刚接触ai绘画的你是不是也有碰到过这样的情况,在各种提示词网站上看到别人的a i画出来的图一张比一张好看,可当你把提示词一抄回来,信心满满的是完蛋。别灰心,其实不是提示词的毛病,也不是a i的问题。这里是南美一个不会画画的设计师,兴趣爱好是做一些美容学的。会的教程。你现在正在收看的是我们的stable function零基础入门课的第四节。对于初学者而言,这种货不对版的问题有很大概率。出在你的模型上,模型很重要吗?之前我没有针对ai绘画的原理进行过一个非常详细的讲解,里面就有提到ai之所以能满足你的各种奇奇怪怪的需求,其实来源于他对很多其他画作的深度学习。我们也常常把拿图片给a i学的这个过程叫做位图。学习的内容不光包括对具体事物的形象描绘,还包括对他们的呈现方式。

说通俗一点就是画风。如果我们喂给ai的图片都是二次元风格的那他的世界就是二次元的。你让他画人画风景,他都会画的像一幅二次元插画。但如果你会给a i的图片都是真实世界里的照片,那他就绝对画不出所谓的画来,因为他根本没见过画。我们会给a i图片以及a i针对他们做学习的这个过程,最后会被打包整合到一个文件里。他们就是ai绘画中的模型了,使用不同风格的模型,你就能做出不同风格的作品来,所以你应该也知道为什么ai绘画却能做出堪比真人的赛博科sr啊。我们之前展示过的这些不同风格的作品,其实就是利用不同的模型描摹同一个画面的结果。对于一幅ai绘画作品而言。提示词加模型加参数设置。

只有当这三者都被完全确定下来的时候,它才能产出你想要的内容。看到这里你应该也知道了当你抄了一组式子过来,却发现做出来的东西完全不一样的时候,游泳大概率就是你使用了和原作者不同的模型。在前面的几节课里,我们已经详细的解析了stable diffusion安装使用全过程,以及通过提示词进行文生图,通过图片进行图生图的方法。这节课我都会向你简单科普它的模型概念、使用方法、下载渠道和加载时的一些注意事项。而在这期视频的结尾,我还会向你推荐一系列我常用的高质量模型,与利用它们生成图像时的关键提示词。拥有了这些模型,你才是一个精通各种不同风格的全能型赛博画手。所以请你要看到最后。课程内容很单一很充实,我建议你先收藏一下再开始学习。准备好,就让我们开始这节课的模型探索之旅吧。
