
transformer正在席卷自然语言处理领域,这些令人难以置信的模型正在打破多项n l p记录,推动技术的最前沿。他们被应用于许多应用程序,如机器语言、翻译会话、聊天机器人,甚至是更强大的搜索引擎。现在深度学习领域热衷于transformer,但他们是如何工作的呢?为什么他们超越了之前序列问题的领导者,如循环神经网络g r u和l s t m。您可能听说过不同的著名transformer模型,如bert g p t和g p t二。在这个视频中,我们将重点介绍一篇开创性的论文,attention is all uni. 要理解transformer,我们首先必须理解注意力机制。为了直观的理解注意力机制,让我们从一个有趣的文本生成模型开始,他能够编写自己的科幻小说。
我们需要使用任意输入来引导模型,然后模型会生成剩下的部分。好吧,让我们让这个故事变得有趣。当外星人进入我们的星球并开始殖民地球时,有一个特定的外星人团体开始通过对该国一定数量精英的影响来操纵我们的社会,以保持对民众的铁腕控制。顺便说一下,这并不是我编造的这实际上是由open a i的g p t二transformer模型生成的。感谢hyping face提供了一个很棒的界面来玩,我会在描述中提供一个链接。好吧,这个模型有点黑暗,但有趣的是它是如何工作的当模型逐次生成文本时,它有能力引用或关注与生成的单词相关的单词。

