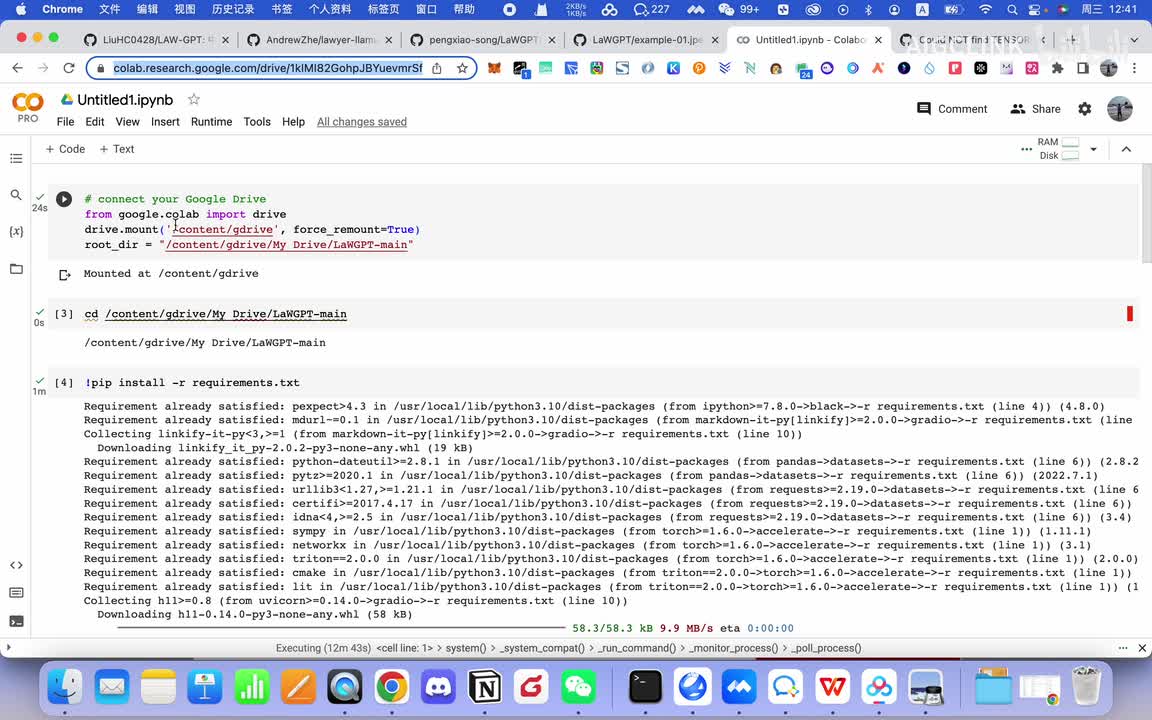
然后你如果要构造的话,你自己可以啊就是把这个命令就是体验构造一下。啊,大概的话,就你如果说哎,我这个。就是呃感觉我这个本地可能构造比较麻烦点,那你就在这个什么club co lab上你去构造就好了。比如说你你可以把它放在这个呃网盘里面,然后再呃再去构造它就好了啊,再去构造它了。我觉得这也是很好的一个方式。因为这个时间有限,我这里我就不给大家提。就是去这个呃安装,等他安装完了,因为他这里要下载这个就是九b的,这个应该说是九点九四g的吧。
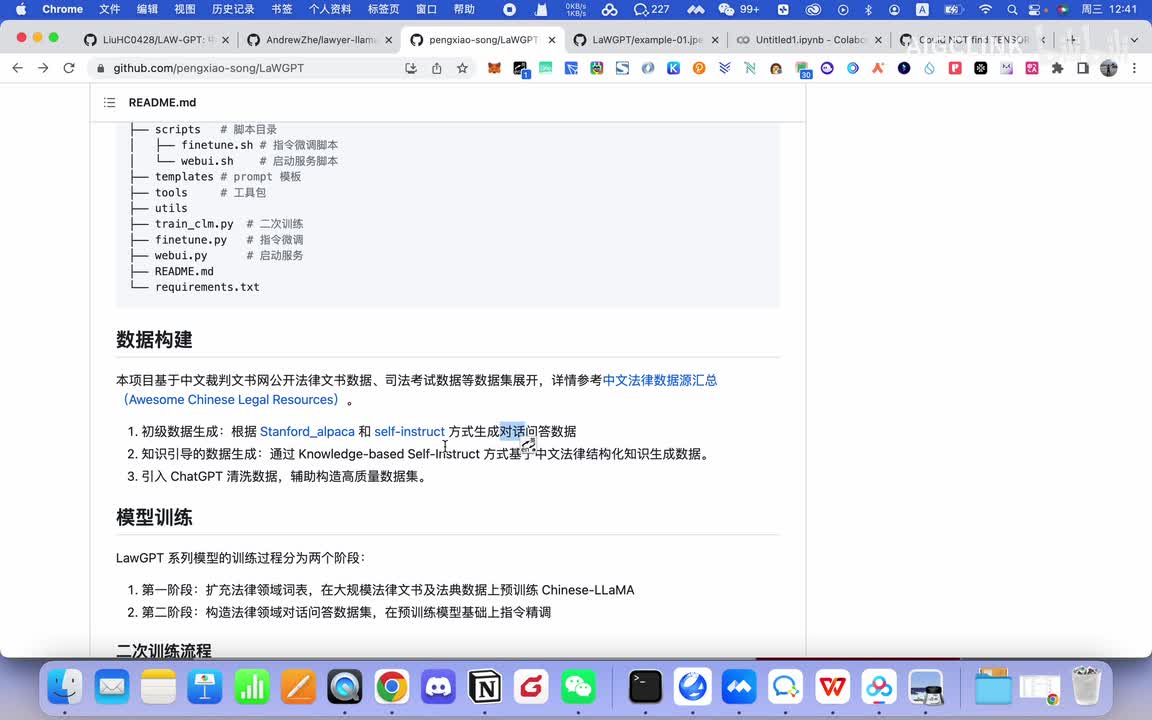
啊chinese g l m的这个大大于m模型,所以说它需要这需要很长时间啊,所以我这里我就因为时间有限,我就不再细说了。我给大家看一下这个模型,它大概一个。到最后就做完之后啊做完之后一些案例它大概的步骤啊,你比如说它数据构建,它分成几个步骤。第一步的话,它就首先根据啊这两个方这这这个模型,然后来生成这两个前面这两个构造函数来生成这个问答数据。然后问答数据有了之后,然后再把这个问答数据再通过in structure的一个方式。