我们先从文件的基础构成上认识一下这些模型文件吧。在s d里我们刚刚说的那种用来存储大量学习信息的模型,一般被存储在这个models里的stable diffusion tion文件夹内。如果你下载了新的模型文件,只需要把它们复制进来,就可以利用s d去加载。这个模型有一个固定的称呼叫做check point point。检查点或者关键点模型。想玩游戏的朋友可能比较好理解,一个大的模型训练起来是很消耗算力的,就好像我们在游戏里每隔一段时间需要存档一样。他们运算到某个关键位置的时候,就会建立一个关键点,保存已经运算的部分以后,方便回滚和继续计算,这就是check points的来源。这个保存出来的检查点就可以用来支持我们的a i阅片和出图。也正是基于这种检查点特性,大部分模型都拥有不断往下迭代更新的能力。
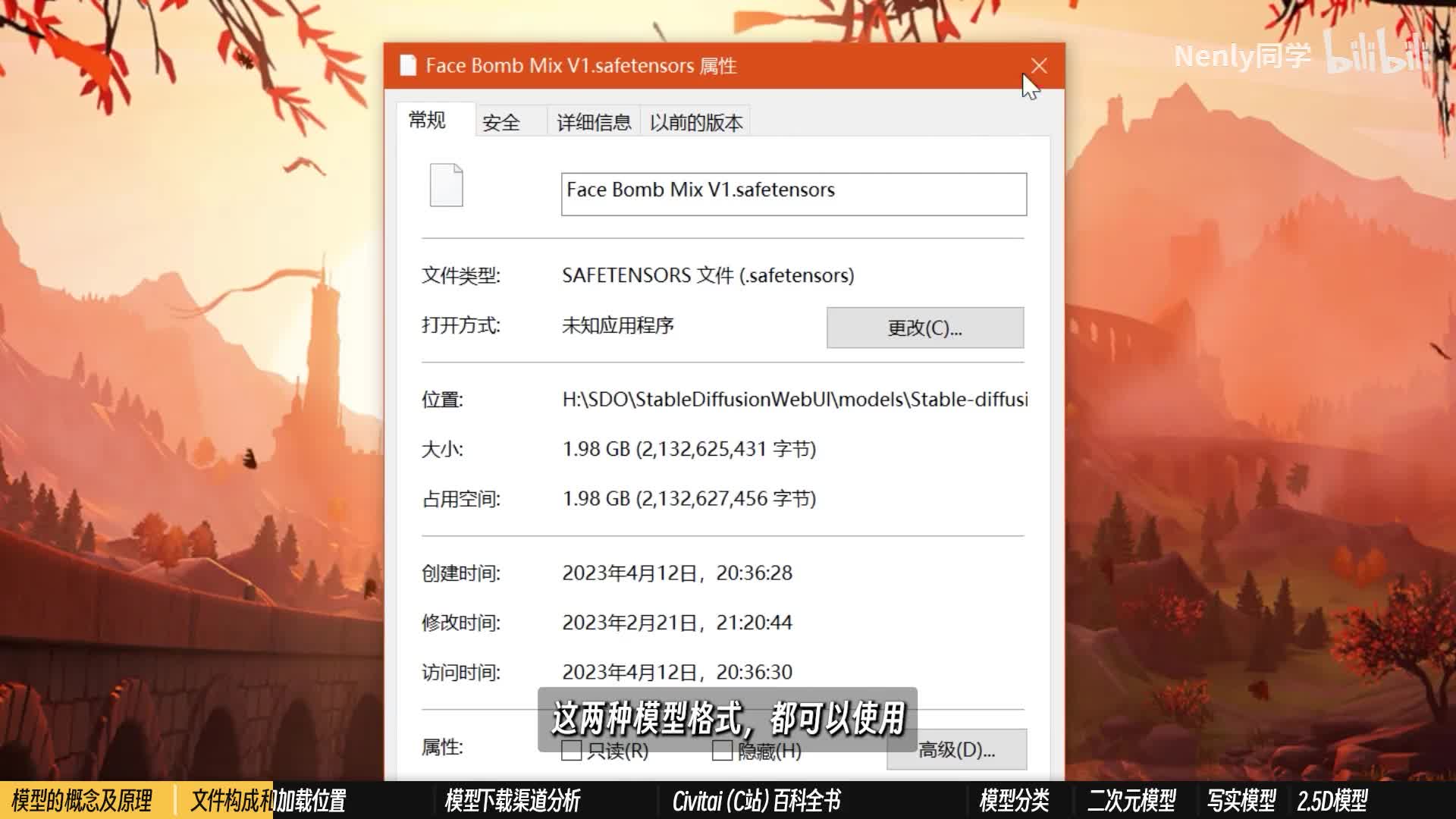
例如我们之前使用过的深渊局,目前最新的版本是a o m三。a三出图效果更为精致,check point很大,常规情况下占用内存在三到七gb之间。它的文件名后缀通常是点c k p t,我们也常把这种几g b级别的模型叫做大模型。还有一种格式的大模型,后缀是点safe tensor,占用空间会比较小一点,通常一到两g b就可以搞定,是训练者们为了使模型变得更加可靠高效而专门开发的。这两种模型格式都可以使用,在目前阶段对你而言可能区别并不大将它们下载下来以后,都一股脑拷贝到这个模型文件夹里就好。拷贝完成之后,你就可以在s d左上角的选项里加载模型文件了。如果你是在web u i打开的状态下添加自己新的模型,那需要先点一下右边这个刷新按钮,这样新的模型才能被显示进来。模型是否成功加载,还得看命令行里面的加载进度,跳出这样的提示才算加载成功。模型没加载好,急急忙忙的提前开始生成,可能也会导致报错。
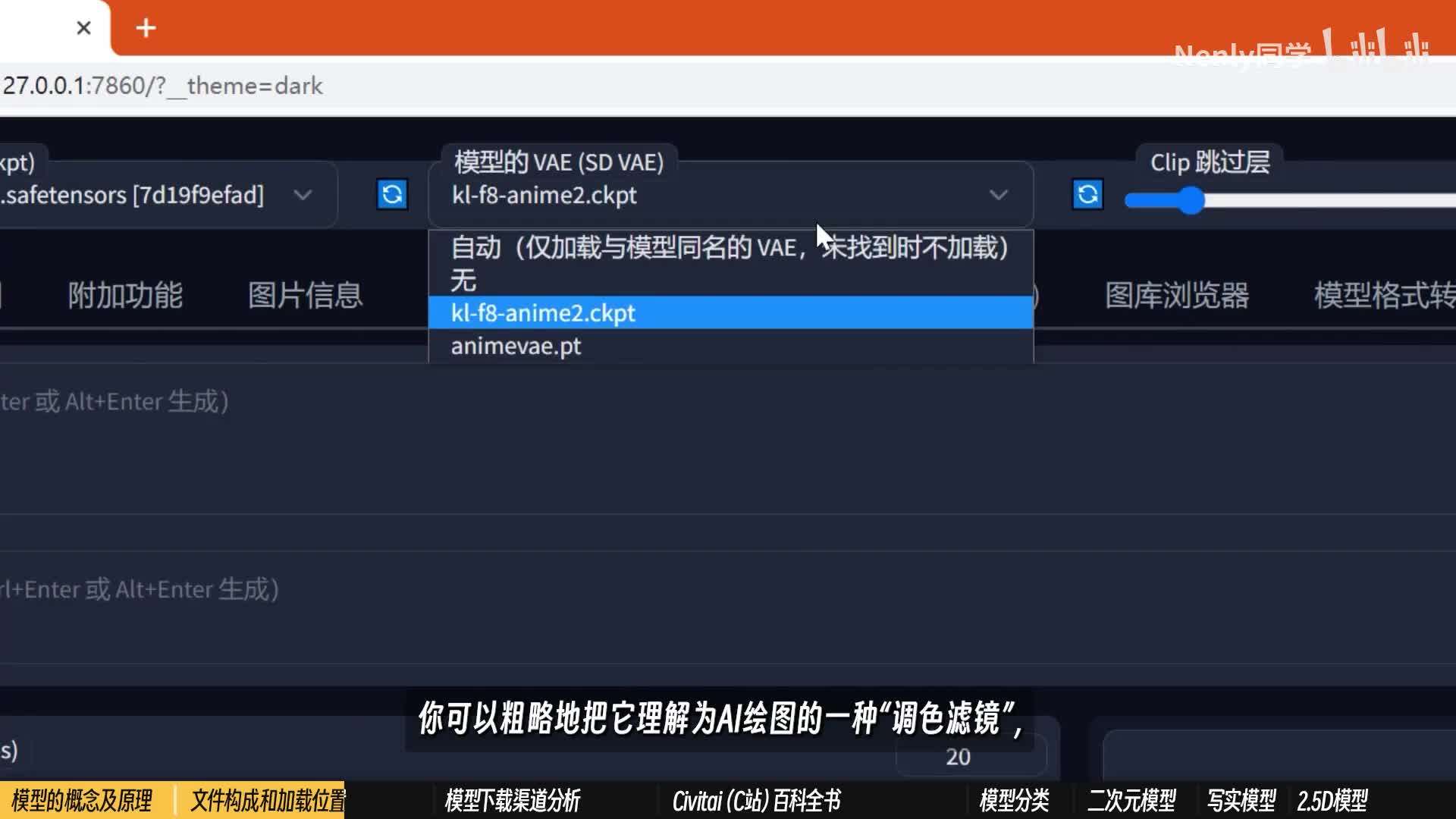
如果你使用的是秋叶的启动器,还可以借助启动器的一个相关选项对模型进行管理下载。当掌握了后面的一些下载途径和渠道以后,你就可以像一个老司机一样直奔对应文件夹了。本质上并没有区别。值得一提的是,在模型选项的旁边有一个叫做v a e的选项。v a e的全称叫做变分自解码器,负责将加噪后的浅空间数据转化为正常的图像。