模型如何知道参考哪个单词是在训练过程中通过反向传播学到的。二a类也能查看之前的输入,但注意力机制的优点是它不受短时记忆的影响。r alan的参考窗口较短,因此当故事变得更长时,r a n无法访问序列中较早生成的单词。尽管g r u和l s t m具有更大的长时记忆能力,因此具有更长的参考窗口,但这仍然是事实。注意力机制在理论上并在计算资源充足的情况下具有无限的参考窗口,因此能够在生成文本时使用整个故事的上下文。这种能力在论文attention is all unit中得到了展示。
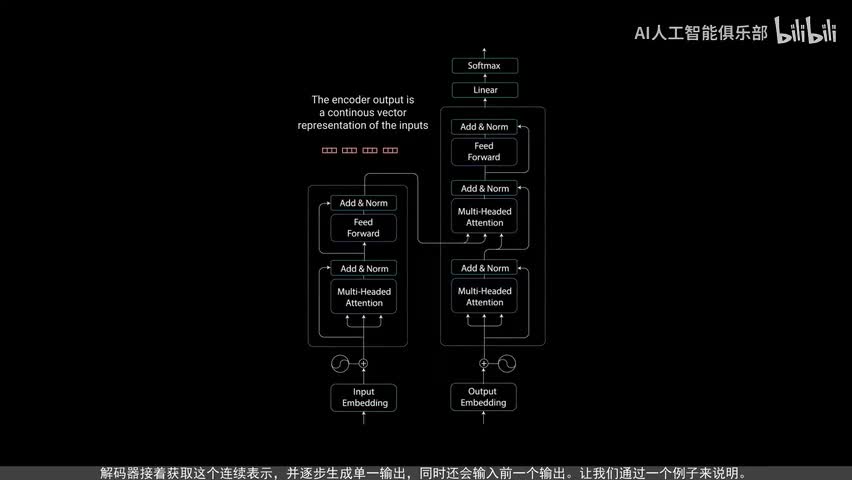
作者在其中引入了一种名为transformer的新型神经网络,它是基于注意力的编码器解码器类型架构。在高层次上,编码器将输入序列映射到一个抽象的连续表示,其中包含了该输入的所有学习信息。解码器接着获取这个连续表示,并逐步生成单一输出,同时还会输入前一个输出。让我们通过一个例子来说明。attention is for unit论文将transformer模型应用于神经机器翻译问题。我们对transformer模型的示范将是一个绘画式聊天机器人。
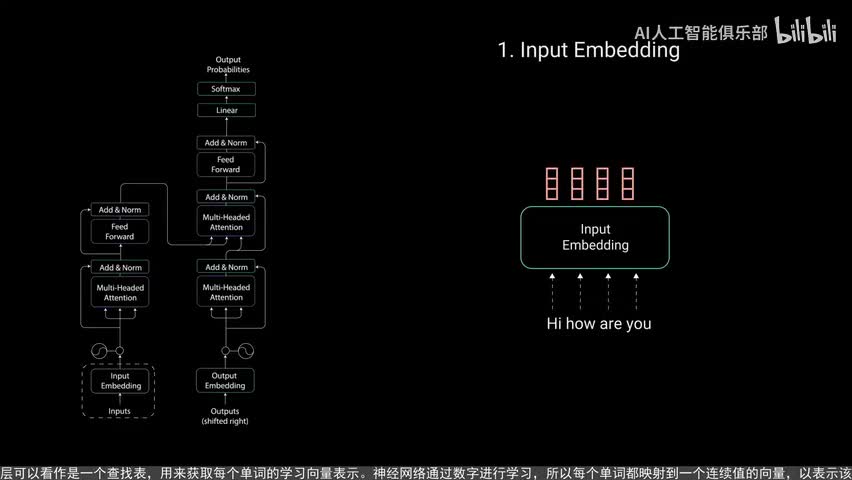
这个示例将接收输入文本你好你好吗?并生成回应我很好,让我们逐步分解网络的机制。第一步是将我们的输入送入一个词嵌入层。词嵌入层可以看作是一个查找表,用来获取每个单词的学习向量,表示神经网络通过数字进行学习,所以每个单词都映射到一个连续值的向量以表示该单词。下一步是将位置信息注入到嵌入中。因为transformer编码器没有像循环神经网络那样的递归,我们必须将位置信息添加到输入嵌入中,这是通过位置编码来实现的。
