
i p adapt是腾讯ai实验室发布的一款新的stable diffusion适配器。i p adept将输入的图像作为图像提示词,类似于你的journey跟阿里的电图,可以用于复制参考图像的风格、构图或者人物特征,也可以通过指令修改参考图的局部。另外i p adapt adapt apt做做做动作人物一致性的关键工具。这不一直看完这个视频,你将会全面了解i p adapt的用法和区别。

这个视频将分成四个部分,第一部分,众多的i p adapt的区别分类以及使用方法。第二部分不同情况下怎么去调整权重达到最好的效果。第三部分i p adopt制作人物一致性动画案例。好嘞,我们马上开始这些i p adapt的模型加加买买总共有十几二十个,它甚至还有十来个域处理器。

面对这么多的模型我们应该怎么去选择,怎么去区分呢?首先i p adapt作为一种图案提示是为了。弥补文字提示的不足,或者是取代文字提示的。也就是说图像提示跟文字提示之间既有合作关系也有对抗关系。所谓合作关系,那么就是文字提示跟图像提示之间没有矛盾。

而所谓的对抗关系就是文字提示跟图像提示词不匹配的时候。例如说你给出的参考图是一个红色头发,而你的提示词写着蓝色头发,那就是有矛盾不匹配。而我们要考究的就是这两种关系下各个模型表现上的区别。所以我们先把s d叉l的i p adapt先给弄开先研究清楚s d一点五所有的适配器。

那么s d叉l也自然而然的我们就清楚了s d一点五的i p适配器总共能分成三种。第一种i p adapt s d一点五,一点五plus一点五line,这三个都是v的h一四图形编码器全图嵌入捕捉的是整体的特征,最基础的一个是s d一点五。当提示词跟图像匹配的时候,它表现非常的不错。除了它手上的。

动作和脸部有点不像之外,其他都没有什么问题。但是提示词跟图像不一致的时候,比如说我这里把它改成蓝色的头发跟跑步,那么权重等于零点五的时候,图像提示词的特征就会被忽略,深层的图就会变成蓝色的头发,但是你依然没有看到跑步的动作,所以整体结构还是保留了参考图的结构。而s d一点五light更适合文本提示,它对于使用文本作为提示的创作更加灵活。我们从这三个图就可以看得出来,图像提示甚至对整个结构都没有办法固定它,只有人像的大特征被保留了下来。

当你换到蓝色头发跟跑步的提示词的时候,权重低的几乎完全倾向于提示词了,参考图的特征几乎没有了。而s d一点五plus生成的图是最接近原始参考图的当采用plus的时候呢权重稍高一点,除了脸部不太像之外,人物的大特征结构几乎是一模一样的。我们换到蓝色头发跟跑步,我们的结构依然非常的稳定,动作也是追随参考图的,仅仅在权重比较低的时候出现了一些蓝色的头发。所以总结下来呢,对于提示值的强度来说,plus大于s d一点五大于light,plus更适合偏向参考图的要求,light更适合偏向提示词的需求,而是s d一点五适合在偏向参考图的基础上做一些细微的变化,前提是你需要调整一下权重。

第二种类型,s d一点五plus face和s d一点五for face。这两个呢也是weed h实时图形编码器。但是呢模型的权重是经过微调的,它是用裁剪后的脸部作为参考,因此深深的人物脸部会更加的像参考图。但是从效果来说,plus face和full face可以说是是分别的,都不算特别好。

所以在face i d面试之后,这两个模型就变得非常之鸡肋。那么第三种就是我们所说的face i d i p p adapt face i d使用的是人脸识别。模型中的人脸i d嵌入,并且使用nova模型来提高脸部的一致性。nova的权重大概是零点五到一点零都可以的。

那么呢基础的face i d效果是可以的,但是总体来说不算特别稳定,因为face i d缺少脸部结构的支持,我们更加常用的人脸识别版本是face i d plus。face i d plus呢是face i d的升级版。face i d plus模型除了采用face i d嵌入用于人脸i d识别之外,还用了clip图像嵌入用于人脸结构。所以你可以清楚的看到,face i d plus的人脸复刻比face i d要高一个水准。