从使用属性上看,你可以粗略的把它理解为ai绘画图的一种调色滤镜,因为它最直观的影响的东西就是画面的色彩质感。目前多数比较新的模型其实都已经把v a e整合进大模型文件里了,但也不排除少数没有的。例如这个facebook mix模型不加载v a e的情况下,出图就会发灰发白。多数模型作者会考虑到这一点,并且推荐他们认为合适的v a e,也有一些普遍适用于大多数模型的v a e。
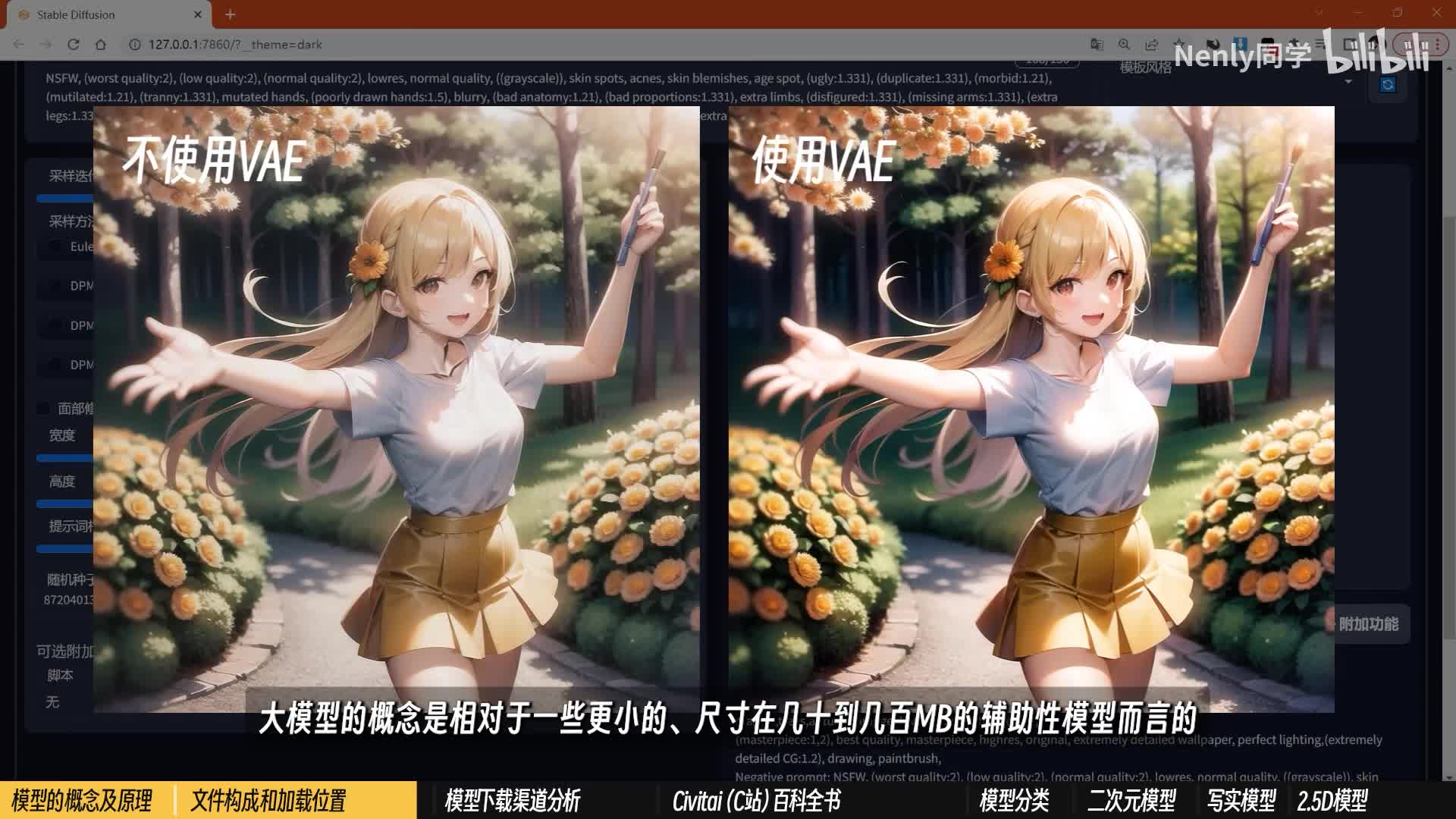
例如签约包里默认提供的这个k f f八n零这些v a e文件,同样可以在后面我所说的一系列渠道里搜索到。下载下来后缀一般是点p t也有sick tensor格式的v a e。他们的安置地址在这个同事model文件夹下的v a e里面。你可以把一些针对特定模型v a e改成和他们的check check point一样的名字。然后再在v i e选项这里勾选自动,这样就可以针对不同模型自动切换。v a e大模型概念是相对于一些更小的尺寸,在几十到几百m b的辅助性模型而言呢,其实ai绘画里的模型也不止check point一种,例如常被我们用于画面微调的的hyper network。优化画风的embedding和固定特定人物至此特征的laura,这些概念我们会在第六课里再做详细梳理。所以这些模型要在哪里获取呢?很多关于ai绘画的教程并没有提及模型,因为在一些应用中,模型并不需要时空则操心,例如mid journey,它提供的模型数量比较有限。大部分使用者靠默认模型也可以实现不错的绘图效果。

stable diffusion官方也发布了诸多一点四二点零等若干版本的开源模型,但使用它们生成的图像风格比较单一且缺乏细节,说白了就是有点糙。因此市面上绝大多数s d使用者用来做图的模型。其实都是由其他个人训练并发布的模型,俗称思路模型,这个思路的叫法也很有意思,和我们提过的那个魔法师和念咒的比喻一样,大家会把训练ai学习图片生成模型这件事情叫做炼丹。如果你完整体会过一次训练模型过程,就能体会到这个称呼的精髓呢。炼丹有一定的技术门槛和硬件需求,因此只有拥有一口好的炼丹炉,才能当炼丹师。如果你想看到一期如何训练模型的更为专业的教程,可以在弹幕敲个一。但这也不能怪他们。由于版权问题,官家的炉在学习的素材来源及尺度上面。都有着比较大的约束,所以利用思路作画出图是目前的主流趋势。