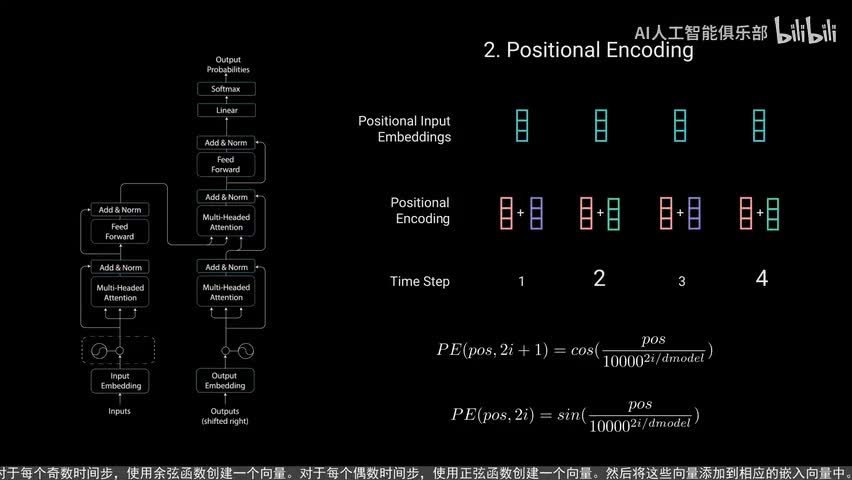
作者们使用正弦和余弦函数提出了一个巧妙的方法。我们不会在这个视频中详细介绍位置编码的数学细节,但这里是基本原理。对于每个奇数时间步使用余弦函数创建一个向量。对于每个偶数时间步,使用正弦函数创建一个向量,然后将这些向量添加到相应的嵌入向量中。这样成功的为网络提供了每个向量的位置信息。正弦和余弦函数被选中,因为它们具有线性特性,模型可以很容易的学会关注。
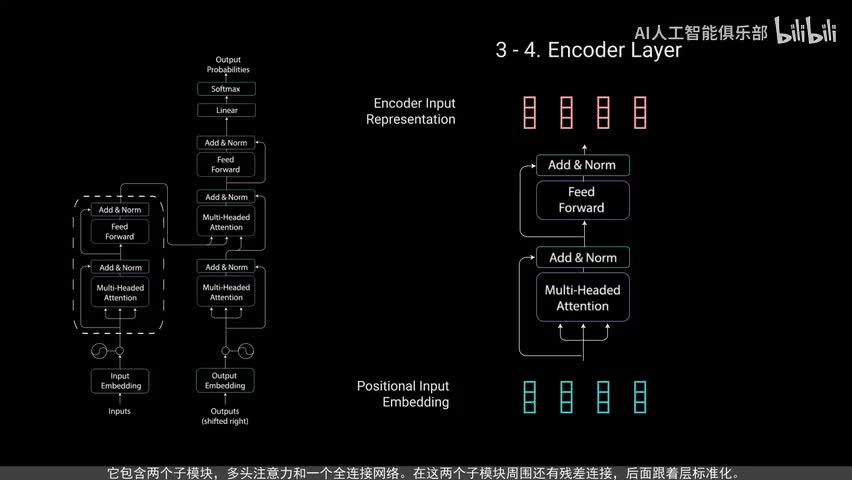
现在我们有了编码器层,编码器层的任务是将所有输入序列映射到一个抽象的连续表示,其中包含了整个序列的学习信息。它包含两个子模块,多头注意力和一个全连接网络。在这两个子模块周围还有残差连接,后面跟着层标准化。为了解释这一点,让我们看看多头注意力模块。编码器中的多头注意力应用了一种特定的注意力机制,称为自注意力。自助毅力允许模型将输入中的每个单词与输入中的其他单词关联起来。

因此在我们的示例中,我们的模型可能会学会将你这个词句好和吗联系起来。模型也可能学到这种模式下的词组,通常是一个问题,所以要做出相应的回应。为了实现自注意力,我们将输入分别送入三个不同的全连接层,以创建查询向量、见向量和值向量。这些向量究竟是什么?我在stacks s change上找到了一个很好的解释,查询键和值的概念来自检索系统。例如,当你在youtube上输入一个查询词搜索某个视频时,搜索引擎会将你的查询词映射到一组件,例如视频标题描述等。与数据库中的候选视频相关联,然后向您展示最佳匹配视频。