然后再生成一个结构化这个知识数据,然后再通过chat g p t来清洗数据,构构造一个高质量数据集。其实这里面工作量最大的就是说属于一个一般我们在做一个自己的一个大语言模型的时候,很大的工作量就是做数据清洗。
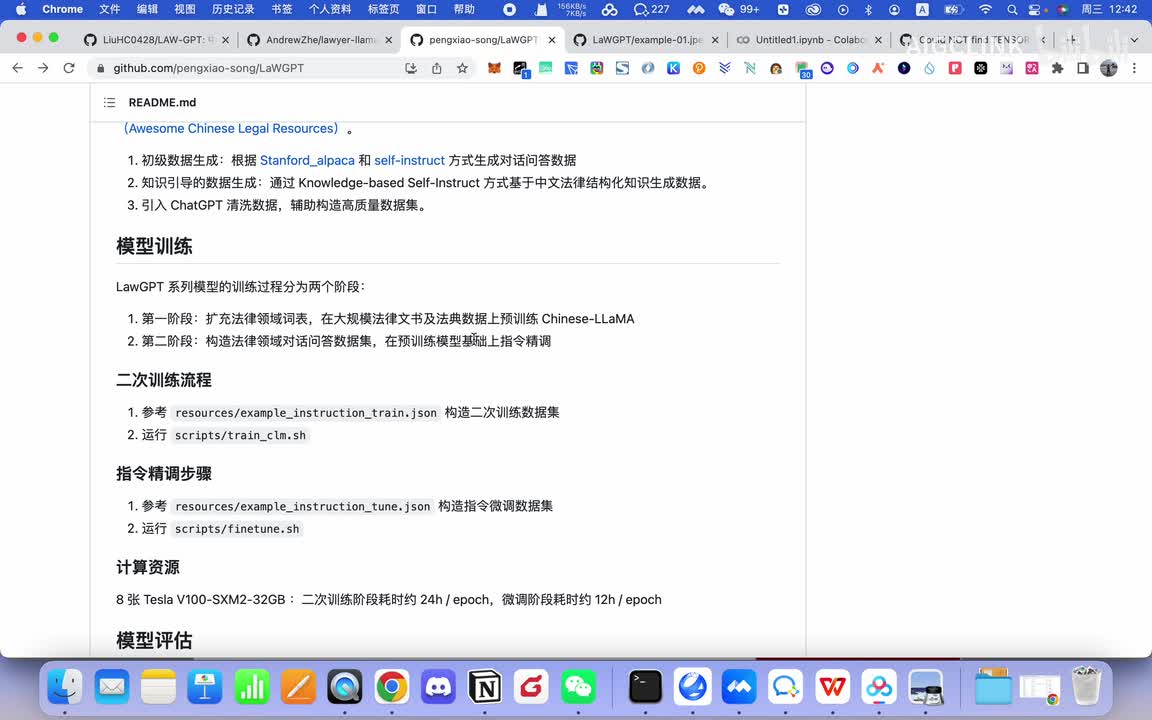
数据清洗置办这部分的话是工作量最大的啊,所以的话在这个这个过程中的话,大家我觉得这块呃我们后面可以找时间再详细聊一聊啊。然后模型的话比如分两个阶段,第一阶段它就扩充了这个什么呃呃什么词表啊,主要是在这个chinese l l l a。就是m a这个上面进行训练的。然后第二阶段就是构造,通过这个学习这个法律领域的这个问答数据集啊,然后再进行在上面第一阶段基础上再进行指令误工指令微调。然后后来的话又构造了一次,然后又训练了一次。然后后面就是还有一个就是指定荆条的这个,它有一个指定金条步骤,然后这里面有什么构造数据集啊?然后再进行微调等等啊啊这块的话就是说呃需要八张的特斯拉的这个呃v一百的呃三十二g的这个显卡来跑啊。两次训练它耗时了二十四小时啊,微调大概耗时了十二个小时啊,那么它模型的话大概输出的就是说比如说哎这边。