但它的版权的确存在一些争议空间。这个就不用翘一了,是我已经计划好要用一期视频和大家好好聊聊的了。言归正传,目前ai绘画圈子里的主流模型下载网站有两个,一个是hugging face,俗称爆脸。它是一个允许用户共享a i学习模型和数据集的平台,包含的内容非常广,不仅仅包括ai绘画,还包括很多其他ai领域的东西。也因此呈现出了比较高的专业门槛,第一次接触难免会令人觉得有些头大。在最上方的搜索栏里输入stable diffusion,你可以直接下载他们发布的历代官方模型,而在左边的筛选栏里点亮text to image的标签,你就能筛选出其他用户发布的那些主要被用于ai绘画的文生图模型了,其中就包括很多老牌知名模型。例如wifi diffusion,anything dream shape er等点进去以后他们会有一个model card,相当于是这个模型的介绍页面。看得懂英语其实也挺清晰的,看不懂就再求助一下翻译软件。如果要下载,切换到第二个标签,就是这个files里。
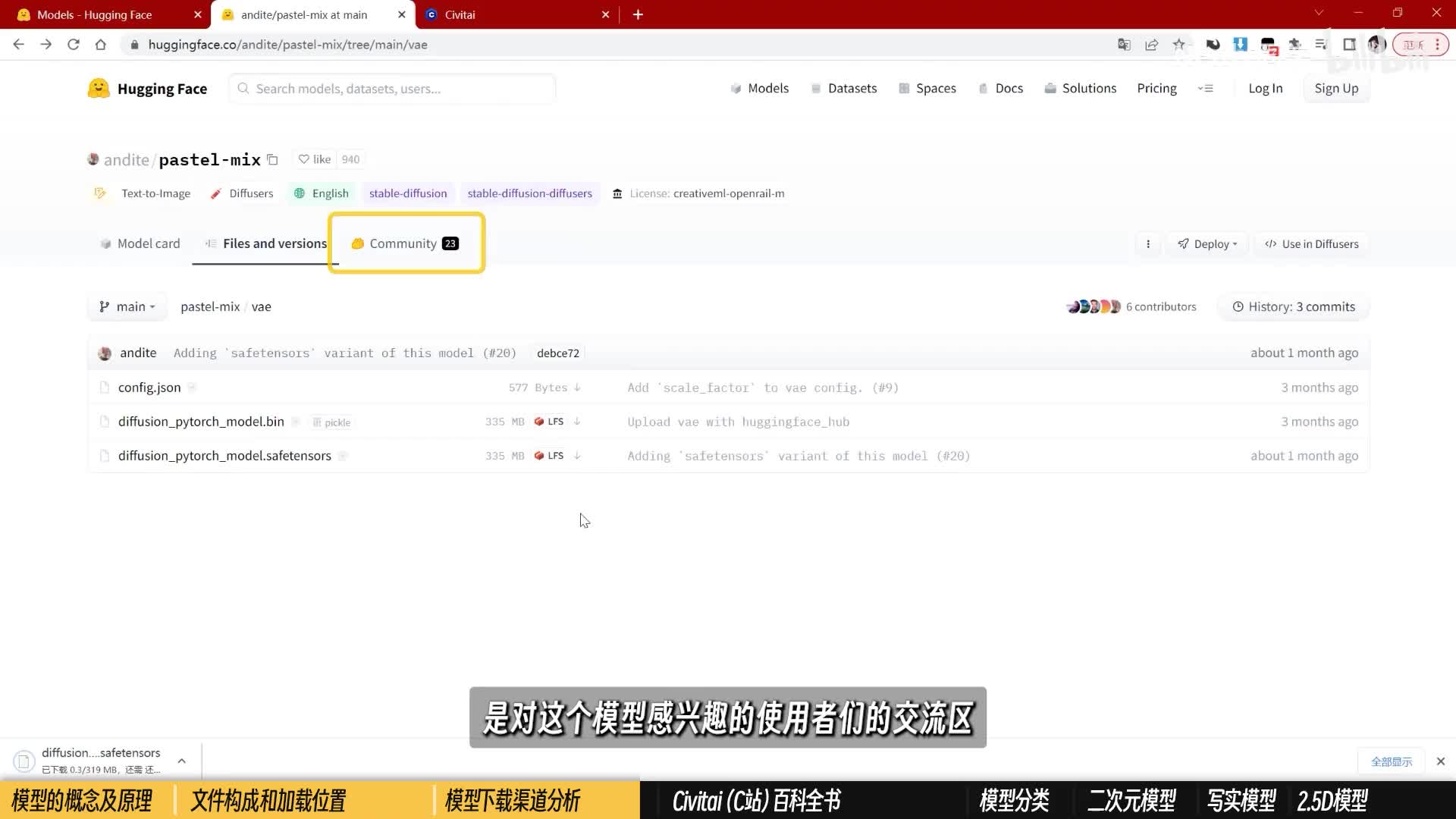
制作者们会把文件源代码等基于需要放在不同的文件夹里。在了解了刚刚关于模型文件的基础知识,你应该不难找到你想要的东西。比如大模型就去这个safety checks里找,b a e就在下面的v a e文件夹里找,点一下就可以开始下载了。其他你看不懂的内容可以不用下。右边这里还有一个community的选项,是对这个模型感兴趣的使用者们的交流区。如果你有什么建议或者碰到什么bug,可以来里面看看有没有解决的方式,或者点这里发起一个讨论。如果你听说了市面上一些比较知名模型,苦于找不到地方下下载,都可以来点点搜一下看看。第二个网站叫做c vi e俗称c站。如果你之前不曾了解过c站,那恭喜你现在捡到宝了。
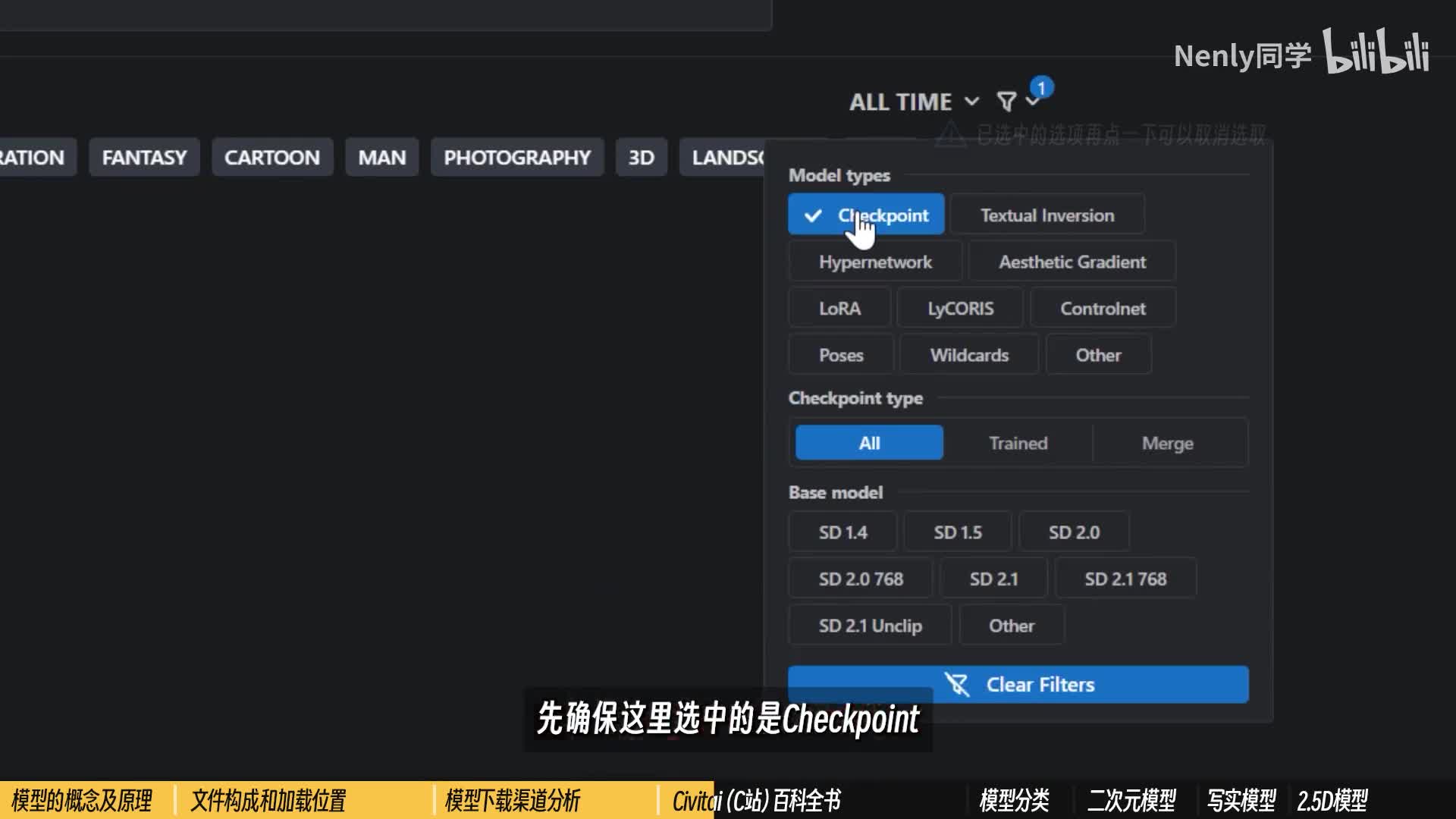