让我们看看这与自注意力之间的关系。查询核件经过点击矩阵乘法产生一个分数矩阵。分数矩阵确定了一个单词,应该如何关注其他单词。因此每个单词都会有一个与时间步长中的其他单词相对应的分数,分数越高关注度越高。这就是查询如何映射到键的。接下来通过将查询和键的维度开平方来将得分缩放,这样可以让梯度更稳定,因为乘法可能会产生爆炸效果。

然后对缩放后的得分进行soft m a x计算,得到注意力权重,从而获得零到一之间的概率值。进行soft max计算后,较高的得分会得到增强,而较低的得分会被抑制。这让模型在关注哪个词时更有信心。接着将注意力权重与值向量相乘,得到输出向量较高的soft max得分,会保留模型认为更重要的词的值。较低的得分将淹没不相关的词,将输出向量输入线性层进行处理。为了使这个计算成为多头注意力计算,需要在应用自注意力之前,将查询键和值分成n个向量分割后的向量,然后分别经过相同的自注意力过程。
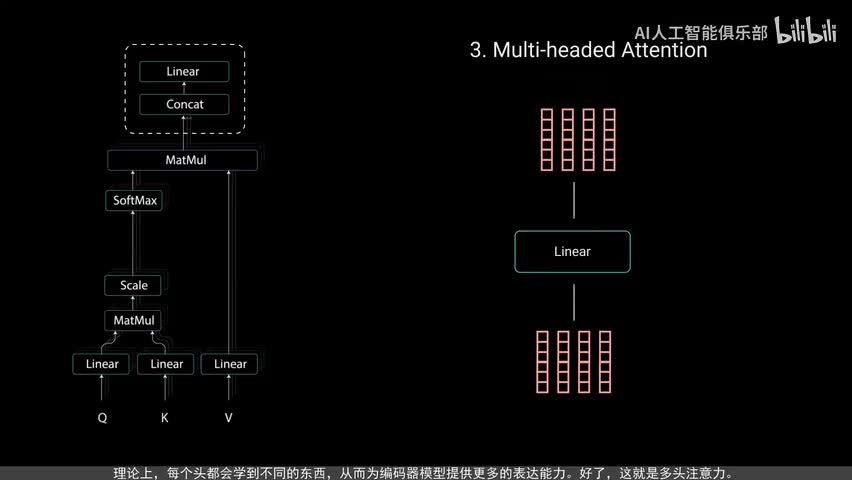
每个自注意力过程称为一个头,每个头都会产生一个输出向量,这些向量在经过最后的线性层之前被拼接成一个向量。理论上每个头都会学到不同的东西,从而为编码器模型提供更多的表达能力。好了,这就是多头注意力。总之,多头注意力是一个模块,用于计算输入的注意力权重,并生成一个带有编码信息的输出向量。只是序列中的每个子如何关注其他所有词。接下来将多头注意力输出向量加到原始输入上,这叫做残差连接。
