
上一期视频给大家介绍了人工智能的基本实现思路,并举了一个预测工资的例子,让大家了解了机器学习的过程,即电脑到底是如何自我学习的。我们先来简单的回忆一下,因为电脑的一切运算,其基础都是数学运算,所以任何机器学习的思路其实都是把一个实际问题转化为数学问题。因此为了电脑能够预测或者识别什么东西,我们需要先构造一个数学函数,这个数学函数就叫做预测函数。比如一个预测吃饱的函数就可以写成这样,吃饱等于w个馒头。那么这个预测的计算到底准不准呢?比如一个人吃的馒头数量和翅膀之间到底是什么关系?是吃两个馒头能饱,还是吃三个馒头能饱?这就需要实际去试一下了,一碗就是一碗,两碗就是两碗,不能好。如果预测出来的是两个,而实际是需要吃三个,这其中一个馒头的误差就是损失。而描述这个损失的函数,三减w等于一就叫做损失函数。机器学习的过程就是通过不断的尝试,让这个误差达到最小的过程,也就是寻找三减w等于零时w的值的过程,也就找损失最小值的方法,通常是梯度下降。一旦我们找到了最小误差,就会发现w等于三十,误差最小。也就是机器学到了真实的规律,我们也就能够成功的解决问题了。

好了,复习结束,我们继续。机器学习就是在寻找数据的规律。所以大部分时候它的本质就是把数据投射到坐标系里,然后让计算机用数学方法画一条线来划分或者模拟这些数据的过程。而不同的机器学习方法其实就是使用不同的数学模型来投射数据和划线。从上个世纪到现在,不同的机器学习流派找到了不同的方法,擅长于解决不同的问题。而其中影响较为巨大的有以下几种,线性回归、逻辑回归、k近邻、决策树、支持向量机、贝叶斯分类。以及神经网络。可能有的小伙伴看到这些词就已经头大了,但我保证,虽然这些问题的数学解法对于计算机来说可能有点复杂,但是我们人作为三维生物,从图形角度来理解它的基本原理却是非常简单的。五分钟以后,你死后的人生就再也不会被这些逼格拉满的名词唬得一愣一愣的了。线性回归逻辑回归。

先来看看线性回归和逻辑回归。所谓智能,归根到底就是在做两件事情,一个叫回归,一个叫分类。什么是回归?什么是分类?回归就是预测一个具体的值。比如我预测你的身高有一米八五,体重是七十五公斤,十年后的收入有九十九万。而分类顾名思义就是分类了,比如判断你是男是女,是胖是瘦,是粉丝还是游客。所以线性回归就是找到一条线来预测一个具体的值。比如我们上一期视频中提到的预测收入的例子。而如果我们把预测出来的收入画一条线,比如三万以上算高收入,三万以下算低收入,就会把结果分成两类,这就是逻辑化。是的,你没听错,就是逻辑违规。他的名字虽然叫回归,但他解决的却是分类问题。

线性回归和逻辑回归的算法,就是如何用数学的方式使用损失函数找到这条线的过程。k精灵。再来看看k精灵,k精灵也通常用来解决分类问题。k精灵的基本思想可以概括为八个字儿,物以类聚,人以群分。比如我们现在要把一个网站的用户做一些分类,然后判断一个新用户到底属于哪一个分类,会喜欢什么样的东西,应该怎么做呢?首先我们把现有的用户数据按照不同的维度处理好,比如用户年龄、上网时长、看电影的次数等等。然后把这些维度投射到一个坐标系里。比如这个例子一共三个维度,用户年龄、上网时长、看电影次数。所以就是一个三维坐标系。当然我们也可以完全有更多的维度,只不过我们人作为三维生物,不太好想象四维、五维。所以我们这里用三维来举例子。

现在我们丢一个新用户进去,怎么知道这个新用户是属于哪个分类呢?找到坐标系里和他距离最近的一些用户,比如十个,看看他们大部分属于什么分类,这个新用户就是什么类型,这就是k近邻的算法。下面看决策树。举个例子,我们现在让电脑学会情感配对,一个人是不是被女生青睐,主要与这些因素有关,是否爱学习,是否帅?是否幽默,是否关注新时期公园。但是这些因素在与女神的交往中到底是如何起作用的呢?我们并不知道。决策树就是做这个的。我们把影响因素和结果输入到系统中,让电脑自己去寻找答案。电脑会依次尝试每个节点,计算每个节点的分类纯度。所谓分类纯度,简单说就是如果使用这个节点进行分类,那么分类之后每个分类下的数据一致性有多高。比如如果我们使用染色体特征来分男女纯度是最高的,x y百分之百是男,x x百分之百是女。但是如果我们用是否穿裙子来分类男女,可能纯度就没那么高了不穿裙子的不一定是男生,穿裙子的也不一定是女生。