它是一个彻头彻尾的ai绘画模型分享平台,所以你在里面看到的各种模型的展示是非常图像化、具体化的。在c站上访问下载模型均不需要注册,我也推荐大家在不注册的情况下使用在左上角的模型排序这里切换到highest rated或者most download。你就可以看到目前时下最火热的一系列ai绘画模型了,你可以进一步的对这些模型做细分筛选,一是基于类型,点击右上角的小漏斗按钮,第一个选项就是基于我们刚刚所说的那些复杂的模型类型做区分的。如果你要找大模型,先确保这里选中的是chat point,以后要找其他类别的模型。也是在这里做区分。第二个模型类型里的train的merged,其实可以不用太在意。train的模型就是指由原作者基于图像一点点训练出来的,是一手的单基于模型数据特性。为了获得一些更好的呈现效果,有些模型创作者还会把几个模型融合到一起,创造出一个新的模型,这种模型就是所谓的融合模型了,算是一种把几颗蛋捣碎了再回锅练出来的单。他们的名字一般也会叫做什么什么mix,但他们在使用起来的时候,达成效果的方式是一致的。
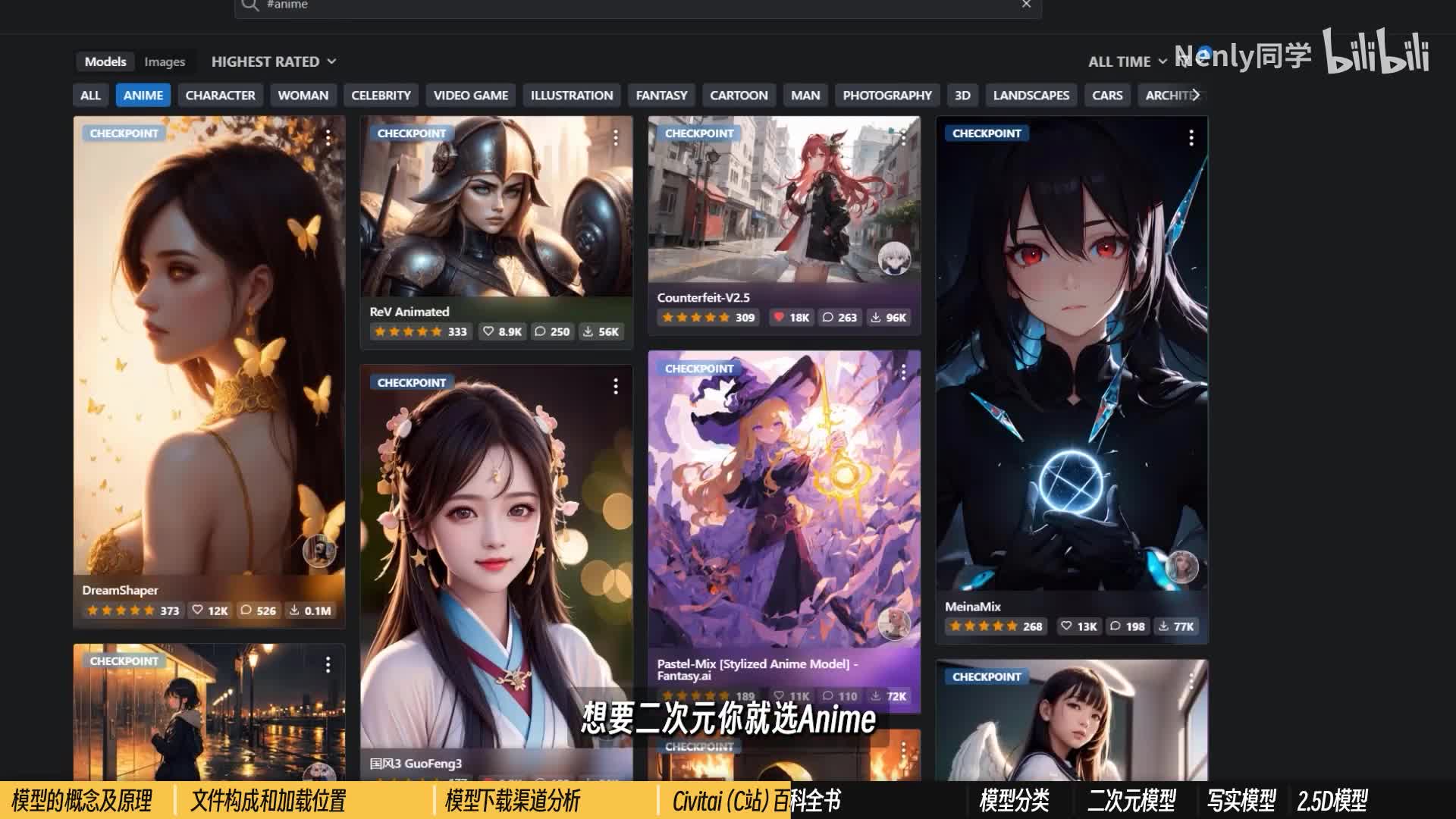
默认情况下我们维持默认的哦一视同仁即可。至于下面的base model则指的是模型训练过程中基于的底膜,这个同样是进阶的模型训练你需要去考虑的东西了,我们维持默认即可,第二种筛选方式则是基于特定的类型去筛选的,注意到上面这一大排小标签了吗?它们代表着一些不同的风格、类目和内容方向,选中其中的一个c站,就会给你自动做一个筛选。想二次元你就选anime,想要骗真人的就选photography,是非常灵活的。点击其中的一个模组,下载按钮就在右边。如果有多个不同的版本,你还可以到下面选择下载哪个。但一般我都推荐下最新的。下面的模组介绍就相当于暴敛里的model car。这些信息在做图之前你最好都要仔细阅读一遍。因为作者往往会从很多个方面指导你该如何使用这个模型。
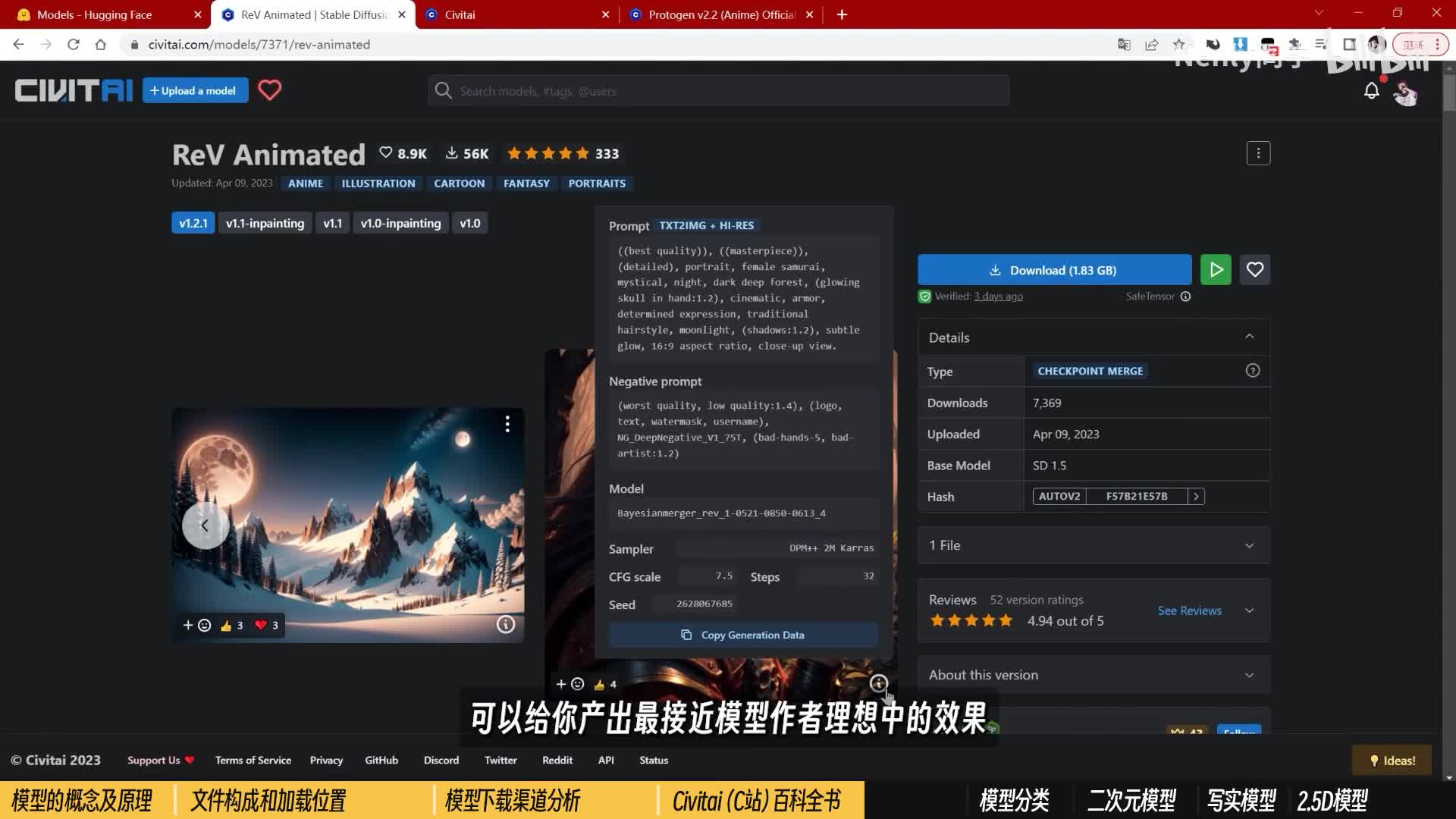
例如这个ref animated,作者就很贴心的为你标注了适合的风格、关键词、分辨率以及v a e。点击都可以直接跳转下载。c站还有一个更大的好处,作为一个模型分享网站,它不光分享模型,还分享用这些模型做出来的作品。首先在每个模型的最上方都会有一系列作者使用这个模型生成的力度。点右下角的信息按钮就会跳出对应的提示词、采样方法,甚至是随机种子。