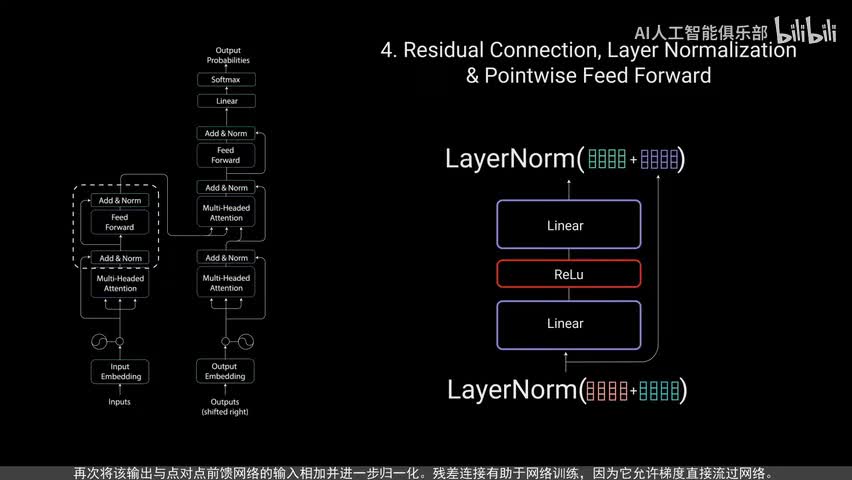
残差连接的输出经过层规异化。归一化后的残渣输出被送入点对点前馈网络进行进一步处理。点对点前馈网络是几个线性层,中间有real u激活函数。再次,将该输出与点对点前馈网络的输入相加,并进一步归一化。残差连接有助于网络训练,因为它允许梯度直接流过网络。使用层归一化来稳定网络,从而显著减少所需的训练时间。
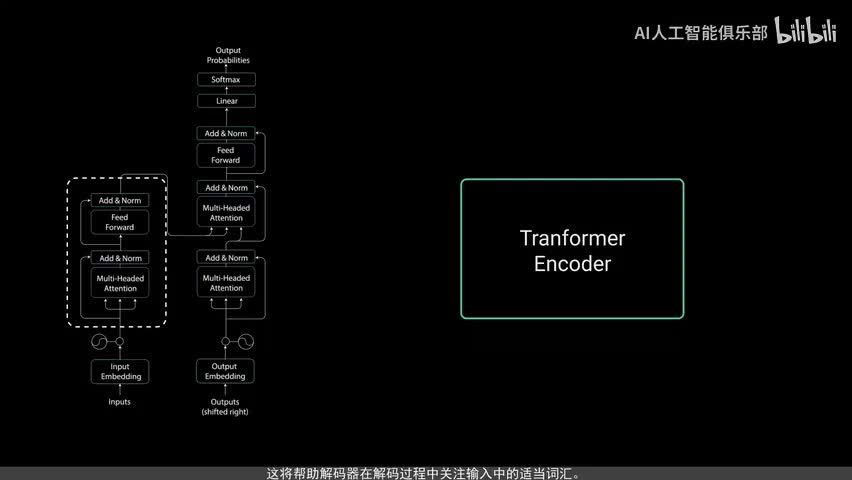
点对点前馈层用于进一步处理注意力输出,可能使其具有更丰富的表达。这就总结了编码层所有这些操作都是为了将输入编码为连续表示,带有注意力信息。这将帮助解码器在解码过程中关注输入中的适当词汇。可以将编码器堆第n次以进一步编码信息。其中每一层都有机会学习不同的注意力表示,从而有可能提高transformer网络的预测能力。现在我们转向解码器,解码器的任务是生成文本序列,解码器具有与编码器相似的子层。
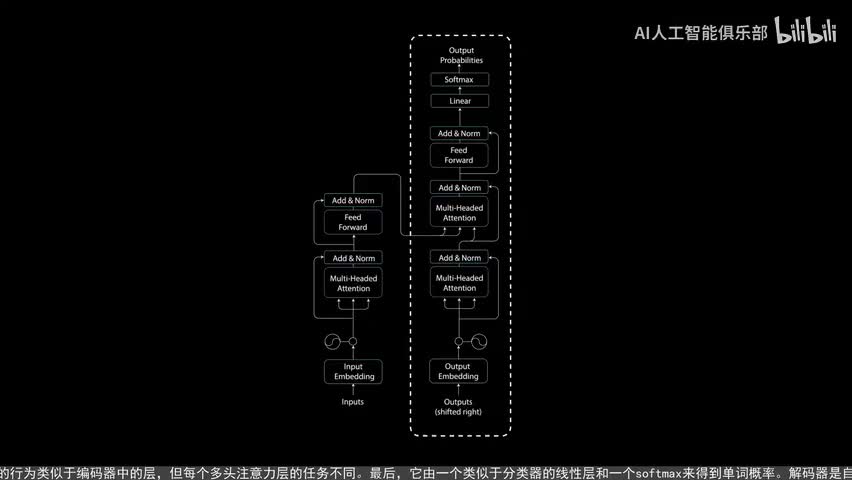
它有两个多头注意力层,一个点对点前馈层,以及在每个子层之后的残差连接和层规一花。这些子层的行为类似于编码器中的层,但每个多头注意力层的任务不同。最后它由一个类似于分类器的线性层和一个sort max来得到单词。概率解码器是自回归的。他将先前输出的列表作为输入,以及包含来自输入的注意力信息的编码输出。当解码器生成一个结束标记,作为为输出解码码停止。
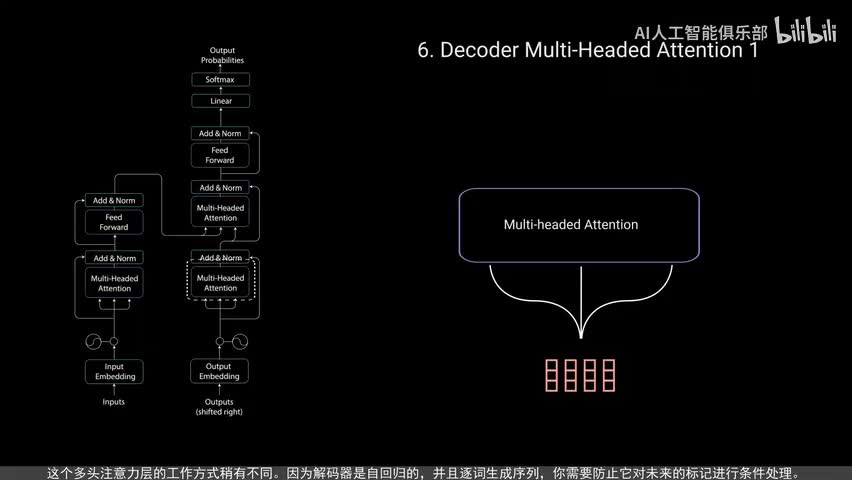