而face i d plus v s plus的进化版除了改进的模型之外,还face脸调整和face i d的图重,也就是脸部结构的权重,但只能在face i d上面使用。另外face i d还有一个图像的模型,它跟face adapt face i d相同,但是它不需要使用va可以接受的一个s s s s s face i d s s s。事实上face i d跟face i d plus等。都可以不用rava,只不过使用rava会让它的效果更加的好。

那么总结下来呢,我们就有了这个表格,这个表格里面的模型下载地址我都会放在简介。当然这些信息量可能有点多,你一时半会可能记不住。没有关系,我准备了一份详细的笔记,今天的视频的内容都会整理在里面。那么三连加关注找我拿笔记。

那么接下来我们就可以讲一点有趣的应用。首先是权重的影响,不同的权重将引导至不同的结果。在没有其他提示词的情况下,权重可以直接取个一,权重越大越倾向于参考图片。当然我们可以补充文字提示,在图像提示的基础上增加元素或者替换元素。
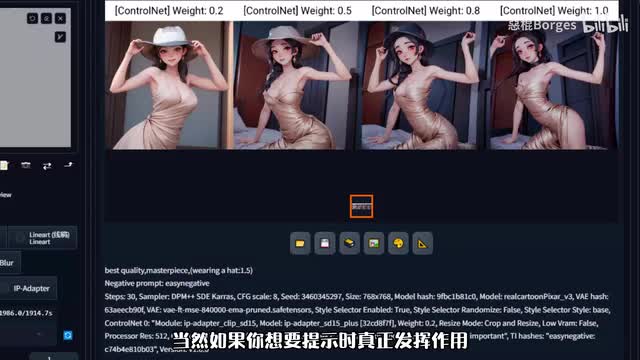
比如说这里我想给他戴个帽子,补充提示词wearing ahead。当然如果你想要提示词真正发挥作用,零点五到零点八的权重是比较理想的。选择权重大了帽子就没了。权重小了跟参考图就不像了。

这里的权重跟你的动作有很大的关系,你的动作大一点,那你的i p adapter的权重。就要小一点,如果你的动作小一点,i p adapter就可以大一点。而且i p adapter通常不会单独使用,一般都跟其他的control t共同引导。比如说跟soft edge模型共同引导,或者跟oper模型共同引导,或者跟open pose共同引导。
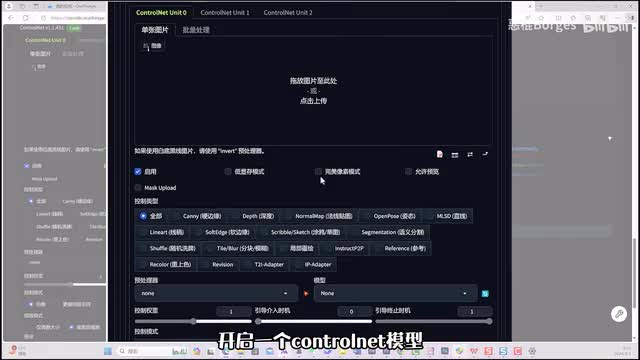
那么看到这里,既然i p adapt可以将图片的人物绑定到open pose上面,那么视频是不是也可以呢?操作十分简单,我们只不过是将预处理图的序列帧做成视频。先来到element def,我们选择v三模型,勾选m p四格式闭环,选择n在n m def加载视频之后,开启一个control net模型,选择open pose预处理器,选择无不插入任何图像。再打开一个control net导入白底的人像的这张图,选择i p adapt模型,选择plus版本,权重零点六到一点零就可以制作一次性人物动画了。选择i p adapt就暂时讲到了这里了。

那么如果。你想了解更加具体的操作,以及如何去更换它的背景,如何做高清修复的话,你可以去看这一期视频。本来按照计划呢,i p adapt我是打算跟reference一起讲的,但是因为i p adapt出现之后呢,reference变得稍微有点鸡肋,所以呢reference我就不打算在视频上面讲了。我会把它整理进笔记,你在笔记就可以看到十分之详细的内容。

另外的话从今天开始呢,我只发放最新视频的笔记了,实在是发不过来了。旧的视频的笔记我会陆续直接发布在专属动态里面。上一期视频的m a d f的笔记,由于视频发出之后,第二天那个软件就直接更新了个新的版本。没有关系,评论区留过言了,我很快会发给大家。