如果你要抄作业,那这份就像是一个参考答案一样,可以给你产出最接近模型作者理想中的效果,往下翻一翻,你可以看到c站其他用户上传的基于这个模型产出的图片,里面的大部分同样也会附上提示词和参数。如果你有喜欢的模型。那可以直接到模型里找别人做的作业,这样就像抄你同桌的作业一样,绝对不会出现自己抄一份回来面目全非的情况了。感染后的c站在首页也直接多了一个image页面,你可以点进去,像其他网站一样,欣赏那些高赞好评的ai绘画作品。
并找到他们的具体使用的模型。就我大半年使用下来的经验,这两个网站是最适合新手找模型下东西的地方了。我们后面会有不少用到他们的地方。因为他们的服务器在国外不是很稳定,所以偶尔会出现连接不上的情况。目前国内有一些分享模型的网站,但我并不打算给大家推荐。因为他们之中的很多网站在搬运的同时并未明确注明原作者各种信息,并且有使用这些开源的分享进行牟利的倾向。在这里我也郑重建议大家不要为了任何的模型进行付费。但在这个系列课里,我所提及介绍的所有模型,我都会为大家分流一份,并附上出处放在学习资料里。如果大家有需要可以自取,有条件呢也别忘了去对应的站点评价支持一下原作者。
讲到这里,我想你对于ai绘画里的模型使用应该已经没有什么问题了。市面上的ai绘画模型基于它的出图特点和风格倾向,目前会被大致的划分成如下三类。一种是偏漫画插画风的,具有比较鲜明的绘画笔触质感,为了方便解释,我们就叫它二次元的模型了。另一种是偏真实系的,拟真化程度高,对现实世界还原强。介于这两者之间的还有一类,最后还原出来的质感效果,类似于一些建模软件里能制作出的三维渲染图。不如平面的那么平,也不如真实的那么真,但却很接近目前观众对一些游戏和三d动画的想象。大家一般把它们叫做二点五d类的模型。这三类模型你分别可以借助我下面列出的一些关键字进行筛选或搜索。在我使用s d作画的小半年时间里,我运用了不下五十款不同的模型。
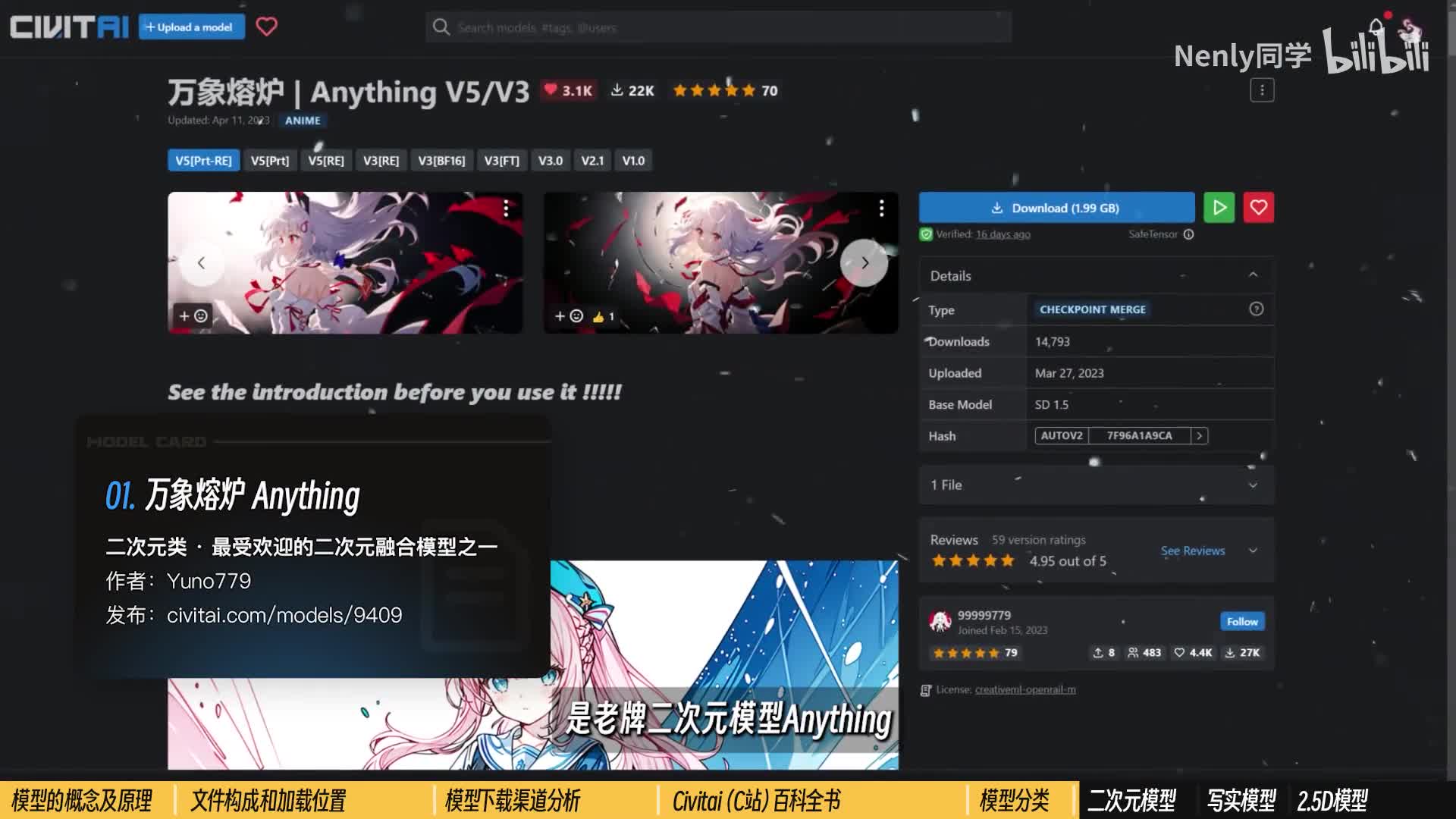
其实模型这种东西是真的没有绝对的优劣好坏之分的。作为一名创作者,我只能说哪些模型更符合我的口味,或者更适合让我用来实现某些效果。但目前有一些模型在江湖上流传的比较开且广受好评,所以我在每种类目里挑选了三个非常具有代表性的模型。给大家逐一介绍点评。