让我们来看解码过程。输入通过嵌入层和位置编码层得到位置嵌入。位置嵌入被送入第一个多头注意力层,计算解码器输入的注意力得分。这个多头注意力层的工作方式稍有不同。因为解码器是自回归的,并且逐次生成序列,你需要防止它对未来的标记进行条件处理。例如,在计算单词m的注意力得分时,不应该访问单词find,因为那个词是在之后生成的未来词。

单词m应该只访问它自己和它之前的单词。对于所有其他单词,他们只能关注之前的单词。我们需要一种方法来防止计算未来单词的注意力得分,这种方法称为must。为了防止解码器查看未来的标记,您需要应用一个前瞻性mask。在计算soft max和缩放得分之后,musk被添加。让我们看看这是如何工作的。
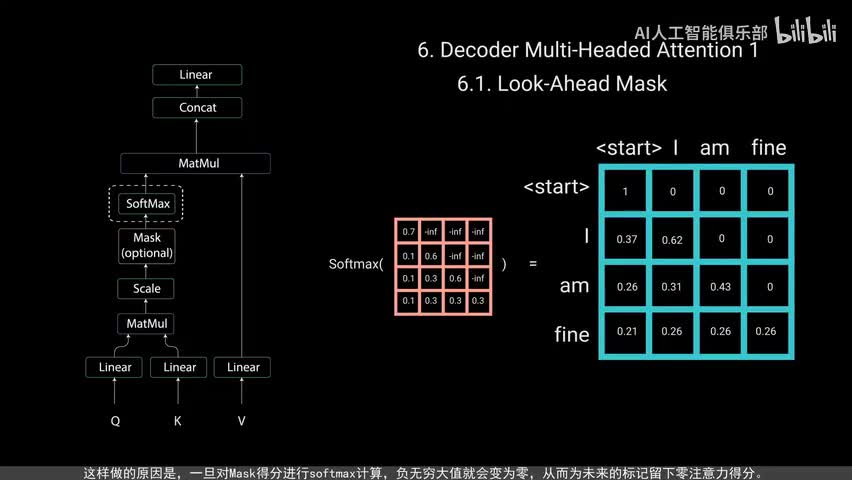
musk是一个与注意力得分大小相同的矩阵,填充零和负无穷大的值。将musk添加到缩放后的注意力得分后会得到一个带有右上角三角形负无穷大值的得分矩阵。这样做的原因是,一旦对mass得分进行soft max计算,无穷大值就会变为零,从而为未来的标记留下零注意力得分。如您所见,单词m的注意力得分对于他自己和他之前的所有其他单词有值,但对于单词find则为零。这实质上告诉模型不要关注这些单词。这种musk是第一个多头注意力层计算注意力得分的唯一不同之处。
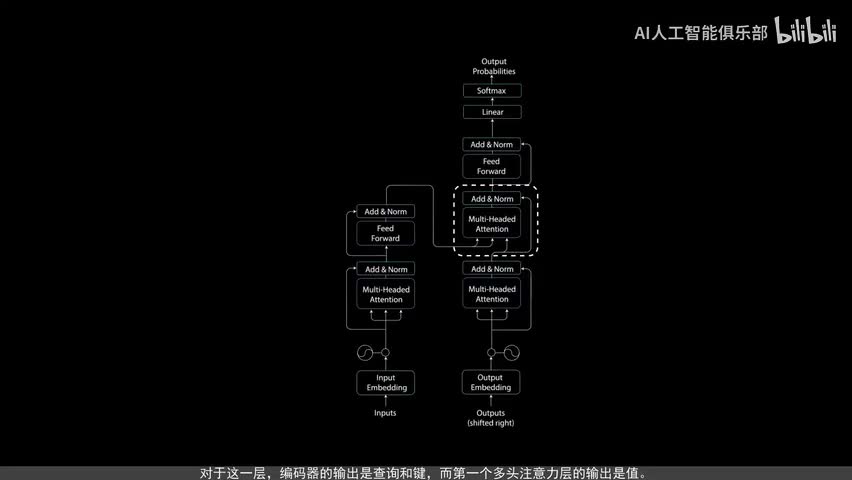