电脑比较每个因素的分类纯度,然后把它们放到正确的节点上分类,纯度越高的就越接近根节点。最后生出了一颗决策树来,后面我们就可以用这棵决策树来预测新的数据,这就是机器学习中的决策树算法。注意很多不明真相的小伙伴们可能以为决策树是我们预先画好的一棵决策树,然后让机器按照决策树去预测,其实不是。这给你,这是祖传的决策树算法。哇哦,决策树,这一定酷毙了。这个数一定很棒。我马上就要看到了。决策说我们不知道,决策机制顺,让你自己想办法找出来,否则要你干嘛?哦,看啊,没有说我怎么判断。还说自己动手吧。接下来支持向量机s v m。

在上个世纪末,支持向量机就是最牛的机器学习方法。支持向量机理论其实一九六三年就被提出来了,但真正大放异彩要等到三十年后呢。支持向量机有着优雅的数学算法和结构,同时也超级难搞。为了更简单的说明它,我们还是举一个形象的例子吧。比如这儿有一群狗和一群猫,为了避免猫狗大战,现在你需要挖一条沟来把猫和狗狗分开。这条沟你可以这样玩,也可以这样玩,还可以这样玩。但是哪一条沟是最理想的呢?一定是最宽的那一条。是的,越宽的沟越可以更好的把猫和狗分开。小样看你怎么跳过去。现在我们把猫和狗变成两类不同的数据放在坐标系里。

支持向量机就是要通过数学方法找到这条最宽的狗。然后新的数据如果落在沟的这边就是猫,落在沟的那一边就是狗,这条沟就叫做超平面。而沟边缘的狗和猫就叫做支持向量。看到这里,你可能觉得支持向量也没什么大不了的。就是找条线嘛,和前面的线性回归看起来差不多嘛。但这是向量机有一个大招,它能解决线性不可分的问题。什么叫线性不可分问题?给你看一下。这就是线性可分,这就是线性不可分。看明白了吗?坐标系里的一堆数据,画一条直线下去能分成两半叫做线性可分。如果不能分成两半,就叫做线性不可分。
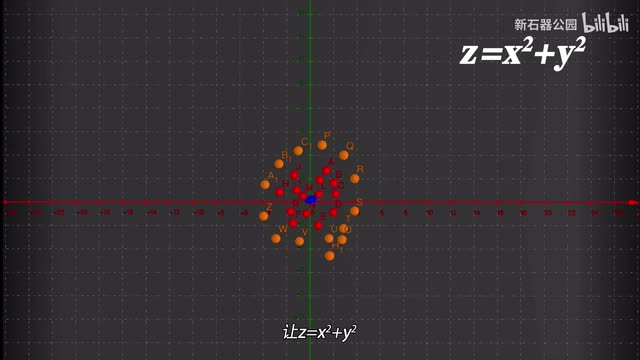
二维以上同理。只不过直线换成平面或者超平面。对付线性不可分问题,支持向量机的办法是升维。这堆数据在二维坐标系里一刀切不开,那我们就加一个维度。比如这个数据,我们没有办法用一条直线把它分开。我们现在加一个维度z让z等于x的平方加y的平方。于是刚才的数据就变成了这个样子。看到了吗?在三维空间里横向一刀给切开了。而刚才那个可以将空间升维的函数z等于x的平方加y的平方被称为核函数。核函数有很多种不同的情况,需要使用不同的核函数,但它的作用就是为了给空间升维,实现线性可分。

朴素贝叶斯。朴素贝叶斯常常用来做分类,比如在已知的某种症状的前提下判断是不是得了某一种疾病,或者已知某些关键词的情况下,判断某篇文章的分类,或者某封邮件是不是垃圾邮件。脑袋大脖子粗,不是大款就伙夫。为了不让大家在先验概率、后验概率里面绕晕,我们就不列贝叶斯公式了,只是举一个简单的例子来说明问题。假设我们的数据发现长得帅的人有很高的概率会一键三连,有很高的概率会发弹幕,有很高的概率会关注新世纪公园。那么如果一个人既一键三连又发弹幕,同时还关注了新世纪公园,那么他就有很大的概率是一枚帅哥,这就是朴素贝叶斯。即根据某一类事物,比如帅哥发生某一些事件的概率,比如一键三连,比如发弹幕,比如关注新世纪公园,来反推当这些事件发生时,他就是有一类事物,比如他是帅哥的可能性。朴素贝叶斯因为比较符合我们的认知规律,所以我们听起来可能觉得平平无奇。可是看他的样子,平平无奇没什么特别,但朴素贝叶斯也是有复杂的数学实践和理论推导的过程的。神经网络。