作为一名初学者,在早期拥有这三乘三等于九,加上一个原厂模型,共十个模型的新手礼包,上路应该就没有什么障碍了。先来说说二次元的模型吧,第一个要推荐的是老牌二次元模型anything,它是最受欢迎的二次元融合模型之一,针对二次元风格拥有非常好的效果,对其诗词的要求并不过分刁钻。用简单的词语也可以创造出不错的效果,可以利用它打造出非常接近于类似动漫插画、角色立绘等的画面风格。第二个是一款我非常喜欢的二次元插画风模型counterfeit,同样是一个泛用性很广的插画风模型,细节还原度高,可以生成出各种包含复杂室内外场景的绘画作品。在想怎么给他做一个更体面的介绍时,我确实有些词穷了。

不如直接放图吧。如果你喜欢这种精致感溢出屏幕的画面风格,那它一定是你要去尝试一下的模型之一。第三个是一个受欢迎且非常有特色的漫画插,画风魔性dream like difficulty。正如其名,在合适的提示词和画面设计的情况下,它能够为你打造梦幻般具有幻想色彩的画面和作品。同样我觉得一些合适的作品图可以帮助你更好的理解这个模型的特点所在,用它创作一些超现实的魔幻主题作品是非常刺激的。在ai绘画领域,富有特色的二次元图像生成模型实在太多了。一些我非常喜欢但没有上榜的模型,也是我很想向你一一介绍的。包括大家早就体验过的深渊橘,特立独行的dream sapper,笔触细腻的maya mix和sighs mix,同样很有魔幻风味的pascal mix,以及复古油画质感的dash for printing的。如果你需要一些关于这些模型的专题介绍,那请一定要把想看两个字疯狂的刷在公屏上。

接下来是真实性的模型啊。deliberate是目前最好用的真实性模型之一。我觉得它像是一个超级升级版的s d官方模型,你可以使用它生成非常具有真实质感的图像。像这个机器猫,它的每根胡须和齿轮零件都是清晰可见的。deliberates s在图片生成的自由度上也非常高。非常适合设计师和艺术家的头脑风暴。在c站的创作区稍加浏览,你就可以看到它的各种出色应用。如果你希望这种写实的质感来的更朴素踏实一点,那realistic vision这个模型可能是你需要的。它不光可以用来做人像,还可以用来生成食物的食物动物图片。