这一层仍然有多个头,musk在被拼接并通过线性层进行进一步处理之前被应用到每个头上。第一个多头注意力层的输出是一个带有掩码的输出向量,其中包含有关模型如何关注解码器输入的信息。现在我们来看第二个多头注意力层。对于这一层,编码器的输出是查询核件,而第一个多头注意力层的输出是指。这个过程将编码器输入与解码器输入进行匹配,允许解码器决定哪个编码器输入是相关的焦点。第二个,多头注意力层的输出,通过一个点对点前馈层进行进一步处理。
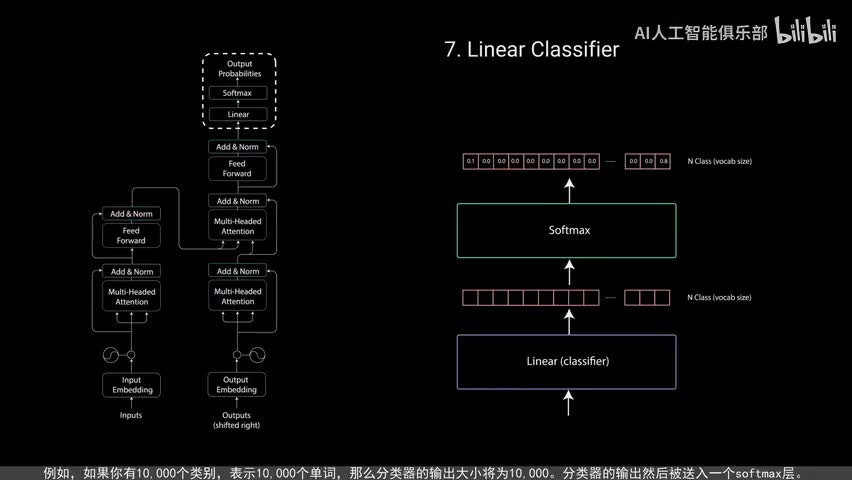
最后一个点对点前馈层的输出经过一个最后的线性层,该层充当分类器,分类器的大小与你拥有的类别数相同。例如如果你有一万个类别表示一万个单词,那么分类器的输出大小降为一万。分类器的输出然后被送入一个soft max层。soft max层为每个类别生成零到一之间的概率得分,我们取概率得分最高的索引等于我们预测的单次。然后解码器将输出添加到解码器输入列表中并继续解码,直到预测出结束标记。在我们的例子中,最高概率预测是分配给结束标记的最终类。
这就是解码器生成输出的方式。解码器可以堆叠n层高,每层从编码器和其前面的层中获取输入。通过堆叠层模型可以学会从注意力头中提取并关注不同的注意力组合,从而有可能提高预测能力,那就是全部了,这就是transformer的原理。transformer利用注意力机制的力量来做出更好的预测。循环神经网络试图实现类似的功能,但由于它们具有短时记忆,transformer通常更好,特别是在编码或生成叫长序列式。由于transformer架构,自然语言处理行业现在可以取得前所未有的成果。