终于讲了神经网络了。神经网络这个流派其实发源也很早,一开始的时候它的名字叫做感知机。但现在我们往往称它为深度学习。但不管它的名字叫什么,其最基本思想都是模拟大脑神经元的活动方式来构造预测函数和损失函数。因此这个流派最炫酷的名字还是神经网络。既然叫神经网络,必然和人的大脑神经元有一定的关系。单个感知机的算法机制,其实就是在模拟大脑神经元的运行机制。我们看这就是一个神经元,这边是树突这边是轴突。其他神经元发过来的信号通过树图进入神经元,再通过轴突发射出去。这就是一个神经元的运行机制。

现在我们把神经元的数突变成输入值,把轴突变成一个输出。于是这个神经元就变成了这样一张。这张图是不是就很熟悉了?在很多介绍人工智能的文章中,我们都能看到类似的图。而如果我们把它转化为数学公式,那就更简单了,就是下面这样。就这。是的,就这么简单。就这东西创造了划时代的人机大战,以至于吓得人类已经开始考虑人工智能统治人类的事情了。是的,最复杂的事物往往是由最简单的事物创造的。简单的零一就塑造了庞大的计算机世界,四种核苷酸就控制了纷繁复杂的生命现象,一个简单的神经元反射就塑造了我们的大脑。问题的关键不是基本结构有多么简单,而是我们如何使用这个基本结构来构建庞大的世界。

神经元之所以神奇,是因为神经元有一个激活机制。即所谓的阈值。我们知道神经元的每一个树突不断的接收输入信号,但并不是每一个输入信号都能够让轴突输出信号的。每一个数据在输入时所占的权重也不一样。为了说明这点,我们举一个不太精确的例子。比如为了追求女神,你孜孜不倦的采取各种行动。今天帮他修个电脑,明天请他吃顿大餐,后天送她一束花。这所有的行动看起来并没有什么效果,但是有一天你陪她逛了一天的街,女神忽然间就被打动了。这说明了什么?说明女神可能需要一个帮她提包的,别打岔。说明,第一,并不是所有的输入权重都是一样的,在女神那里可能逛街的权重最大。
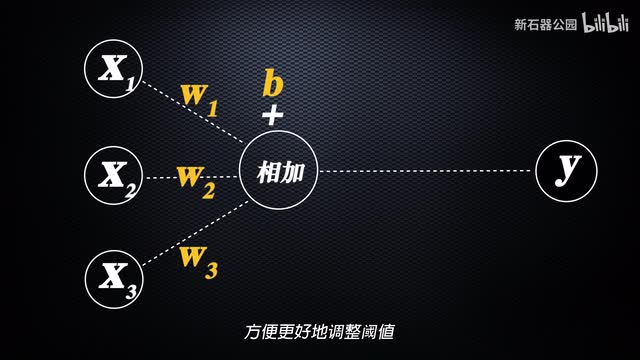
第二,效果的积累不是一个线性渐进的过程,而是量变引起质变的。所有的输入都在某一点之前完全没效果,但一旦达到一个值就忽然被激发了,忽然感觉恋爱了。所以模仿神经元的这种激活特性,我们对刚才的公式做一下改造。首先每个输入都要有一定的权重,于是我们在前面加上一个调节权重的系数w然后后面加一个常数,方便更好的调整阈值。于是这个函数就变成了现在这个样子。然后为了实现激活的过程,我们对输出值在做进一步的处理,增加一个激活函数。比如当x大于一时。输出一,当x小于一时,输出零就是这个样子。这样就可以实现那种类似于忽然恋爱的效果了。但是这个看起来很直男的函数,因为不够圆润。

数学上叫不是处处可打。因此不好处理。最后我们换一个圆润一点的函数,sigma的函数。ok改造完成。现在这样一个简单的函数就可以处理分类问题了。比如可以解决我们刚才提到的女生是否爱上你的问题。单个感知机的实质就是画一条线,把两种不同的东西分开。这个东西看起来很眼熟。是的,我们在线性回归和支持向量机的时候都讲过了。所以我们说单个感知机可以解决线性问题,但是对于线性不可分的问题就无能为力了。