有个输入,然后这边有个输出。但是他给了几个呃给了几个案例啊,比如说你可以在这里来输入你的这个需求,然后这边的输出结果啊,所以说这也是一个很很有很好的一个就是说呃语言模型啊,所以的话当这个模型也有局限性,局限性就是说它对于。这个就是因为它这个数据源比较少嘛,所以模型容量也比较有限。啊。第二个的话就跟人类的意图对齐的话,应该它没有经过微调。就是这里面其实分两个部分。第一个部分功能在做一个微调模型的时候,第一部分很大的工作量就是做这个数据的一个清洗。
然后构造数据集。第二部分工作量就是说生成的结果,然后要跟人类的意图的话要进行一个匹配。这里面可能很多时候是需要一些专家,业内的专家来共同来就是。这个就是类似于就是监督学习这个模型监督这个模型的学习的。所以的话这是这两个过程是非常耗时和耗人力的啊,所以的话这是一个情况。如果你真的在需要一个商用的法律大模型的话啊,这个的话你需要两个部分都做的比较好,这样才能真正投入使用o k这是关于法律这块的一些大模型的这个大概的一个简单介绍啊。
然后我们今天的介绍就到这里。因为这个这个如大家如果有兴趣,可以在自己电脑上,或者说在这个呃谷歌谷歌的这个club上啊,进行一个跑一下试试看啊,可以有自己的一个法律的一个大模型。