一些创作者也会拿它整整花活,做些非常具有真实感的假新闻照片,估计挺合适了。在生成真实系人像方面,还有一个很好用的模型,就是这个low fire模型。它的全称是limitless originality,free from interference, 无限创意不受干预。我个人认为它的人物面部处理比前两个都要更加精致。无论是男生还是女生,西方面孔还是东亚审美,是一款能真正实现照片级人像输出的大模型。还有一些其他的非常知名的老派真实性模型,大家可以自行通过其他途径进行了解。最后是二点五d风格的模型。在我能给大家介绍的模型里面,表现最好的应该是这个never ending dream模型了。他在造人方面有自己的一套独特审美,被许多创作者拿来结合laura进行动漫游戏角色的二次创作,它提供真实感,恰到好处的满足观众对二次元世界的想象,却又不至于在真实世界里产生过分的陌生感。

第二个模型proto gon其实它可以算是一个真实性模型,但它在实现效果上的弹性给创作带来了很多额外的自由度。你可以使用这个系列的模型做出一些非常贴近真实效果的照片,也可以用它描绘非常具有魔幻感的超现实画面。最后一个模型,国风三。特别的需要强调一下,这个模型应该是由我们国内的作者训练生成的。整体质感偏了二点五d也就是三维动画渲染的质感,非常适合用来生成古风的人物服饰场景,目前也在c站排行前列,实属文化输出了,产出的女性人像外貌也非常符合国人审美。结合其他的一些loa模型,还能创作水墨风、小人书等非常具有特色的作品,推荐你尝试一下。看完这些模型,我想你应该能意识到模型赋予ai创作的无限可能性了。还有更多的模型是我们今天没有办法介绍完全的。而除了这种基于某一个风格大类训练的模型以外。

还有一些比较小的模型可以帮助你实现特定类型的图像绘制。例如富有魔幻感的场景,富有现代感的建筑,甚至是富有高级感的平面设计。上述我提到的所有模型你都可以在c站找到。如果你因为一些原因没法下载,也可以考虑使用我分流出来的文件。以上就是本节课的所有内容了,关于模型我们算是讲明白了吧,真心希望这期教程对你有所帮助,也请大家不要吝啬手里的三连。不花钱的硬币,却可以给我带来比金钱更宝贵的满足和成就感。下一课让我们一起探索stable division里的一些进阶功能。了解使用高分辨率修复和人工智能放大技术的方式,解决新手出图慢出图湖的难题。感谢你看到这里,这里是能力,我们下期再见面,拜拜。