所以一九六九年人工智能之父马文明斯基就抓住这一点,对感知机一步步走。大佬说,感知机无法解决线性不可分的问题,所以连最简单的易货问题都处理不了。要知道,异或运算可是计算机的四大基本运算之一啊。这就是判死刑的节奏吗?冰雪聪明的你听到这一段的时候一定坐不住了。线性不可分问题。这简单呢,刚才我们在说支持向量机的时候已经提到过了,直接用核函数升维啊。嗯你说的没错,但那个时候支持向量机理论也就刚提出不久,还在某个犄角旮旯里落灰呢。直到上个世纪九十年代,蔡贝贝尔实验室从垃圾堆里刨出来大放异彩。所以当时的情况真的是不是兄弟不想帮你,真的是这种。所以可怜的赶之机生不逢时,被大佬打入冷宫,一扩就是十几载。

但是就是这十几年的落寞,让感知机理论涅盘重生,愣是找到了另外一种处理线性不可分问题的方法,并以此确定了自己将来草根逆袭、傲视群雄的独门秘籍夹层。是的,感知机之所以后来变成了深度学习,就是因为它从一层变成了多层。深度学习的深度就是指感知机的层数很多。我们一般把隐藏层超过三层的神经网络就叫做深度神经网络。我们回头看看感知机是如何通过夹层搞定抑或问题的。什么是易惑问题呢?我们知道计算机有四大基本逻辑运算,与、或非、异或。与就是和或者并且的意思,两个都是一就取一或就是或者的意思。两个里面有一个是一就可以取一非就是反过来,是零的时候取一是一的时候取零。而异或就是两者相同则取零,两者不同则取一。如果我们把异或放到一个坐标系里来表示,就是这个样子,原点位置x是零,y是零,于是取零。

x等于一,y等于零,两者不同取一。同理这儿也是一,而这个位置x y都等于一一,所以取零。看到了吗?在这个图上如果我们需要把零和一分开一条直线是做不到的。那怎么办呢?这就要看异或运算的本质了。数学上来说,异或运算其实是一种复合运算,也就是说它其实是可以通过其他的运算来得到。具体来说,就是这样。证明过程太复杂,在这个小小的视频中我们就不费这个脑子了。总之这启发了我们,如果我们能用感知机先完成括号里的运算,然后再把得出的结果输入到另一个感知机里面,进行外面的这层运算,是不是就可以完成异或运算了?是的,你猜的没错。我们设计两层感知机。第一层感知机做括号里的运算,最终结果输入到第二层感知记忆就可以完成第二层的运算。

然后抑或问题就这样神奇的解决了,解决问题的同时还顺带解决了线性不可分的问题。这就厉害了,你发现没有?本来感知机是直的,你给它加了个层,愣是给弄弯了,这说明什么?说明没有什么是弄不弯的。说明不管多复杂的数据,通过加层的方式就可以拟合出合适的曲线,将它们分开。夹层就是函数的嵌套。理论上来说不管多复杂的问题,我们都可以通过简单的线性函数组合出来。因此理论上来说,多层的感知机能够成为通用的方法,跨领域的解决各类机器学习的问题。至此,神经网络终于拨云见日,迎来了自己理论的大发展。一九八二年,循环神经网络的雏形被提出,一九八九年,卷积神经网络理论诞生。但因为当时的硬件条件和数据量都不够,神经网络还没有办法大杀四方,再加上当时还存在梯度消失等一系列问题,所以进入九十年代,当支持向量机终于上岸,开始锋芒毕露之后,神经网络就再一次陷入了低潮。直到二零零六年之后,随着大数据和硬件条件的完善,随着新的激活函数的应用,神经网络终于王者归来,开始了自己吞六合并八荒,横扫天下,大杀四方的王霸之路。

不过这一次他换。叫做深度学习。二零一二年,使用c n n模型的alex mac在图像识别大赛image map中碾压支持向量机机,宣告了深度学习王朝的到来。二零一六年使用深度学习算法的阿尔法狗,在人机大战中将以事实挑落马下,一使天下震惊。当此时,神经网络譬如众生,终于可以说出那句话。我不是针对什么,我只想说在座的各位都是垃圾。那么王者归来的神经网络睥睨众生资本到底是什么?它又是如何通过感知器的叠加来解决复杂的问题?




